9.4.5 エピソード記憶と手続き記憶【選択】
- エピソード記憶と手続き記憶の違いを理解する
- この2種類の記憶が、なぜ複雑なタスクで特に重要なのかを理解する
- 実行できるサンプルを通して「経験から手順を抽出する」最小の流れを理解する
- ある情報を episode として保存すべきか ワークフロー として保存すべきかを判断できるようにする
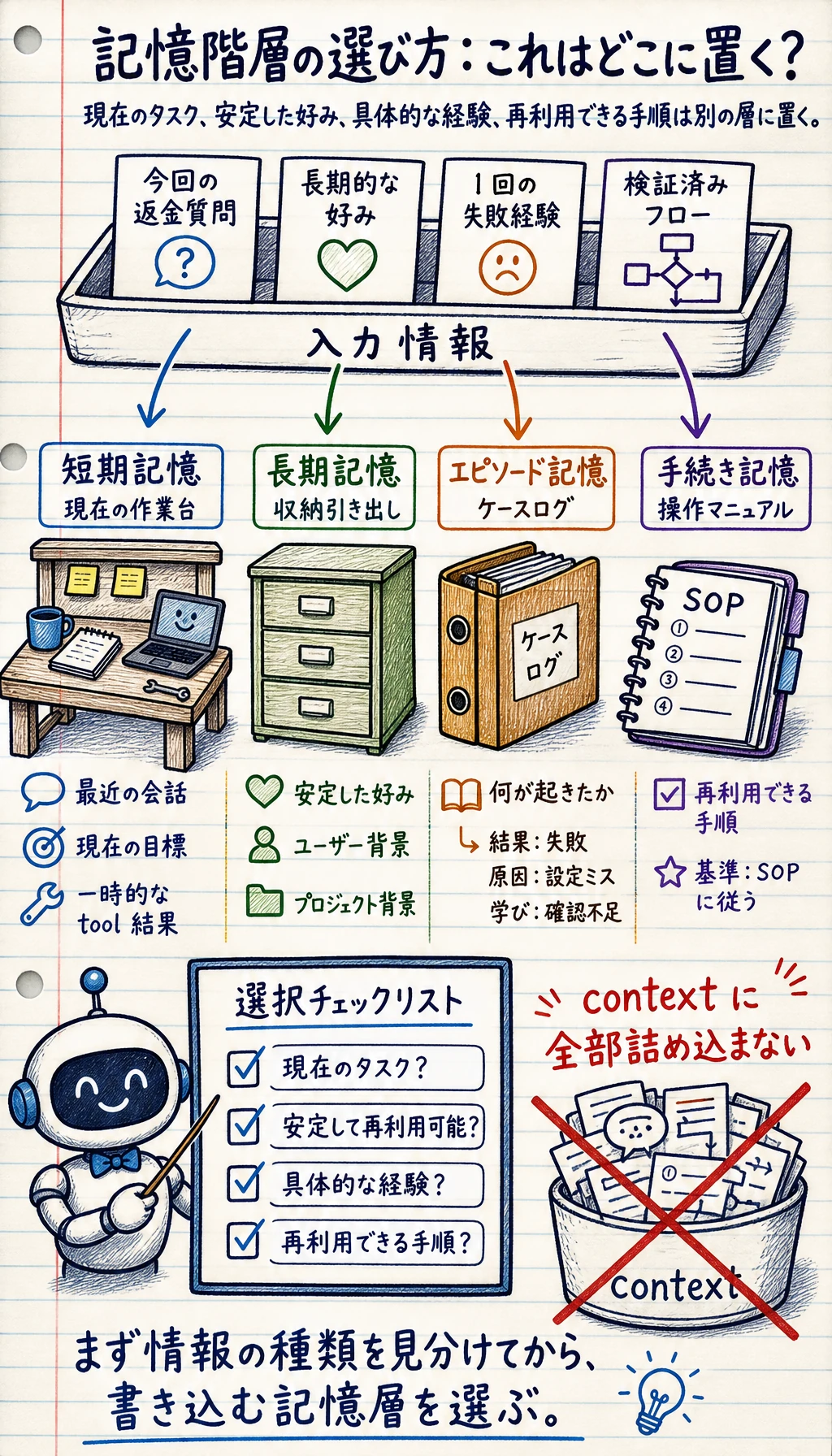
この図は判断の補助として使えます。短期状態は現在の実行を支え、長期記憶は安定した事実を保存し、エピソード記憶は具体的な経験を残し、手続き記憶は再利用できる方法を蓄積します。
エピソード記憶とは何か?
Section titled “エピソード記憶とは何か?”それは単発の経験に近い
Section titled “それは単発の経験に近い”例えば:
- 先週、学習進捗がしきい値を超えたことが原因で、返金の争いに対応した
- あるとき週報を生成したが、データベース API のタイムアウトでタスクが失敗した
この種の記憶の特徴は次の通りです。
- 時間と文脈がある
- 具体的な出来事の流れがある
- いつもそのまま再利用できるとは限らない
なぜ Agent にエピソード記憶が必要なのか?
Section titled “なぜ Agent にエピソード記憶が必要なのか?”複雑なシステムでは、過去に起きたことを参照する必要がよくあるからです。
- ユーザーは以前どんな問題を抱えていたか
- 前回似たタスクはどう終わったか
- どんな状況で失敗しやすいか
こうした情報は静的な記録ではありませんが、意思決定にはとても役立ちます。
手続き記憶とは何か?
Section titled “手続き記憶とは何か?”それはスキルや手順に近い
Section titled “それはスキルや手順に近い”例えば:
- 返金問題を処理するときは、まず注文を確認し、次にポリシーを確認し、最後に対象かどうかを判断する
- 競合分析レポートを作るときは、まずデータを集め、次に分類し、最後に要約する
この種の記憶で大事なのは「過去のどの1回か」ではなく、
「次に似たタスクが来たとき、このやり方を使い回せるか」です。
なぜ手続き記憶が重要なのか?
Section titled “なぜ手続き記憶が重要なのか?”Agent が毎回ゼロから計画するのを避けられるからです。
多くのタスクは、完全に新しい問題というよりも、
- 新しい実例 + 既存の手順
です。
このとき手続き記憶があれば、推論の負担をかなり減らせます。
2つの最大の違いは何か?
Section titled “2つの最大の違いは何か?”エピソード記憶は「何が起きたか」に答える
Section titled “エピソード記憶は「何が起きたか」に答える”例:
- 「前回週報を生成したとき、ログが多すぎて要約の質が下がった」
手続き記憶は「似た問題をどう処理するか」に答える
Section titled “手続き記憶は「似た問題をどう処理するか」に答える”例:
- 「週報生成の一般的な手順は、データ取得 -> クラスタリング -> 要約生成 -> レビュー」
たとえで言うと
Section titled “たとえで言うと”エピソード記憶はプロジェクトの振り返りのようなものです。
手続き記憶は SOP マニュアルのようなものです。
どちらも重要ですが、用途は違います。
まず「経験 -> 手順」のサンプルを動かしてみよう
Section titled “まず「経験 -> 手順」のサンプルを動かしてみよう”次の例では2つのことを行います。
- いくつかの具体的な episode を記録する
- episode から再利用可能な ワークフロー を抽出する
from dataclasses import dataclass
@dataclassclass Episode: task_type: str context: str steps: list result: str
episodes = [ Episode( task_type="refund_case", context="ユーザーが未発送の注文は返金できるかと質問した", steps=["注文状態を確認する", "返金ポリシーを確認する", "対象か判断する", "結論を返す"], result="success", ), Episode( task_type="refund_case", context="ユーザーが学習進捗が 20% を超えた場合に返金できるかと質問した", steps=["注文状態を確認する", "返金ポリシーを確認する", "対象か判断する", "結論を返す"], result="success", ), Episode( task_type="weekly_report", context="週報生成タスク", steps=["データを取得する", "問題をクラスタリングする", "要約を書く"], result="partial_failure", ),]
def build_procedural_memory(episodes, min_support=2): grouped = {} for episode in episodes: key = (episode.task_type, tuple(episode.steps)) grouped[key] = grouped.get(key, 0) + 1
workflows = {} for (task_type, steps), count in grouped.items(): if count >= min_support: workflows[task_type] = list(steps) return workflows
procedural_memory = build_procedural_memory(episodes)print("procedural_memory:", procedural_memory)想定出力:
procedural_memory: {'refund_case': ['注文状態を確認する', '返金ポリシーを確認する', '対象か判断する', '結論を返す']}このコードは何を示しているのか?
Section titled “このコードは何を示しているのか?”示しているのは次の点です。
- エピソード記憶には「実際にやったこと」が蓄積される
- それが何度か繰り返されると、手続き記憶として抽象化できる
つまり、手続き記憶は最初から書き出されることが多いのではなく、
繰り返し成功した episode から少しずつ形になるのです。
なぜ weekly_report は手続き記憶に入らなかったのか?
Section titled “なぜ weekly_report は手続き記憶に入らなかったのか?”1回しか出てきておらず、
十分な支持数がないからです。
これは現実にもよくあります。
- たまたま1回うまくいった、または失敗しただけでは、すぐに標準手順にするべきとは限らない
なぜこれが単に ワークフロー を手書きするより学びになるのか?
Section titled “なぜこれが単に ワークフロー を手書きするより学びになるのか?”とても現実的な知識の蓄積の流れを示しているからです。
- まずやる
- 次に振り返る
- 最後に手順へ抽象化する
これは、多くの成熟した Agent システムが進化していく道筋そのものです。
エピソード記憶はシステム内でどう使うのか?
Section titled “エピソード記憶はシステム内でどう使うのか?”似た事例を検索する
Section titled “似た事例を検索する”現在の問題に出会ったら、まず次を調べられます。
- 以前に似たケースがあったか
- そのときどう処理したか
- 最終的な結果はどうだったか
失敗を振り返る
Section titled “失敗を振り返る”ある種のタスクがよく失敗するなら、
エピソード記憶は次のような問いにとても向いています。
- どの段階でミスしやすいか
- どんな文脈で失敗が起きやすいか
手続き記憶の学習素材にする
Section titled “手続き記憶の学習素材にする”エピソード記憶そのものが、後で手順を抽象化するための元データにもなります。
手続き記憶はシステム内でどう使うのか?
Section titled “手続き記憶はシステム内でどう使うのか?”プランナーのデフォルトテンプレートとして使う
Section titled “プランナーのデフォルトテンプレートとして使う”タスクタイプを認識したら、システムはすぐに次を読み込めます。
- デフォルトのワークフロー
スキル庫として使う
Section titled “スキル庫として使う”手続き記憶は本質的に、次のようなものに近いです。
- 再利用可能なスキル
- 標準処理フロー
- タスクテンプレート
安全な境界として使う
Section titled “安全な境界として使う”手続き記憶には「勝手にやりすぎない」役割もあります。
たとえば高リスクなタスクでは、すでにレビュー済みの手順だけを使うようにできます。
いちばんつまずきやすいポイント
Section titled “いちばんつまずきやすいポイント”誤解1: すべての履歴をエピソード記憶と呼ぶ
Section titled “誤解1: すべての履歴をエピソード記憶と呼ぶ”すべての履歴を episode として残す必要はありません。
episode に向いているのは、次のような記録です。
- 明確なタスクがある
- 途中の流れがある
- 結果がある
誤解2: episode があると自動的に手続き記憶になる
Section titled “誤解2: episode があると自動的に手続き記憶になる”手続き記憶には、次の要素が必要です。
- 繰り返し
- 安定性
- 移植可能性
誤解3: 手続き記憶は一度決めたら更新しない
Section titled “誤解3: 手続き記憶は一度決めたら更新しない”流れが変わったら、手続き記憶も更新しなければなりません。
そうしないと、それは「経験」ではなく「古い経験」になってしまいます。
このページを終えたら、この証拠カードを残します。
- メモリ種別
- 短期、長期、エピソード記憶、または手続き記憶
- 書き込みルール
- メモリが作成または更新されるとき
- 取得ルール
- クエリ、関連性、鮮度、権限チェック
- 失敗確認
- 古い記憶、プライバシー漏えい、矛盾、または過剰検索
- クリーンアップ操作
- 要約、統合、期限切れ、削除、または確認を求める
この節で最も大事なのは、次の蓄積ロジックを持つことです。
エピソード記憶は具体的な経験を保存し、手続き記憶は何度も検証された経験を再利用可能な手順へ抽象化する。
この考え方が理解できると、
記憶システムは単なる「保管庫」ではなくなり、Agent の学習を本当に助けるものになります。
- サンプルに
weekly_reportの成功例を2つ追加して、それも手続き記憶として蓄積されるようにしてみましょう。 - どのタスクは episode を参照するのに向いていて、どのタスクはそのまま ワークフロー を使うのに向いているか考えてみましょう。
- なぜ手続き記憶は「履歴」ではなく「スキル庫」に近いと言えるのでしょうか?
- ある ワークフロー が古くなったら、どのように更新機構を設計しますか?
参考実装と解説
- 成功した
weekly_reportcases を追加すると、繰り返し現れる手順が見えるはずです。手順が安定したら procedural memory に昇格できます。 - context や過去の結果が重要なら episodes を確認します。タスクが繰り返し可能で最善の action sequence が分かっているなら procedural memory が向いています。
- procedural memory は単なる履歴ログではなく skill library に近いものです。再利用できる方法、判断点、チェック項目を保存するからです。
- workflow version、owner review、test cases、deprecation notes を使い、古い手順を安全に更新または廃止できるようにします。