6.3.5 転移学習
- CNN をゼロから学習することが、なぜ無駄になりやすいかを説明できる。
- pretrained backbone と classification head を区別できる。
- backbone を freeze し、新しい head だけを学習できる。
- より小さい学習率で最後の畳み込み block を fine-tune できる。
- データ漏洩や破壊的な fine-tuning など、よくあるミスを避けられる。
まず判断フローを見る
Section titled “まず判断フローを見る”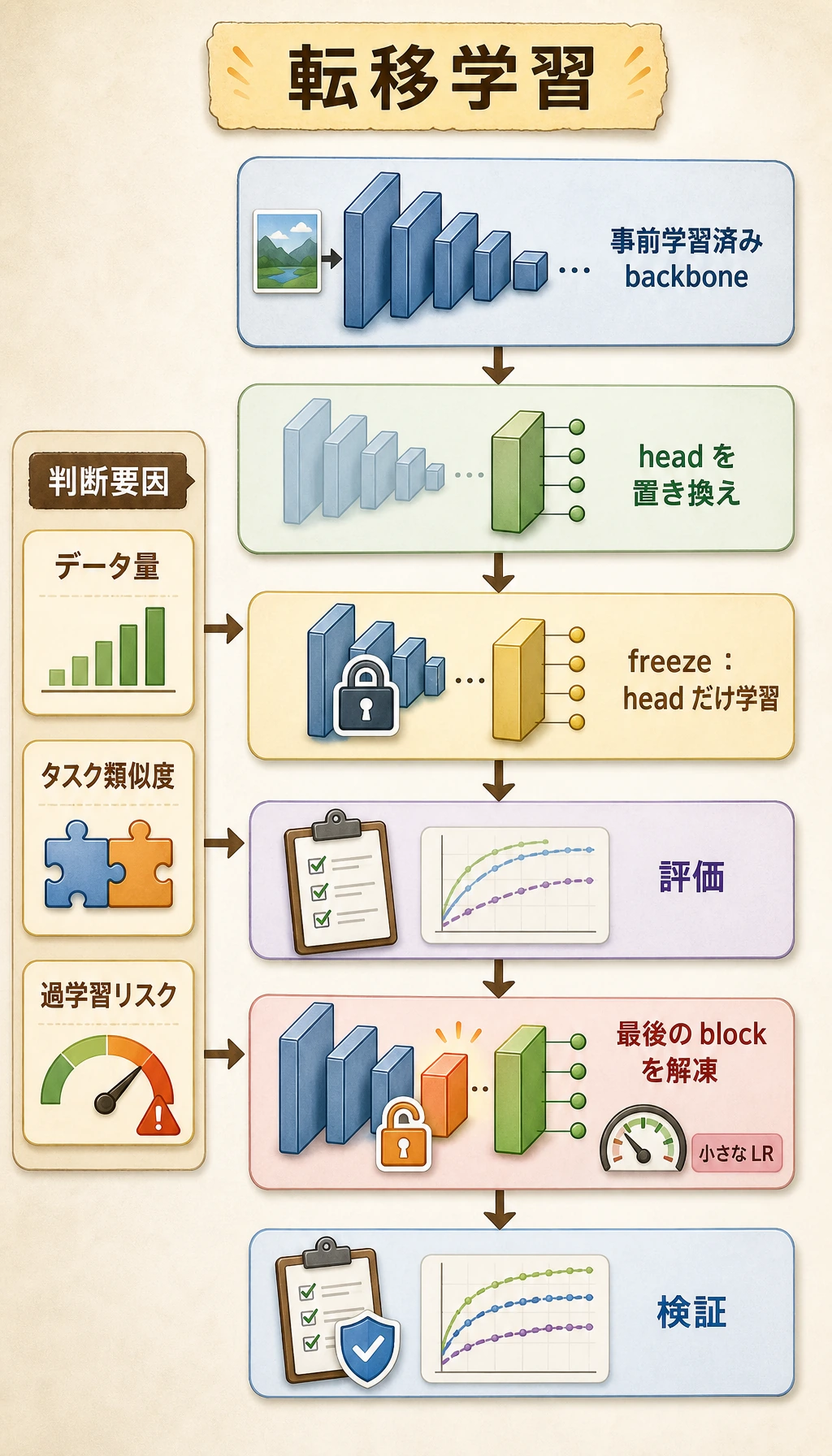
次の流れで読みます。
pretrained backbonereplace headtrain headvalidate必要なら後ろの層を解凍
判断を左右する質問は 2 つです。
| 質問 | データが少ない / タスクが近い | データが多い / タスクが違う |
|---|---|---|
| ラベル付きデータはどれくらいあるか | まず多くの層を freeze | 注意深く多くの層を fine-tune |
| 新しいタスクはどれくらい似ているか | 事前学習特徴がよく転移する可能性がある | 後ろの層の適応が必要かもしれない |
この節では、torchvision の重みをダウンロードしなくても動くように、純粋な PyTorch と合成画像を使います。実務では、backbone は通常、事前学習済みの torchvision や timm モデルを使います。
| 用語 | 意味 |
|---|---|
| backbone | 特徴抽出器。通常は最終分類器より前の層全体 |
| head | backbone の後ろに付ける、タスク固有の分類器または回帰器 |
| freeze | requires_grad=False にして、パラメータを更新しないこと |
| fine-tune | 事前学習済み層の一部を解凍し、追加で学習すること |
| logits | softmax の前の生のクラススコア |
実践ルールは次の通りです。
データが少ない -> まず head を学習十分でない -> より小さい学習率で後ろの backbone 層を解凍完整な実験:オフラインで転移学習を模擬する
Section titled “完整な実験:オフラインで転移学習を模擬する”この実験には 3 つの段階があります。
- 単純な線パターンで tiny backbone を事前学習する。
- その backbone を新しいターゲットタスクに再利用し、head だけを学習する。
- 最後の畳み込み層を解凍し、より小さい学習率で軽く fine-tune する。
完整なスクリプトを実行します。
import copyimport numpy as npimport torchfrom torch import nn
SEED = 7np.random.seed(SEED)torch.manual_seed(SEED)
def make_image(label, task, size=16, noise=0.05): img = np.zeros((size, size), dtype=np.float32) c = size // 2
if task == "source": if label == 0: img[:, c] = 1.0 elif label == 1: img[c, :] = 1.0 else: for i in range(size): img[i, i] = 1.0 elif task == "target": if label == 0: img[:, c] = 1.0 img[c, :] = 1.0 elif label == 1: for i in range(size): img[i, size - 1 - i] = 1.0 else: img[3:-3, 3] = 1.0 img[3:-3, -4] = 1.0 img[3, 3:-3] = 1.0 img[-4, 3:-3] = 1.0
img += np.random.randn(size, size).astype(np.float32) * noise return np.clip(img, 0.0, 1.0)
def make_dataset(task, per_class, size=16): X, y = [], [] for label in range(3): for _ in range(per_class): X.append(make_image(label, task, size=size)) y.append(label) X = torch.tensor(np.array(X)).unsqueeze(1) y = torch.tensor(np.array(y), dtype=torch.long) return X, y
class TinyBackbone(nn.Module): def __init__(self): super().__init__() self.features = nn.Sequential( nn.Conv2d(1, 8, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2), nn.Conv2d(8, 16, kernel_size=3, padding=1), nn.ReLU(), nn.AdaptiveAvgPool2d((1, 1)), )
def forward(self, x): return self.features(x).flatten(1)
class ImageClassifier(nn.Module): def __init__(self, backbone=None, num_classes=3): super().__init__() self.backbone = backbone if backbone is not None else TinyBackbone() self.head = nn.Linear(16, num_classes)
def forward(self, x): return self.head(self.backbone(x))
def accuracy(model, X, y): with torch.no_grad(): return (model(X).argmax(dim=1) == y).float().mean().item()
def train(model, X, y, optimizer, epochs, label, print_every): loss_fn = nn.CrossEntropyLoss() for epoch in range(1, epochs + 1): logits = model(X) loss = loss_fn(logits, y)
optimizer.zero_grad() loss.backward() optimizer.step()
if epoch == 1 or epoch % print_every == 0: acc = accuracy(model, X, y) print(f"{label} epoch={epoch:02d} loss={loss.item():.4f} acc={acc:.3f}")
source_X, source_y = make_dataset("source", per_class=80)target_train_X, target_train_y = make_dataset("target", per_class=12)target_val_X, target_val_y = make_dataset("target", per_class=40)
# Stage 1: pretrain a source model.source_model = ImageClassifier(num_classes=3)train( source_model, source_X, source_y, torch.optim.Adam(source_model.parameters(), lr=0.03), epochs=60, label="pretrain", print_every=20,)
# Stage 2: transfer the backbone and train only a new head.frozen_backbone = copy.deepcopy(source_model.backbone)transfer_model = ImageClassifier(backbone=frozen_backbone, num_classes=3)for p in transfer_model.backbone.parameters(): p.requires_grad = False
print("trainable_after_freeze")for name, p in transfer_model.named_parameters(): print(f"{name:<28} {p.requires_grad}")
train( transfer_model, target_train_X, target_train_y, torch.optim.Adam(transfer_model.head.parameters(), lr=0.05), epochs=20, label="head", print_every=10,)print("head_only_val_acc", round(accuracy(transfer_model, target_val_X, target_val_y), 3))
# Stage 3: unfreeze the last conv layer and fine-tune gently.for p in transfer_model.backbone.features[3].parameters(): p.requires_grad = True
optimizer = torch.optim.Adam( [ {"params": transfer_model.backbone.features[3].parameters(), "lr": 0.0005}, {"params": transfer_model.head.parameters(), "lr": 0.005}, ])train( transfer_model, target_train_X, target_train_y, optimizer, epochs=20, label="finetune", print_every=10,)print("finetune_val_acc", round(accuracy(transfer_model, target_val_X, target_val_y), 3))期待される出力:
pretrain epoch=01 loss=1.0995 acc=0.667pretrain epoch=20 loss=0.0000 acc=1.000pretrain epoch=40 loss=0.0000 acc=1.000pretrain epoch=60 loss=0.0000 acc=1.000trainable_after_freezebackbone.features.0.weight Falsebackbone.features.0.bias Falsebackbone.features.3.weight Falsebackbone.features.3.bias Falsehead.weight Truehead.bias Truehead epoch=01 loss=2.4749 acc=0.361head epoch=10 loss=0.7364 acc=0.667head epoch=20 loss=0.4991 acc=0.944head_only_val_acc 0.875finetune epoch=01 loss=0.4759 acc=0.667finetune epoch=10 loss=0.4367 acc=1.000finetune epoch=20 loss=0.4096 acc=1.000finetune_val_acc 1.0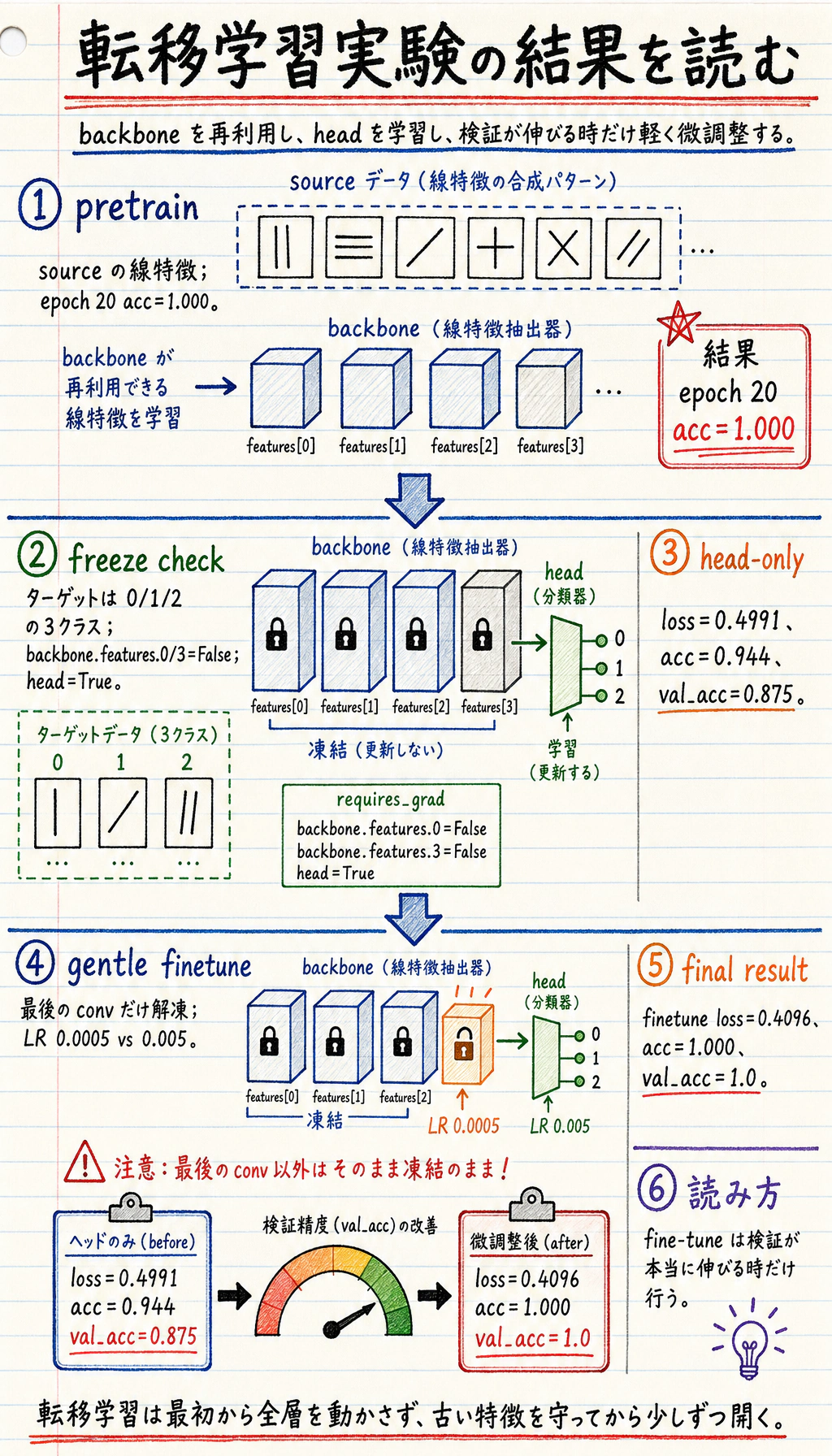
この図は 3 段階で読みます。
pretrainは、tiny backbone が再利用できる線パターン特徴を抽出できたことを示します。trainable_after_freezeは安全確認です。backbone は freeze されたままで、新しい head だけが更新されます。head_only_val_acc=0.875でもすでに有用で、finetune_val_acc=1.0は最後の畳み込み層を軽く解凍したことが、この検証セットでは効いたことを示します。
この実験から分かること
Section titled “この実験から分かること”| 段階 | 何が起きたか | 実践上の意味 |
|---|---|---|
| pretrain | backbone が線のような視覚特徴を学んだ | ここでは実際の事前学習モデルを模擬している |
| freeze | 新しい head だけが学習可能 | 小さなターゲットデータでは速くて安全 |
| train head | ターゲット検証精度が実用的になった | 再利用した特徴がすでに役立っている |
| fine-tune | 最後の畳み込み層を軽く適応させた | 小さい学習率で古い特徴を壊しにくくする |
Fine-tuning は自動的に良くなるものではありません。ターゲットデータが少なすぎたり、学習率が大きすぎたりすると、過学習したり事前学習特徴を壊したりします。判断基準は常に検証結果であり、training loss だけではありません。
転移学習実験では、この判断記録を残します。
- 凍結確認
- どの層が requires_grad=False か
- ヘッド結果
- 新しい head のみを学習した後の検証スコア
- ファインチューニング結果
- 後半層を解凍した後の validation スコア
- 判断
- training loss ではなく validation に基づいて、freeze するか fine-tune するかを決める
- リスク注意
- データ量、ドメイン不一致、前処理不一致
これにより、転移学習は「大きなモデルを使う」だけではなく、管理された engineering workflow になります。
実プロジェクトの流れ
Section titled “実プロジェクトの流れ”- モデルに触る前に、train/validation/test を分ける。
- 事前学習済み backbone を読み込む。
- head を置き換え、出力クラス数を自分のタスクに合わせる。
- backbone を freeze し、head だけを学習する。
- 検証データの誤りを確認する。
- 必要なら後ろの block を解凍し、backbone には小さい学習率を使う。
- 検証性能がそれ以上伸びなくなったら止める。
実画像では、事前学習 weight が期待する前処理にも合わせます。入力サイズ、正規化の mean/std、色 channel の順序です。
Freeze か Fine-Tune か
Section titled “Freeze か Fine-Tune か”| 状況 | 最初の選択 |
|---|---|
| データがとても少なく、タスクが近い | backbone を freeze し、head を学習 |
| 中規模データで、タスクが近い | まず freeze、その後最後の block を解凍 |
| データが多く、視覚ドメインが異なる | 注意深く多くの block を fine-tune |
| 医療・衛星・工業画像 | 慎重に検証する。自然画像の事前学習特徴は一部だけ転移する可能性がある |
| デプロイ制約が強い端末 | 小さな backbone または freeze-and-head baseline から始める |
よくあるミス
Section titled “よくあるミス”| ミス | なぜ困るか | 修正 |
|---|---|---|
| いきなり全層を fine-tune する | 小データでは不安定 | まず head を学習する |
| すべてに同じ学習率を使う | backbone が強く更新されすぎる | 事前学習層には小さい LR を使う |
requires_grad を確認しない | 意図しない層が静かに学習される | 学習可能パラメータを表示する |
| training data だけで評価する | 過学習を隠す | validation set を用意する |
| 前処理が合っていない | 事前学習特徴が慣れていない入力スケールを受け取る | weight が想定する transform を使う |
| split の漏洩 | 検証が意味を失う | 必要なら画像の出所、ユーザー、対象物ごとに分割する |
- 4 つ目のターゲットクラスを追加し、新しい合成パターンを設計する。
- ターゲット訓練データをクラスあたり
12から40に増やす。head だけの学習は改善するか。 - backbone の fine-tuning 学習率を
0.0005から0.05に変える。何が起きるか。 - 最後の畳み込みを解凍した後、学習可能なパラメータ名だけを表示する。
- 大きな
Flattenhead より、GAP と小さな head が向いている場面を説明する。
参考実装と解説
- 新しいクラスを追加する場合は、データ生成、ラベル、分類 head の出力次元、評価表示をすべて更新します。パターンは既存クラスと区別できる特徴を持たせます。
- データが増えると head だけの学習はより安定しやすくなります。改善幅は、事前学習特徴とターゲット分布の近さに依存します。
0.05は backbone には大きすぎることが多く、既存特徴を壊して loss の振動や検証性能低下を招きます。requires_grad=Trueのパラメータ名だけを表示すれば、意図した範囲だけを fine-tuning しているか確認できます。- GAP と小さな head はパラメータが少なく、入力サイズにも強いため、小データの transfer learning に向いています。
- 転移学習は、すべてをゼロから学び直すのではなく、視覚特徴を再利用する。
- 最も安全な最初の baseline は、多くの場合「head を置き換える、backbone を freeze、head を学習」です。
- 検証結果が必要性を示したときだけ、後ろの層を fine-tune する。
- 事前学習済み層には小さい学習率を使う。
- 良い転移学習は、大きなモデルをコピーすることではなく、工程として管理することです。