5.5.5 特徴量選択
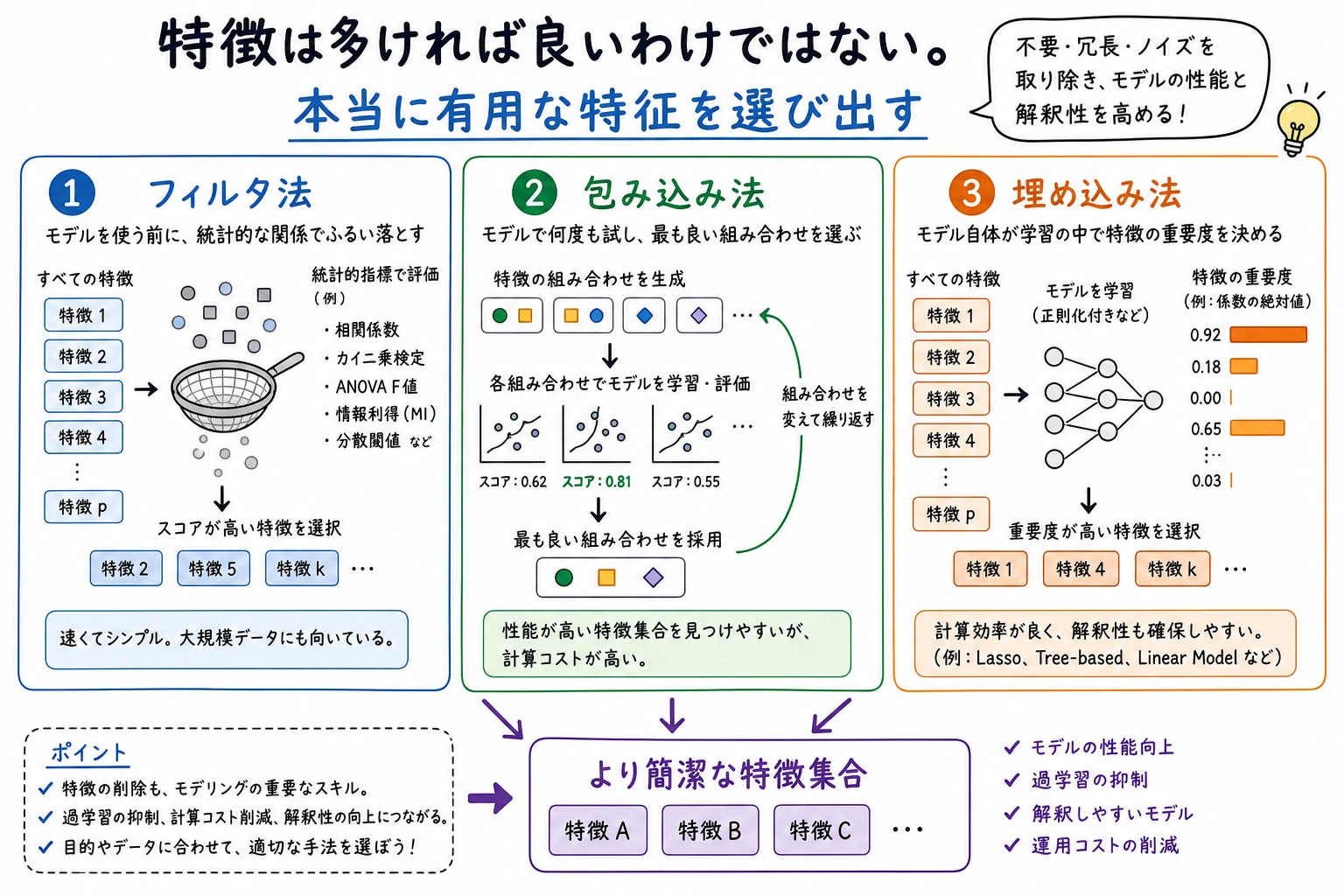
- 特徴量は多ければよいわけではない理由を理解する
- フィルタ法、ラッパー法、埋め込み法の基本を身につける
- 検証データと交差検証で、特徴量選択が本当に有効か判断する
- 特徴量選択と業務上の説明性、運用コストの関係を理解する
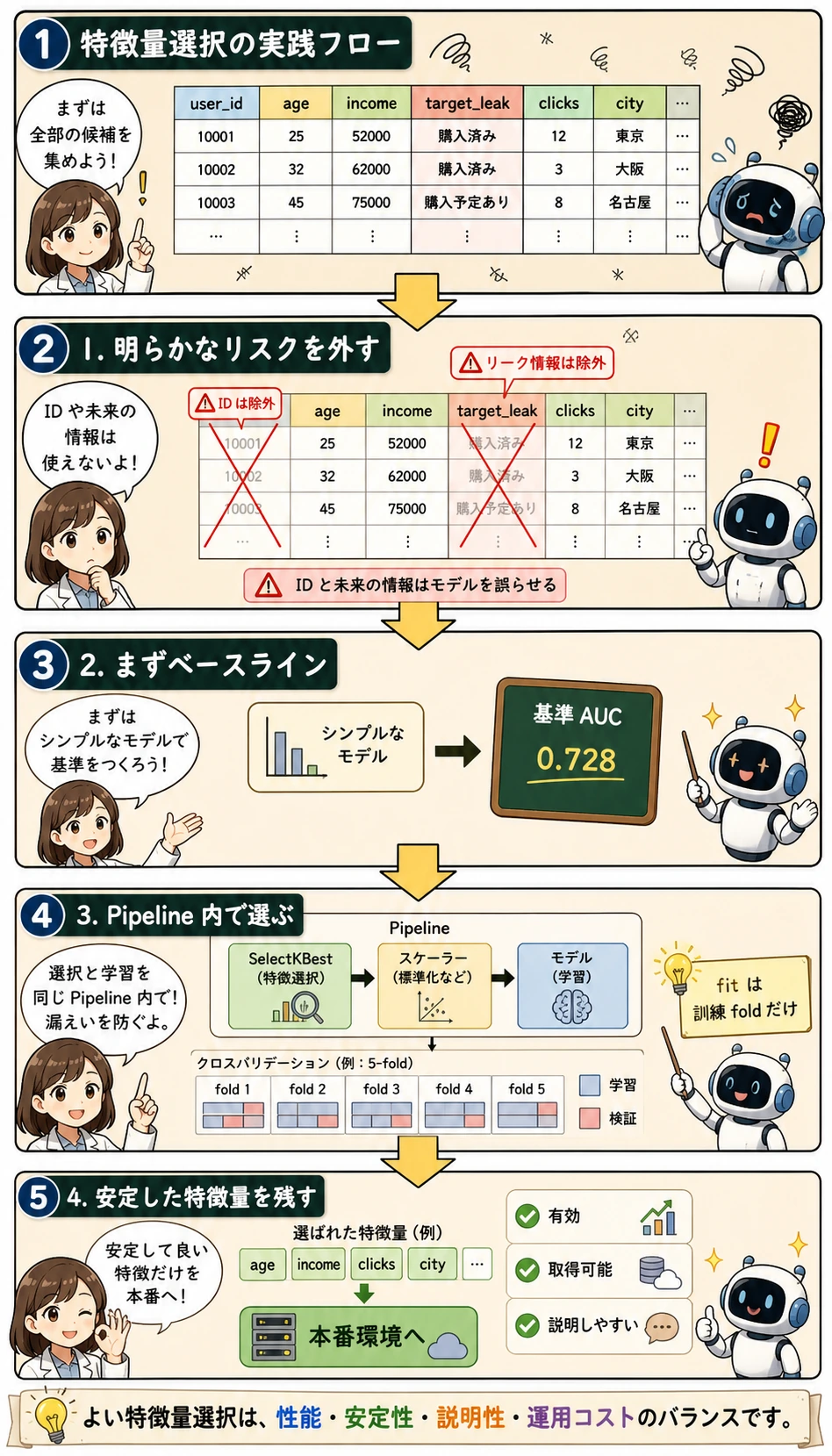
コードを見る前に、この図で流れをつかみましょう。特徴量選択は「表の列を小さくする作業」ではありません。まず明らかなリスクを外し、ベースラインを作り、選択器を Pipeline に入れ、最後に有効で取得可能で説明しやすい特徴量だけを残します。
なぜ特徴量選択が必要なのか
Section titled “なぜ特徴量選択が必要なのか”特徴量が多すぎると、ノイズが増え、学習が遅くなり、過学習しやすくなり、説明コストも上がります。実務では、1 つの特徴量が追加のデータソース、API、権限、保守ロジックを意味することもあります。
flowchart LR A["すべての特徴量"] --> B["明らかに不要・リークする特徴量を外す"] B --> C["ベースラインを作る"] C --> D["Pipeline 内で特徴量を選ぶ"] D --> E["検証性能を比較する"] E --> F["安定して使える特徴量を残す"]コードを書く前のキーワード整理
Section titled “コードを書く前のキーワード整理”| 用語 | 初学者向けの意味 | ここで重要な理由 |
|---|---|---|
| ID | user_id や order_id のような識別子 | モデルが一般的なパターンではなく行を暗記してしまうことがある |
| ターゲットリーク | 正解が起きた後でしか分からない情報が特徴量に入ること | 検証スコアが不自然に高くなる |
| ベースライン | 最初に作るシンプルな比較用モデル | これがないと改善したか判断できない |
| AUC | ROC 曲線下面積。分類でよく使う順位づけ指標 | 確率を出すモデルの特徴量セット比較に使いやすい |
| フィルタ法 | 統計スコアで先に特徴量を選ぶ方法 | 高速で、最初の絞り込みに向く |
| RFE | Recursive Feature Elimination。弱い特徴量を繰り返し外す方法 | モデル性能に近いが、計算は重め |
| 埋め込み法 | モデル学習の中で特徴量も選ぶ方法 | 係数や重要度を出せるモデルで使いやすい |
fit | 訓練データからルールを学ぶこと | 検証データやテストデータから学んではいけない |
transform | 学んだルールをデータに適用すること | 検証・テストの処理を訓練時とそろえる |
Pipeline | 前処理、特徴量選択、モデル学習をつなげた流れ | 交差検証でリークを防ぎやすい |
このページを終えたら、この evidence card を残します。
- 特徴状態
- 生の列、型、欠損値、スケール、およびターゲットとの関係
- 変換
- 前処理、構築、選択、またはパイプライン手順
- 出力
- transformされたfeature table、pipeline object、scoreの変化、または選択された特徴量
- 失敗確認
- リーク、不一致な train/test 変換、高カーディナリティの落とし穴、または無意味な特徴
- 期待される成果
- 前後比較とメトリクスへの影響を含む特徴量パイプラインの証拠
この節で使う共通セットアップ
Section titled “この節で使う共通セットアップ”以下の例は同じデータセットを使うので、上から順番に実行できます。乳がんデータセットは数値特徴量が多く、二値分類の目的変数を持つため、特徴量選択の練習に適しています。
import pandas as pdfrom sklearn.datasets import load_breast_cancerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import roc_auc_scorefrom sklearn.model_selection import StratifiedKFold, cross_val_score, train_test_splitfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import StandardScaler
cancer = load_breast_cancer(as_frame=True)X = cancer.datay = cancer.target
X_train, X_val, y_train, y_val = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
print("Dataset shape:", X.shape)print("Target names:", cancer.target_names.tolist())print("First 5 columns:", X.columns[:5].tolist())出力例:
- Dataset Shape
- (569, 30)
- Target Names
- ['malignant', 'benign']
- First 5 Columns
- ['mean radius', 'mean texture', 'mean perimeter', 'mean area', 'mean smoothness']
まずモデルに入れてはいけない特徴量を外す
Section titled “まずモデルに入れてはいけない特徴量を外す”最初のステップは高度なアルゴリズムではなく、手作業の確認です。まず優先して外すべきものは次の通りです。
user_id、order_id、transaction_idのような一意な ID- 目的変数の結果が出た後にしか存在しない項目
- 欠損率が非常に高く、業務上の意味も薄い項目
- 訓練時にはあるが、本番予測時に安定して取得できない項目
- 明らかに重複している項目
乳がんデータセットはきれいなため、ID やリーク項目は含まれていません。ただし実務データではよく出てきます。初学者には、モデリング前に「使わない列リスト」を明示的に作る習慣がおすすめです。
# 実務プロジェクトで使える書き方の例です。# このデータセットには該当列がないため、再利用できる習慣として示しています。risky_columns = ["user_id", "order_id", "target_leak"]available_risky_columns = [col for col in risky_columns if col in X_train.columns]
X_train_safe = X_train.drop(columns=available_risky_columns)X_val_safe = X_val.drop(columns=available_risky_columns)
print("Removed risky columns:", available_risky_columns)print("Remaining feature count:", X_train_safe.shape[1])ID が必ず無用とは限りませんが、初学者は慎重に扱うべきです。多くの ID は、モデルに訓練サンプルを暗記させ、未知データに使えるパターンを学ばせにくくします。
特徴量を選ぶ前にベースラインを作る
Section titled “特徴量を選ぶ前にベースラインを作る”さらに削ったり選んだりする前に、すべての安全な特徴量でモデルを作ります。これが以降の比較基準になります。
baseline_model = Pipeline([ ("scaler", StandardScaler()), ("clf", LogisticRegression(max_iter=5000, random_state=42)),])
baseline_model.fit(X_train_safe, y_train)baseline_auc = roc_auc_score( y_val, baseline_model.predict_proba(X_val_safe)[:, 1])
print(f"Baseline validation AUC: {baseline_auc:.4f}")後の特徴量選択で、少ない特徴量でも近い AUC が出るなら価値があります。モデルが軽くなり、速くなり、説明もしやすくなるからです。
フィルタ法:まず各特徴量と目的変数の統計的関係を見る
Section titled “フィルタ法:まず各特徴量と目的変数の統計的関係を見る”フィルタ法は最終モデルに依存しません。まず統計指標で特徴量を絞ります。数値特徴量なら ANOVA F 検定、カテゴリ特徴量ならカイ二乗検定、高次元の疎な特徴量なら分散フィルタなどが使われます。
from sklearn.feature_selection import SelectKBest, f_classif
filter_model = Pipeline([ ("selector", SelectKBest(score_func=f_classif, k=10)), ("scaler", StandardScaler()), ("clf", LogisticRegression(max_iter=5000, random_state=42)),])
filter_model.fit(X_train_safe, y_train)filter_auc = roc_auc_score( y_val, filter_model.predict_proba(X_val_safe)[:, 1])
selected_filter_cols = X_train_safe.columns[ filter_model.named_steps["selector"].get_support()].tolist()
print(f"Filter method validation AUC: {filter_auc:.4f}")print("Selected features:", selected_filter_cols)特徴量選択を公平に評価するには、全データで先に fit してはいけません。交差検証や Pipeline の中に入れ、各 fold の訓練部分だけで特徴量を選ぶ必要があります。
フィルタ法は速く、初期スクリーニングに向いています。ただし特徴量同士の相互作用を見落としやすいです。単独では弱い特徴量でも、別の特徴量と組み合わせると有効なことがあります。
ラッパー法:モデル性能を使って繰り返し試す
Section titled “ラッパー法:モデル性能を使って繰り返し試す”ラッパー法はモデルの性能を基準に特徴量を選びます。代表例が RFE、つまり Recursive Feature Elimination です。RFE はモデルを学習し、弱い特徴量を外し、それを繰り返して指定数の特徴量を残します。
from sklearn.feature_selection import RFE
rfe_model = Pipeline([ ("scaler", StandardScaler()), ("selector", RFE( estimator=LogisticRegression(max_iter=5000, solver="liblinear", random_state=42), n_features_to_select=10, )), ("clf", LogisticRegression(max_iter=5000, random_state=42)),])
rfe_model.fit(X_train_safe, y_train)rfe_auc = roc_auc_score( y_val, rfe_model.predict_proba(X_val_safe)[:, 1])
selected_rfe_cols = X_train_safe.columns[ rfe_model.named_steps["selector"].get_support()].tolist()
print(f"RFE validation AUC: {rfe_auc:.4f}")print("Selected features:", selected_rfe_cols)特徴量の数が多すぎず、よりモデル性能に近い選択をしたい場合、ラッパー法は有効です。ただし計算コストは高くなります。
埋め込み法:モデルに重要度を判断させる
Section titled “埋め込み法:モデルに重要度を判断させる”埋め込み法では、モデル学習の過程で特徴量も選びます。L1 正則化付き線形モデル、Random Forest、GBDT、XGBoost、LightGBM などで使える考え方です。
from sklearn.feature_selection import SelectFromModel
l1_model = Pipeline([ ("scaler", StandardScaler()), ("selector", SelectFromModel( LogisticRegression( solver="liblinear", l1_ratio=1, C=0.1, max_iter=5000, random_state=42, ) )), ("clf", LogisticRegression(max_iter=5000, random_state=42)),])
l1_model.fit(X_train_safe, y_train)l1_auc = roc_auc_score( y_val, l1_model.predict_proba(X_val_safe)[:, 1])
selected_l1_cols = X_train_safe.columns[ l1_model.named_steps["selector"].get_support()].tolist()
print(f"L1 embedded selection validation AUC: {l1_auc:.4f}")print(f"Selected feature count: {len(selected_l1_cols)}")print("Selected features:", selected_l1_cols)現在の sklearn では、l1_ratio=1 が純粋な L1 正則化を表します。C は正則化の強さを制御します。C が小さいほど正則化が強くなり、L1 モデルは一部の係数を 0 に近づけ、対応する特徴量を外しやすくなります。
特徴量重要度は絶対的な真実ではありません。モデル、乱数シード、データ分割によって順位は変わります。検証性能と業務理解を合わせて判断しましょう。
交差検証で本当に改善したか確認する
Section titled “交差検証で本当に改善したか確認する”特徴量選択でありがちな失敗は、「選ばれた特徴量がそれらしく見える」だけで、モデルが本当に安定したか確認しないことです。基準モデルと特徴量選択後のモデルを並べて比較しましょう。
experiments = { "all_features": baseline_model, "filter_top_10": filter_model, "rfe_top_10": rfe_model, "l1_embedded": l1_model,}
rows = []for name, pipe in experiments.items(): scores = cross_val_score(pipe, X_train_safe, y_train, cv=cv, scoring="roc_auc") rows.append({ "experiment": name, "mean_auc": scores.mean(), "std_auc": scores.std(), })
results = pd.DataFrame(rows).sort_values("mean_auc", ascending=False)print(results)少ない特徴量で近い性能が出て、学習が速く、説明しやすく、本番依存も少ないなら、その方がよい選択になることがあります。
最終的に何を残すか
Section titled “最終的に何を残すか”実務での特徴量選択はスコアだけでは判断しません。安定性、説明性、デプロイ可能性、コンプライアンス、費用対効果も見ます。AUC が 0.001 上がるだけの特徴量のために高価な外部データソースを接続するなら、採用しない方がよい場合もあります。
| 観点 | 残す判断の目安 |
|---|---|
| 性能 | 主指標を改善する、または少ない特徴量で安定したスコアを保てる |
| 安定性 | fold や期間が変わっても選ばれやすい |
| 取得可能性 | 予測時にその項目を取得できる |
| 説明性 | なぜ役立つか説明できる |
| コスト | データソースや保守コストに見合う |
初学者向けの安全な判断ルール
Section titled “初学者向けの安全な判断ルール”最初のプロジェクトでは、次の保守的な順番で進めると安全です。
- 明らかに危険な列を手動で外す
- 全特徴量のベースラインを残す
- まず
SelectKBestのような簡単な方法を 1 つ試す - 1 回の分割だけでなく交差検証で比較する
- 性能が同等以上で、特徴量の意味も説明できる場合だけ小さい特徴量セットを採用する
よくある間違い
Section titled “よくある間違い”1 つ目は、全データで特徴量選択をしてから訓練・テストに分けることです。これはリークになります。2 つ目は、特徴量重要度ランキングを盲信することです。3 つ目は、とにかく少ない特徴量を追求して未学習になることです。4 つ目は、本番で取得できるかを無視することです。訓練時に使える項目が、リアルタイム予測でも使えるとは限りません。
- 分類データセットで
SelectKBestを使い、上位 10 個の特徴量を選んでベースラインと比較する。 - RFE で 8、10、15 個の特徴量を選び、AUC と選ばれた特徴量名を比較する。
- L1 ロジスティック回帰で
C=0.01、C=0.1、C=1.0を試し、残る特徴量数の変化を見る。 - 訓練時には存在するが、本番予測時には安定して取得できない可能性がある特徴量を 3 つ挙げる。
- 特徴量選択を交差検証の外ではなく内部に入れるべき理由を説明する。
解法と解説
SelectKBestは、選択後のモデルが validation で baseline と同等以上のときに価値があります。特徴量が少ないだけで汎化性能が悪いなら改善ではありません。- RFE はスコアだけでなく、選ばれる特徴量の安定性も見ます。8、10、15 個で選択名が大きく変わるなら、ランキングは不安定です。
Cが小さいほど L1 正則化は強く、非ゼロ係数は少なくなりがちです。Cが大きいほど残る特徴量は増えます。- 本番で危ない特徴には、結果後に埋まる列、手動レビューラベル、未来の購入総額、予測時点では届かないログなどがあります。
- 交差検証の外で特徴選択すると validation 情報が漏れます。各 fold では、その fold の訓練データだけで特徴を選ぶ必要があります。
この節を終えたら、フィルタ法、ラッパー法、埋め込み法の違いを説明できるようになりましょう。さらに、検証データと交差検証で特徴量選択の有効性を判断し、データリークのリスクを見つけ、性能、説明性、コスト、本番での取得可能性から特徴量を残すか判断できることが目標です。