3.5.5 データベース設計
- なぜ良いデータベース設計が必要なのかを理解する
- データベース正規化の核心をつかむ
- テーブル構造とリレーションの設計方法を学ぶ
- インデックスの役割と使うタイミングを理解する
まず地図を作ろう
Section titled “まず地図を作ろう”データベース設計は、「先にテーブルを分けて、次にテーブルをつなぎ、最後にインデックスを補う」と考えると理解しやすいです。
flowchart LR A["まず実体ごとにテーブルを分ける"] --> B["主キーと外部キーで関係をつなぐ"] B --> C["最後に検索にインデックスが必要か確認する"]この節で本当に解決したいのは、次のことです。
- なぜテーブルをむやみに1つにまとめてはいけないのか
- なぜ設計の問題が、最終的にデータ品質と検索効率の問題になるのか
なぜ設計が重要なのか?
Section titled “なぜ設計が重要なのか?”よくないデータベース設計は、次のような問題を引き起こします。
| 問題 | 結果 |
|---|---|
| データの重複 | 同じ情報を何度も保存するので、容量が無駄になり、修正時に複数箇所を直す必要がある |
| 更新異常 | ある場所だけ直して別の場所を直し忘れ、データが矛盾する |
| 挿入異常 | 新しい情報を追加したいだけなのに、存在しない関連データまで無理に作る必要がある |
| 削除異常 | 1件削除しただけなのに、ほかの必要な情報まで失う |
初学者向けのたとえ
Section titled “初学者向けのたとえ”データベース設計は、次のように考えるとわかりやすいです。
- 先に倉庫の棚をきちんと設計してから、物を入れる
最初から棚がぐちゃぐちゃだと、
- 同じ種類の物があちこちに置かれる
- 1つの物が何重にも存在する
- 取り出すときに見つけにくい
その結果、あとでの保守コストがどんどん高くなります。
データベース正規化
Section titled “データベース正規化”正規化(Normal Form)は、上のような問題を避けるための設計ルールです。まずは最初の3つの正規形の考え方を押さえましょう。
第1正規形(1NF):列は分割できない
Section titled “第1正規形(1NF):列は分割できない”ルール: 各フィールドには1つの値だけを入れます。リストやカンマ区切りの複数値は入れません。
1NF違反
| name | phones |
|---|---|
| 三郎 | 138xxxx, 139xxxx, 186xxxx |
問題:1つのフィールドに複数の電話番号が入っています。
1NFに適合
| name | phone |
|---|---|
| 三郎 | 138xxxx |
| 三郎 | 139xxxx |
| 三郎 | 186xxxx |
第2正規形(2NF):部分関数従属をなくす
Section titled “第2正規形(2NF):部分関数従属をなくす”ルール: 1NFを満たしたうえで、非主キー項目は主キー全体に完全に依存しなければなりません。主キーの一部だけに依存してはいけません。
2NF違反
- 複合主キー:
order_id + product_id。 - 例の行:
O1001、P01、Alex Chen、Wireless Mouse、2。 - 問題:
customer_nameはorder_idだけに依存し、product_nameはproduct_idだけに依存しています。
2NFに適合
| テーブル | 保存するもの |
|---|---|
customers | customer_id, customer_name |
orders | order_id, customer_id |
products | product_id, product_name |
order_items | order_id, product_id, quantity |
第3正規形(3NF):推移的従属をなくす
Section titled “第3正規形(3NF):推移的従属をなくす”ルール: 2NFを満たしたうえで、非主キー項目が別の非主キー項目に依存してはいけません。
3NF違反
- 従業員行:
employee_id=E01、name=Lee、dept_id=D01。 - 従業員行に入ってしまった部署情報:
dept_name=Sales、dept_manager=Wang。
問題:dept_name と dept_manager は employee_id ではなく dept_id に依存しています。
3NFに適合
| テーブル | 保存するもの |
|---|---|
employees | employee_id, name, dept_id |
departments | dept_id, dept_name, dept_manager |
正規化のまとめ
Section titled “正規化のまとめ”flowchart TD A["元データ(1つの大きなテーブル)"] --> B["1NF:列は分割できない"] B --> C["2NF:部分依存をなくす"] C --> D["3NF:推移的従属をなくす"]
B1["問題:1つのフィールドに複数の値が入っている"] -.-> B C1["問題:非キー項目が主キーの一部にだけ依存している"] -.-> C D1["問題:非キー項目が別の非キー項目に依存している"] -.-> D
style A fill:#ffebee,stroke:#c62828,color:#333 style D fill:#e8f5e9,stroke:#2e7d32,color:#333初学者がまず覚えやすい正規化の速習表
Section titled “初学者がまず覚えやすい正規化の速習表”| 正規形 | まず覚えるべき直感 |
|---|---|
| 1NF | 1つのマスに複数の値を入れない |
| 2NF | 非主キー項目は複合主キーの一部だけに依存しない |
| 3NF | 非主キー項目は別の非主キー項目を経由して依存しない |
この表は、抽象的な正規化を実用的な言葉に置き換えてくれるので、初心者にとても向いています。
実践:ECサイトのデータベースを設計する
Section titled “実践:ECサイトのデータベースを設計する”シンプルなECシステムでは、次の情報を管理する必要があります。
- ユーザー情報
- 商品情報
- 商品カテゴリ
- 注文と注文明細
ER図(実体関連図)
Section titled “ER図(実体関連図)”erDiagram users { int id PK text name text email text phone date created_at }
categories { int id PK text name text description }
products { int id PK text name real price int stock int category_id FK }
orders { int id PK int user_id FK real total_amount text status datetime created_at }
order_items { int id PK int order_id FK int product_id FK int quantity real unit_price }
users ||--o{ orders : "注文する" categories ||--o{ products : "含む" orders ||--|{ order_items : "含む" products ||--o{ order_items : "購入される"設計上の重要ポイント
Section titled “設計上の重要ポイント”なぜ注文は orders + order_items の2つのテーブルに分けるのか?
悪い設計1:大きな横長テーブル
- 形:
order_id、user_id、product1、qty1、product2、qty2、… - 問題:カートの商品数が増えるたびに列数が変わるため、1NFに違反します。
悪い設計2:注文情報の重複
- 1行目:注文
1、ユーザー佐藤太郎、合計8998、商品iPhone、数量1。 - 2行目:注文
1、ユーザー佐藤太郎、合計8998、商品AirPods、数量1。 - 問題:
order_id、user、totalが各明細行で繰り返され、2NFに近い更新ミスを生みます。
よりよい設計:責務を分ける
| テーブル | 主なフィールド |
|---|---|
orders | order_id, user_id, total_amount, status |
order_items | item_id, order_id, product_id, quantity, unit_price |
SQLiteで実装する
Section titled “SQLiteで実装する”import sqlite3
conn = sqlite3.connect(":memory:")cursor = conn.cursor()
# テーブルを作成cursor.executescript(""" CREATE TABLE categories ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL UNIQUE );
CREATE TABLE products ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL, price REAL NOT NULL CHECK(price > 0), stock INTEGER DEFAULT 0, category_id INTEGER, FOREIGN KEY (category_id) REFERENCES categories(id) );
CREATE TABLE users ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL, email TEXT UNIQUE, created_at TEXT DEFAULT CURRENT_TIMESTAMP );
CREATE TABLE orders ( id INTEGER PRIMARY KEY AUTOINCREMENT, user_id INTEGER NOT NULL, total_amount REAL DEFAULT 0, status TEXT DEFAULT 'pending', created_at TEXT DEFAULT CURRENT_TIMESTAMP, FOREIGN KEY (user_id) REFERENCES users(id) );
CREATE TABLE order_items ( id INTEGER PRIMARY KEY AUTOINCREMENT, order_id INTEGER NOT NULL, product_id INTEGER NOT NULL, quantity INTEGER NOT NULL CHECK(quantity > 0), unit_price REAL NOT NULL, FOREIGN KEY (order_id) REFERENCES orders(id), FOREIGN KEY (product_id) REFERENCES products(id) );""")
# サンプルデータを挿入cursor.executescript(""" INSERT INTO categories (name) VALUES ('スマートフォン'), ('アクセサリー'), ('パソコン');
INSERT INTO products (name, price, stock, category_id) VALUES ('iPhone 16', 7999, 100, 1), ('AirPods Pro', 1899, 200, 2), ('MacBook Pro', 14999, 50, 3), ('スマホケース', 39, 500, 2);
INSERT INTO users (name, email) VALUES ('佐藤太郎', '[email protected]'), ('鈴木花子', '[email protected]');
INSERT INTO orders (user_id, total_amount, status) VALUES (1, 9898, 'completed'), (2, 14999, 'shipped');
INSERT INTO order_items (order_id, product_id, quantity, unit_price) VALUES (1, 1, 1, 7999), (1, 2, 1, 1899), (2, 3, 1, 14999);""")
conn.commit()よく使う検索の例
Section titled “よく使う検索の例”import pandas as pd
# 各ユーザーの注文詳細を取得df = pd.read_sql_query(""" SELECT u.name AS ユーザー, o.id AS 注文番号, p.name AS 商品, oi.quantity AS 数量, oi.unit_price AS 単価, oi.quantity * oi.unit_price AS 小計, o.status AS ステータス FROM order_items oi JOIN orders o ON oi.order_id = o.id JOIN users u ON o.user_id = u.id JOIN products p ON oi.product_id = p.id""", conn)print(df)
# 各カテゴリの売上を集計df_category = pd.read_sql_query(""" SELECT c.name AS カテゴリ, COUNT(oi.id) AS 販売回数, SUM(oi.quantity * oi.unit_price) AS 総売上 FROM categories c LEFT JOIN products p ON c.id = p.category_id LEFT JOIN order_items oi ON p.id = oi.product_id GROUP BY c.id, c.name ORDER BY 総売上 DESC""", conn)print(df_category)インデックス(Index)
Section titled “インデックス(Index)”インデックスとは?
Section titled “インデックスとは?”インデックスは本の目次のようなものです。目次がなければ、目的の言葉を探すために本全体をめくる必要があります。目次があれば、該当ページにすぐたどり着けます。
| 場面 | インデックスなし | インデックスあり |
|---|---|---|
| 100万行から1件を探す | 全100万行を走査する | すぐに絞り込めるので、数ミリ秒で見つかる |
| 検索の仕組み | 1行ずつ比較する(フルテーブルスキャン) | B-Treeで検索する(対数時間) |
インデックスの作成と利用
Section titled “インデックスの作成と利用”-- email列にインデックスを作成(email検索を高速化)CREATE INDEX idx_users_email ON users(email);
-- order_date列にインデックスを作成CREATE INDEX idx_orders_date ON orders(created_at);
-- 複合インデックス(複数列)CREATE INDEX idx_items_order_product ON order_items(order_id, product_id);
-- テーブルのインデックスを確認-- SQLite: PRAGMA index_list('users');-- MySQL: SHOW INDEX FROM users;いつインデックスを付けるべき?
Section titled “いつインデックスを付けるべき?”| インデックスを付けるべき | インデックスが不要なことが多い |
|---|---|
| WHERE条件でよく使う列 | あまり検索に使わない列 |
| JOINで結合に使う列 | データ量が少ないテーブル(数百行程度) |
| ORDER BYでよく並べ替える列 | 更新が頻繁な列(インデックスも更新が必要) |
| 一意性が必要な列 | 重複率が高い列(例:性別) |
初学者向けのインデックス判断表
Section titled “初学者向けのインデックス判断表”| 場面 | まず考えること |
|---|---|
| ある列を WHERE でよく絞り込む | インデックスを検討する |
| ある列を JOIN でよく使う | インデックスを検討する |
| テーブルが小さい | まずは急いで付けなくてよい |
| 列の更新頻度がとても高い | インデックスはより慎重に考える |
この表は、「いつインデックスを作るべきか」を具体的な判断に変えてくれるので、初心者に向いています。
設計チェックリスト
Section titled “設計チェックリスト”データベースを設計するたびに、このチェックリストで確認しましょう。
- すべてのテーブルに主キーがあります。
- フィールド名がわかりやすく、命名ルールも統一されています。基本は
snake_caseが扱いやすいです。 - データ型がデータに合っています。たとえば件数は
INTEGER、単純な金額例はREAL。 - 必須フィールドに
NOT NULLを付けています。 - 一意にしたい項目に
UNIQUEを付けています。例:email。 - テーブル間の関係を外部キーで表しています。
- 3NFを満たしているか、非正規化の理由を説明できます。
- よく検索する列にインデックスを付けています。
-
status DEFAULT 'active'など、適切なデフォルト値があります。 - 必要な場所に
created_atで作成時刻を残しています。
このページを終えたら、この evidence card を残します。
- スキーマ
- テーブル名、キー、関係、サンプル行
- クエリ
- 使われた SQL または Python のデータベースコード
- 出力
- result rows、row count、または保存された抽出結果
- 失敗確認
- 間違った結合キー、危険なクエリ、トランザクション不足、またはスキーマ不一致
- 期待される成果
- クエリと結果表、および1件のデータ品質メモ
この節でいちばん持ち帰ってほしいこと
Section titled “この節でいちばん持ち帰ってほしいこと”- データベース設計で大事なのは、「見た目がきれいなテーブル」を作ることではなく、あとで保守しやすく、矛盾しにくい構造にすること
- 正規化は、重複や異常を減らすための考え方であって、単なる理論暗記ではない
- インデックスは多ければよいわけではなく、実際の検索場面に合わせて使うことが大事
root(("データベース設計")) 正規化 1NF 列は分割できない 2NF 部分依存をなくす 3NF 推移的従属をなくす 非正規化 適度な冗長性 テーブル設計 主キー すべてのテーブルに必要 外部キー 他テーブルとの関連付け 制約 データ品質を守る 命名 わかりやすく統一する インデックス 検索を高速化する WHERE の列 JOIN の列 付けすぎない 実践 ER図を先に描く 大きな広いテーブルより分割 意図して使い分ける| 原則 | 説明 |
|---|---|
| まず ER 図を描く | テーブルを作る前に、実体と関係を整理する |
| 正規化を守る | 重複と異常を減らす |
| 適度に非正規化する | 冗長性を使って性能を上げる |
| インデックスを活用する | 重要な検索を速くする |
| 設計してから実装する | データベース構造の変更は、コード変更よりずっと大変 |
手を動かしてみよう
Section titled “手を動かしてみよう”練習1:正規化の問題を見つける
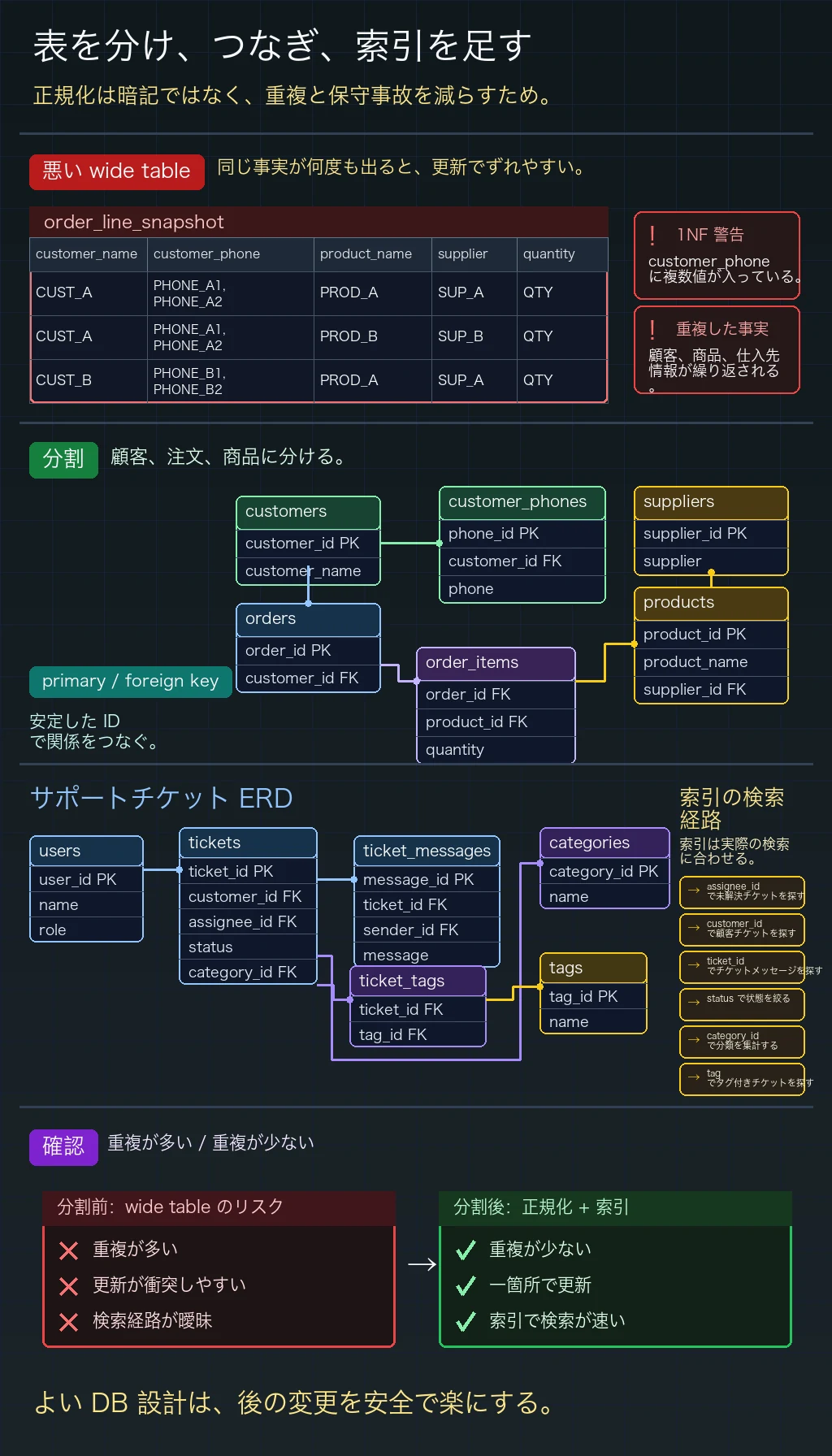
Section titled “練習1:正規化の問題を見つける”次のテーブル設計にはどんな問題がありますか?どの正規形に違反していますか?どう直しますか?
テーブル:order_line_snapshot
- 1行目:注文
O1001、顧客Alex Chen、電話555-0101, 555-0199、商品P01 Wireless Mouse、仕入先GearCo、数量2。 - 2行目:注文
O1001、顧客Alex Chen、電話555-0101, 555-0199、商品P02 Keyboard、仕入先KeyLabs、数量1。 - 3行目:注文
O1002、顧客Mia Wong、電話555-0188、商品P01 Wireless Mouse、仕入先GearCo、数量1。
練習2:カスタマーサポートのチケットシステムを設計する
Section titled “練習2:カスタマーサポートのチケットシステムを設計する”次の要件を満たす、シンプルなカスタマーサポートシステムのデータベースを設計してください。
- 顧客アカウントとサポート担当者アカウント
- サポートチケットの作成(タイトル、説明、状態、優先度)
- 顧客と担当者によるチケット内メッセージ
- チケットのカテゴリとタグ(1つのチケットに複数のタグを付けられる)
要件:
- ER図を描く(紙とペンでも Mermaid でもよい)
- CREATE TABLE 文を書く
- どの列にインデックスを付けるべきか考える
練習3:実装して検索してみる
Section titled “練習3:実装して検索してみる”# SQLite で練習2の設計を実装する# サンプルデータを挿入する# 次の検索を完成させる:# 1. 特定の担当者に割り当てられた open 状態のチケットをすべて検索する# 2. 特定チケットのすべてのメッセージを検索する(送信者名を含む)# 3. 状態またはカテゴリごとのチケット数を検索する# 4. "refund" タグが付いたすべてのチケットを検索する参考実装と解説
- 正規化の練習では、顧客、顧客電話番号、注文、商品、仕入先、注文明細を分けます。カンマ区切りの電話番号は 1NF に反し、顧客情報や商品情報を注文明細に繰り返すと部分依存と更新ミスが起きます。
- チケットシステムの schema では、典型的に users、tickets、ticket_messages、categories、tags、
ticket_tags結合テーブルを用意します。外部キーは顧客の所有、担当者の割り当て、チケットとメッセージの関係を明確に表します。 - よく検索や join に使う
assignee_id、customer_id、ticket_id、status、category_id、タグ名などには index を検討します。ただし盲目的に追加せず、各 index が想定クエリを支えるようにします。