7.4.5 GPU を借りて手作り GPT-2 を学習する
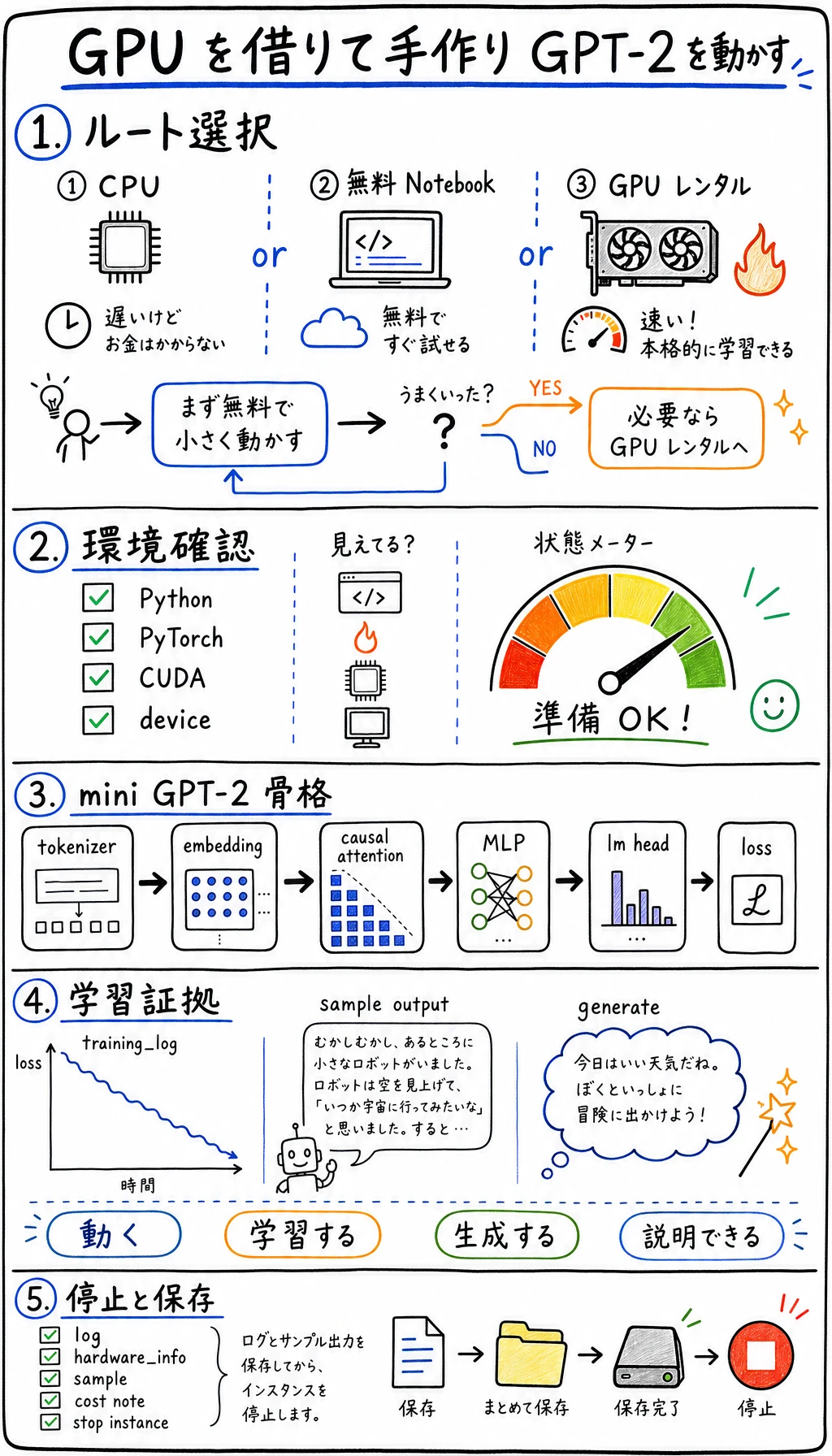
- 無料 Notebook と低価格 GPU の使い分けを判断できる。
- Python、PyTorch、CUDA が使える学習環境を作れる。
- 単一ファイルの mini GPT-2 学習スクリプトを GPU で実行できる。
- embedding、causal self-attention、MLP、loss、checkpoint、generate を説明できる。
- 学習ログ、ハードウェア情報、checkpoint path、生成サンプル、停止証拠を保存できる。
1. まず GPU 方案を選ぶ
Section titled “1. まず GPU 方案を選ぶ”最初から大きな GPU を追わないでください。授業では、全員が完走できることを優先します。
| 方案 | 向いている人 | 推奨用途 | 注意点 |
|---|---|---|---|
| Kaggle Notebook | 無料優先の公開授業 | GPU を有効にして mini GPT-2 を動かす | 配額は変動し、GPU は保証されない |
| Colab 無料版 | 素早い試走 | コードとログを確認する | GPU 型番と利用時間は安定しない |
| Lightning AI 無料枠 | クラウド開発環境に近い体験 | プロジェクト保存と反復実験 | 無料 credit は使い切る可能性がある |
| AutoDL / RunPod | 1-3 時間の安定した実験 | RTX 4090、L4、A10、A5000 を借りる | 終了後に停止と削除を確認する |
| A100 / H100 | 大規模事前学習コストの理解 | デモまたは上級課題のみ | 必修として全員に要求しない |
この節の推奨構成
Section titled “この節の推奨構成”| 目標 | 最低構成 | 余裕のある構成 |
|---|---|---|
| smoke test | CPU または無料 Notebook | PyTorch を import できる任意の環境 |
| この節の合格 | visible CUDA GPU、例:T4 | T4、L4、A10、4090、A5000 |
| loss の低下を見る | 無料 T4 で 300-800 step | 4090、A5000 で 1000-3000 step |
| 少し大きいモデルを試す | 16GB VRAM | 24GB VRAM |
デフォルトのスクリプトは小さいため CPU でも training loop には入れます。ただし CPU 完走は preflight です。この節の正式合格には、device: cuda が出る log が少なくとも1つ必要です。この要件により、environment check、GPU memory discipline、logs、checkpoint、evidence copy-back、shutdown までを実際に経験できます。
2. 課金前チェックリスト
Section titled “2. 課金前チェックリスト”有料マシンを起動する前に、4つ確認します。
- 予算:この実験で使う上限額を決める。
- マシン:16GB または 24GB VRAM を優先し、最上位カードは不要。
- イメージ:PyTorch イメージを選び、できれば CUDA 入りを使う。
- 終了方法:課金停止とインスタンス削除の場所を把握する。
よくあるルート:
無料ルート:Kaggle / Colab -> GPU を有効化 -> script を作成または upload -> 実行中国向け低価格ルート:AutoDL -> PyTorch image -> Jupyter または SSH -> 実行国際低価格ルート:RunPod -> PyTorch template -> terminal -> 実行コスト管理:まず CPU または無料 Notebook で短い smoke test を行い、その後 GPU で正式実行します。import、file path、CUDA image の問題で課金を浪費しないようにします。
3. 環境を開き PyTorch を確認する
Section titled “3. 環境を開き PyTorch を確認する”Notebook または remote terminal で実行します。
python -Vpython - <<'PY'import torchprint("torch:", torch.__version__)print("cuda available:", torch.cuda.is_available())print("device:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "cpu")PY期待される出力:
torch: 2.x.xcuda available: Truedevice: Tesla T4cuda available: False の場合は、まだ学習を始めないでください。Notebook の GPU が有効か、CUDA 版 PyTorch image を使っているか確認します。
4. 単一ファイルスクリプトを作る
Section titled “4. 単一ファイルスクリプトを作る”mini_gpt2_train.py を作ります。最初は下のコードをそのままコピーし、成功するまでパラメータを変えないでください。
import mathimport timefrom dataclasses import dataclass
import torchimport torch.nn as nnimport torch.nn.functional as F
text = """To build a language model, we ask it to predict the next token.The model reads previous tokens, mixes context with attention, and produces logits.Small experiments teach the same training loop as large models."""
chars = sorted(set(text))stoi = {ch: i for i, ch in enumerate(chars)}itos = {i: ch for ch, i in stoi.items()}data = torch.tensor([stoi[ch] for ch in text], dtype=torch.long)
def decode(ids): return "".join(itos[int(i)] for i in ids)
def get_batch(batch_size, block_size, device): max_start = len(data) - block_size - 1 starts = torch.randint(0, max_start, (batch_size,)) x = torch.stack([data[i : i + block_size] for i in starts]).to(device) y = torch.stack([data[i + 1 : i + block_size + 1] for i in starts]).to(device) return x, y
@dataclassclass GPTConfig: vocab_size: int block_size: int = 64 n_layer: int = 2 n_head: int = 2 n_embd: int = 64 dropout: float = 0.1
class CausalSelfAttention(nn.Module): def __init__(self, config): super().__init__() assert config.n_embd % config.n_head == 0 self.n_head = config.n_head self.head_size = config.n_embd // config.n_head self.qkv = nn.Linear(config.n_embd, 3 * config.n_embd) self.proj = nn.Linear(config.n_embd, config.n_embd) self.dropout = nn.Dropout(config.dropout) mask = torch.tril(torch.ones(config.block_size, config.block_size)) self.register_buffer("mask", mask.view(1, 1, config.block_size, config.block_size))
def forward(self, x): B, T, C = x.shape q, k, v = self.qkv(x).split(C, dim=2) q = q.view(B, T, self.n_head, self.head_size).transpose(1, 2) k = k.view(B, T, self.n_head, self.head_size).transpose(1, 2) v = v.view(B, T, self.n_head, self.head_size).transpose(1, 2)
scores = q @ k.transpose(-2, -1) / math.sqrt(self.head_size) scores = scores.masked_fill(self.mask[:, :, :T, :T] == 0, float("-inf")) weights = F.softmax(scores, dim=-1) weights = self.dropout(weights) out = weights @ v out = out.transpose(1, 2).contiguous().view(B, T, C) return self.proj(out)
class Block(nn.Module): def __init__(self, config): super().__init__() self.ln1 = nn.LayerNorm(config.n_embd) self.attn = CausalSelfAttention(config) self.ln2 = nn.LayerNorm(config.n_embd) self.mlp = nn.Sequential( nn.Linear(config.n_embd, 4 * config.n_embd), nn.GELU(), nn.Linear(4 * config.n_embd, config.n_embd), nn.Dropout(config.dropout), )
def forward(self, x): x = x + self.attn(self.ln1(x)) x = x + self.mlp(self.ln2(x)) return x
class MiniGPT(nn.Module): def __init__(self, config): super().__init__() self.config = config self.token_emb = nn.Embedding(config.vocab_size, config.n_embd) self.pos_emb = nn.Embedding(config.block_size, config.n_embd) self.blocks = nn.ModuleList([Block(config) for _ in range(config.n_layer)]) self.ln_f = nn.LayerNorm(config.n_embd) self.lm_head = nn.Linear(config.n_embd, config.vocab_size)
def forward(self, idx, targets=None): B, T = idx.shape positions = torch.arange(T, device=idx.device) x = self.token_emb(idx) + self.pos_emb(positions) for block in self.blocks: x = block(x) x = self.ln_f(x) logits = self.lm_head(x)
loss = None if targets is not None: loss = F.cross_entropy(logits.view(B * T, -1), targets.view(B * T)) return logits, loss
@torch.no_grad() def generate(self, idx, max_new_tokens): for _ in range(max_new_tokens): idx_cond = idx[:, -self.config.block_size :] logits, _ = self(idx_cond) logits = logits[:, -1, :] probs = F.softmax(logits, dim=-1) next_id = torch.multinomial(probs, num_samples=1) idx = torch.cat([idx, next_id], dim=1) return idx
def main(): device = "cuda" if torch.cuda.is_available() else "cpu" torch.manual_seed(42)
config = GPTConfig(vocab_size=len(chars)) model = MiniGPT(config).to(device) optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)
steps = 500 if device == "cuda" else 120 batch_size = 64 if device == "cuda" else 16 print("device:", device) print("cuda_name:", torch.cuda.get_device_name(0) if device == "cuda" else "not available") print("parameters:", sum(p.numel() for p in model.parameters()))
start_time = time.time() for step in range(1, steps + 1): x, y = get_batch(batch_size, config.block_size, device) logits, loss = model(x, y) optimizer.zero_grad(set_to_none=True) loss.backward() optimizer.step()
if step == 1 or step % 50 == 0: elapsed = time.time() - start_time print(f"step {step:04d} | loss {loss.item():.4f} | elapsed {elapsed:.1f}s")
checkpoint = { "model_state": model.state_dict(), "config": config.__dict__, "stoi": stoi, "itos": itos, } torch.save(checkpoint, "mini_gpt2_checkpoint.pt") print("checkpoint: mini_gpt2_checkpoint.pt")
prompt = torch.tensor([[stoi["T"]]], dtype=torch.long, device=device) generated = model.generate(prompt, max_new_tokens=180)[0].cpu() print("\n--- sample ---") print(decode(generated))
if __name__ == "__main__": main()実行:
python mini_gpt2_train.py | tee gpu_train_log.txt期待される出力:
device: cudacuda_name: Tesla T4parameters: about 100kstep 0001 | loss 3.5832 | elapsed 0.2sstep 0050 | loss 3.1120 | elapsed 1.6s...checkpoint: mini_gpt2_checkpoint.pt--- sample ---To build a language model...生成文は自然でなくてもかまいません。GPU log で loss が下がり、checkpoint が保存され、文字が生成されれば、学習ループは動いています。
5. コードを順に読む
Section titled “5. コードを順に読む”テキストと tokenizer
Section titled “テキストと tokenizer”chars = sorted(set(text))stoi = {ch: i for i, ch in enumerate(chars)}itos = {i: ch for ch, i in stoi.items()}data = torch.tensor([stoi[ch] for ch in text], dtype=torch.long)これは文字単位 tokenizer です。本物の GPT-2 は BPE を使いますが、授業では依存を減らし、モデル構造に集中します。
next-token batch
Section titled “next-token batch”x = data[i : i + block_size]y = data[i + 1 : i + block_size + 1]x は入力、y は答えです。モデルは token 0 から T-1 を読み、token 1 から T を予測します。
Config
Section titled “Config”class GPTConfig: vocab_size: int block_size: int = 64 n_layer: int = 2 n_head: int = 2 n_embd: int = 64これらは、文脈長、block 数、attention head 数、embedding 幅を決めます。
QKV と multi-head attention
Section titled “QKV と multi-head attention”q, k, v = self.qkv(x).split(C, dim=2)q = q.view(B, T, self.n_head, self.head_size).transpose(1, 2)x の形は [B, T, C] です。分割と reshape のあと、各 head は [B, head, T, head_size] の形で文脈を見ます。
Causal mask
Section titled “Causal mask”mask = torch.tril(torch.ones(config.block_size, config.block_size))scores = scores.masked_fill(self.mask[:, :, :T, :T] == 0, float("-inf"))下三角 mask により、各位置は未来の token を見られません。これが decoder-only モデルの next-token prediction の基本ルールです。
Transformer block
Section titled “Transformer block”x = x + self.attn(self.ln1(x))x = x + self.mlp(self.ln2(x))attention は文脈を混ぜ、MLP は各位置の表現を変換します。残差接続により情報と勾配が流れやすくなります。
Embedding
Section titled “Embedding”x = self.token_emb(idx) + self.pos_emb(positions)token embedding は「何の token か」を表し、position embedding は「どの位置か」を表します。
Logits と loss
Section titled “Logits と loss”logits = self.lm_head(x)loss = F.cross_entropy(logits.view(B * T, -1), targets.view(B * T))logits の形は [B, T, vocab_size] です。cross entropy は、正しい次 token に高い確率を置くようにモデルを学習させます。
Training loop
Section titled “Training loop”logits, loss = model(x, y)optimizer.zero_grad(set_to_none=True)loss.backward()optimizer.step()この4行が基本です。forward、勾配のクリア、backpropagation、パラメータ更新です。
Checkpoint
Section titled “Checkpoint”torch.save(checkpoint, "mini_gpt2_checkpoint.pt")実際の training run では、復元できる成果物を残します。この小さな checkpoint は製品モデルとして重要ではありませんが、terminal text だけでなく学習済み weights ができたことを証明します。
Generate
Section titled “Generate”logits = logits[:, -1, :]probs = F.softmax(logits, dim=-1)next_id = torch.multinomial(probs, num_samples=1)生成では最後の位置の分布を見て、次 token をサンプルし、それを入力末尾に追加して繰り返します。
6. GPU training runbook
Section titled “6. GPU training runbook”Kaggle または Colab
Section titled “Kaggle または Colab”- Notebook を作る。
- 設定で GPU を有効にする。
- PyTorch 確認コードを実行し、
cuda available: Trueを確認する。 mini_gpt2_train.pyを作る。python mini_gpt2_train.py | tee gpu_train_log.txtを実行する。gpu_train_log.txtとmini_gpt2_checkpoint.ptを download または copy back する。- ハードウェア情報、loss 行、checkpoint 行、生成サンプルを保存する。
AutoDL または RunPod
Section titled “AutoDL または RunPod”- PyTorch image を選ぶ。
- 16GB または 24GB VRAM のマシンを選ぶ。
- JupyterLab または SSH terminal を開く。
- PyTorch 確認コードを実行する。
- script を保存して学習する。
gpu_train_log.txtとmini_gpt2_checkpoint.ptを持ち帰る。- 終了後すぐに instance を停止し、課金停止を確認する。
CPU smoke test は最終合格ではない
Section titled “CPU smoke test は最終合格ではない”CPU は file existence、imports、training loop の入口を確認するには有用です。しかし、この lab の最終合格ではありません。証拠が device: cpu だけなら、「smoke test complete, GPU run pending」と記録します。
よくある問題
Section titled “よくある問題”| 現象 | 可能な原因 | 対処 |
|---|---|---|
cuda available: False | GPU が無効、または image が違う | accelerator を有効化、または CUDA/PyTorch image を使う |
CUDA out of memory | batch、文脈長、モデルが大きすぎる | batch_size、次に block_size または n_embd を下げる |
| loss が下がらない | step が少ない、データが短い、LR が合わない | まず 500 step 走らせて傾向を見る |
| 生成文が乱れる | モデルとデータが小さい | この実験では正常。目的は仕組みを通すこと |
| 課金が続く | instance が動いたまま | instance を停止し、console で確認する |
このページを終えたら、この証拠カードを残します。
- プラットフォーム選択
- Kaggle/Colab/Lightning/AutoDL/RunPod
- ハードウェア情報
- torch version、CUDA 状態、GPU 型番
- 学習ログ
- device cuda と、step、loss、elapsed を含む少なくとも3行
- Checkpoint
- mini_gpt2_checkpoint.pt を保存または持ち帰る
- コード位置
- embedding、attention、loss、checkpoint、generate の位置を説明
- コスト記録
- 借りた場合は実行時間と費用を記録し、停止を確認
GPU 上で device: cuda の mini_gpt2_train.py run を完了し、gpu_train_log.txt と mini_gpt2_checkpoint.pt を保存し、入力 token が embedding、attention、MLP、lm head、checkpoint、cross entropy を通って次 token 予測を学ぶ流れを説明できれば合格です。CPU run は完走しても smoke test としてだけ扱います。
確認の考え方と解説
- 美しい生成文は不要です。目的は全体経路を動かすことです。
- 合格ログには、
device: cuda、ハードウェア情報、パラメータ数、複数の loss 行、checkpoint path、生成サンプルが含まれます。 - GPU を借りた場合、証拠には instance を停止したことを必ず書きます。
- CPU 完走は有用ですが、この節の最終合格ではありません。