13.1 計算ルート:ローカル CPU、無料 Colab、レンタル GPU
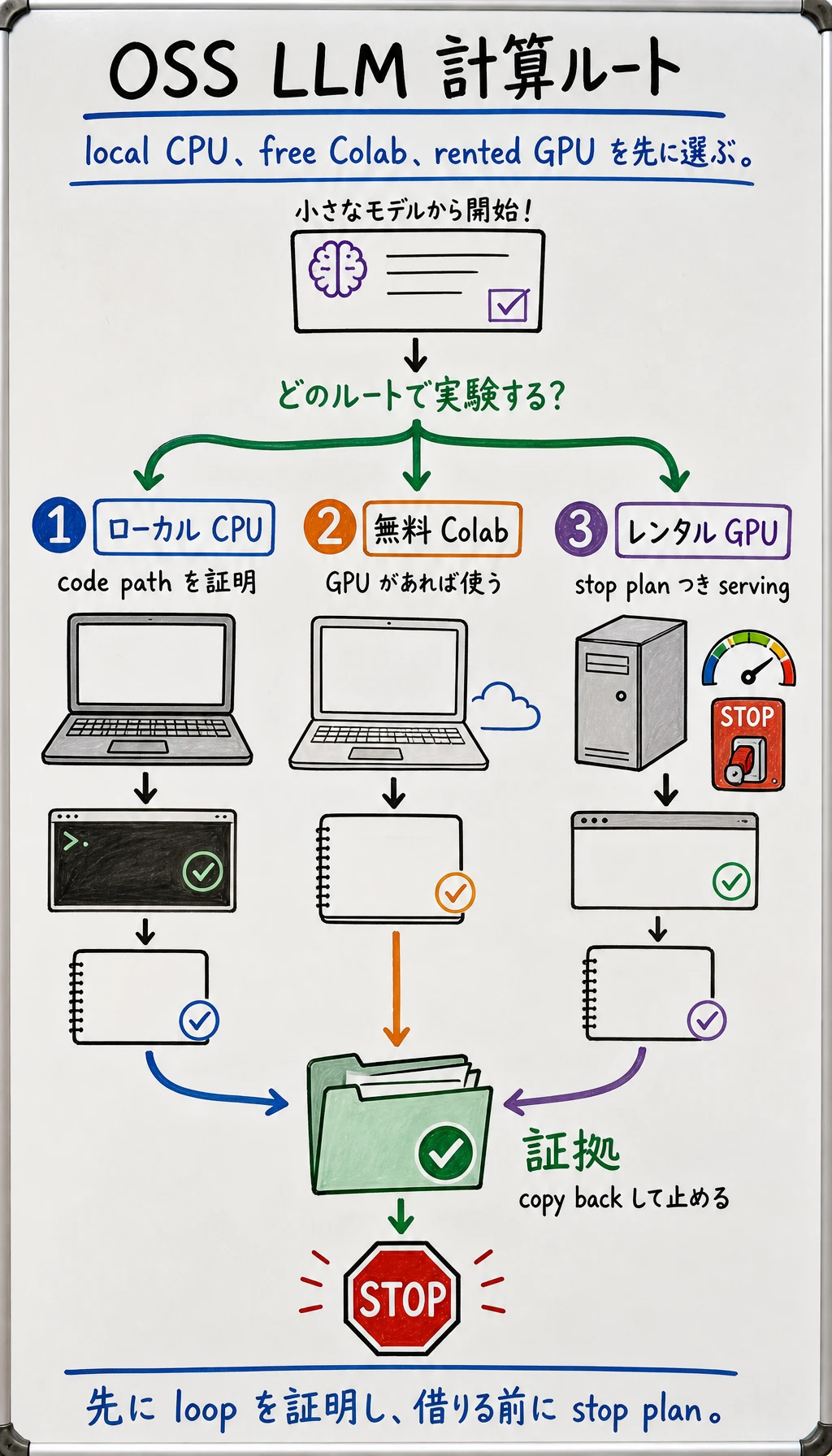
モデル名を選ぶ前に、実験をどこで動かすかを決めます。よい計算ルートは、今日何を証明できるか、何を待つべきか、どの証拠を残すか、そしてコストや複雑さが広がる前にどう止めるかを明確にします。
このページでは 3 つのルートを扱います。
- ローカル CPU:最も安全な最初のループ。レンタルなしでコードと証拠を確認する。
- 無料 Colab:無料 GPU が使えるときに便利。ただし常に保証されるものではない。
- レンタル GPU:vLLM 形式の serving や 7B 級モデルの検証に向く。ただし stop plan が必須。
ローカル CPU
- 使う場面
- 自分のマシンで安全に最初の実行をしたい。
- 最初の目標
sshleifer/tiny-gpt2、量子化小モデル、評価 script、local API skeleton。- 向かないこと
- 7B 品質、高スループット、長い context serving の証明。
- 残す証拠
environment_report.txt、first_run.md、eval_results.csv。
無料 Colab
- 使う場面
- 一時的な notebook と、使える場合の GPU がほしい。
- 最初の目標
- 小型 instruct model、tokenizer check、短い評価、小型 LoRA dry run。
- 向かないこと
- private data、長時間 job、公開 service、GPU 保証つき計画。
- 残す証拠
- notebook copy、runtime type、
nvidia-smiまたは CPU note、保存 output。
レンタル GPU
- 使う場面
- 予測できる VRAM、SSH、serving、7B 級 test が必要。
- 最初の目標
- vLLM/SGLang server、固定 eval set、latency と memory check。
- 向かないこと
- budget なしの開始、public port 露出、eval 前の training。
- 残す証拠
gpu_plan.md、environment_report.txt、request/response log、shutdown proof。
Colab は良い学習ルートですが、利用できるときに使うリソースとして扱います。Google Colab FAQ では、無料 compute resources には GPU/TPU が含まれる場合がある一方で、リソースは保証も無制限もされず、利用制限は変動し得ると説明されています。無料 GPU が使えない場合でも CPU で実験ループを通せる計画にしてください。
最小の証明から始める
Section titled “最小の証明から始める”答えたい問いでルートを選びます。
| 問い | ルート |
|---|---|
| 「Python 環境が model を読み込み、text を生成できるか?」 | ローカル CPU |
| 「同じ notebook を一時的な hosted machine で動かせるか?」 | 無料 Colab |
| 「この model を既知の VRAM、latency、shutdown で serving できるか?」 | レンタル GPU |
| 「fine-tune すべきか?」 | まだ計算ルートを選ばない。固定 eval cases が先 |
最初の有用な証明は、賢い回答ではありません。environment -> model -> prompt -> output -> evaluation -> stop の再現可能な trace です。
compute_route.md を書く
Section titled “compute_route.md を書く”コマンドを動かす前に、このファイルを書きます。
# Compute Route
goal: prove the open-source LLM deployment loop for one small projectroute: local_cpu / free_colab / rented_gpuselected_model:runtime:expected_runtime_limit:privacy_level:budget_limit:stop_time:fallback_route:
## Why this route
## What this route can prove
## What this route cannot prove yet
## Evidence to copy back
## Stop or rollback stepstop_time、fallback_route、evidence to copy back が空なら、まだ GPU を借りません。
Route A:ローカル CPU
Section titled “Route A:ローカル CPU”最初はこのルートを使います。既定の tiny model だけでも、13.2 実践:オープンソース LLM を動かしてサービス化する の大部分を完了できます。
mkdir openllm_labcd openllm_lab
python -m venv .venvsource .venv/bin/activatepython -m pip install -U pippython -m pip install "torch" "transformers>=4.41" "accelerate" "safetensors" "sentencepiece" "fastapi" "uvicorn"次に既定の smoke-test model で lab を動かします。
python environment_report.pypython run_local_llm.pypython eval_openllm.pyuvicorn serve_openai_like:app --host 127.0.0.1 --port 8000Ctrl+C で停止します。合格条件は回答品質ではなく、environment、inference、evaluation、API、stop path が動くことです。
コードを素早く変えるときはこのルートを使います。model quality の主張は、より適した model と固定 evaluation set に任せます。
Route B:無料 Colab
Section titled “Route B:無料 Colab”hosted notebook が必要で、GPU が利用できる可能性があるときに使います。GPU が常に割り当てられるとは考えないでください。
Notebook で実行します。
!python -V!nvidia-smi || true!python -m pip install -U pip!python -m pip install "torch" "transformers>=4.41" "accelerate" "safetensors" "sentencepiece"その後、hands-on ページの local inference と evaluation code を cell にコピーします。まずは次から始めます。
MODEL_ID="sshleifer/tiny-gpt2" python run_local_llm.pypython eval_openllm.pyGPU が使えて notebook が安定している場合、小型 instruct model を試します。
MODEL_ID="Qwen/Qwen2.5-0.5B-Instruct" python run_local_llm.pyColab 固有のメモを残します。
runtime_type:gpu_visible: yes/nonotebook_url_or_copy:install_cells:first_run_output:files_downloaded_back:what_would_break_if_runtime_resets:private documents、secrets、長時間 serving workloads を無料 notebook に入れないでください。安定した serving が必要なら、レンタル GPU または管理できる local/server environment を使います。
Route C:レンタル GPU
Section titled “Route C:レンタル GPU”ローカル CPU または Colab で evidence bundle ができてから借ります。レンタルマシンは、境界のある 1 つの問いに答えるために使います。
- 7B 級 instruct model を vLLM で serving できるか?
- 固定 eval set は大きめの model で通るか?
- この route の latency と memory はどの程度か?
先に gpu_plan.md を書きます。
# GPU Plan
goal:model:runtime:instance_vram:disk:region:hourly_budget:hard_stop_time:ports_to_open:access_method: SSH keyevidence_to_copy_back:shutdown_proof:fallback_if_oom:remote machine で実行します。
python -Vnvidia-smidf -hpython -m pip install -U pippython -m pip install "vllm"まず localhost に bind します。
vllm serve Qwen/Qwen2.5-0.5B-Instruct --host 127.0.0.1 --port 8000local machine から SSH tunnel を張ります。
ssh -L 8000:127.0.0.1:8000 user@your-gpu-hostOpenAI-compatible endpoint を test します。
curl http://127.0.0.1:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen2.5-0.5B-Instruct", "messages": [{"role": "user", "content": "Give one deployment rule for a rented GPU."}] }'test 後は evidence をコピーして、instance を stop または destroy します。model demo が成功しても billing が残っていれば、engineering run としては失敗です。
ルート決定ドリル
Section titled “ルート決定ドリル”続ける前に埋めます。
I will use _____ because _____.This route can prove _____.This route cannot prove _____ yet.I will stop or fall back when _____.The evidence I must copy back is _____.答えの見方
強い答えは、熱意ではなく制約を言います。たとえば、ローカル CPU は code path を証明できますが service throughput は証明できません。Colab は notebook path を試せますが GPU availability は保証しません。レンタル GPU は serving を試せますが budget、SSH、ports、shutdown proof が必要です。「速いから」だけなら、route decision は未完成です。
- Compute Route
- local_cpu / free_colab / rented_gpu and why
- Environment
- Python, torch, CUDA/MPS/CPU, disk, runtime reset risk
- Budget Or Limit
- free quota caveat or rental stop time
- Security
- private data policy, secrets policy, exposed ports
- First Run
- model, command, prompt, output, latency or memory note
- Stop Proof
- Ctrl+C, notebook saved, or rented instance stopped
合格チェック
Section titled “合格チェック”1つの計算ルートを選び、それが何を証明できて何をまだ証明できないかを説明し、environment check を動かし、hands-on lab に進む前に stop または fallback step を言えるなら、この lesson は合格です。