3.6.2 実践プロジェクト:多データソース統合分析
まずは全体像をつかもう
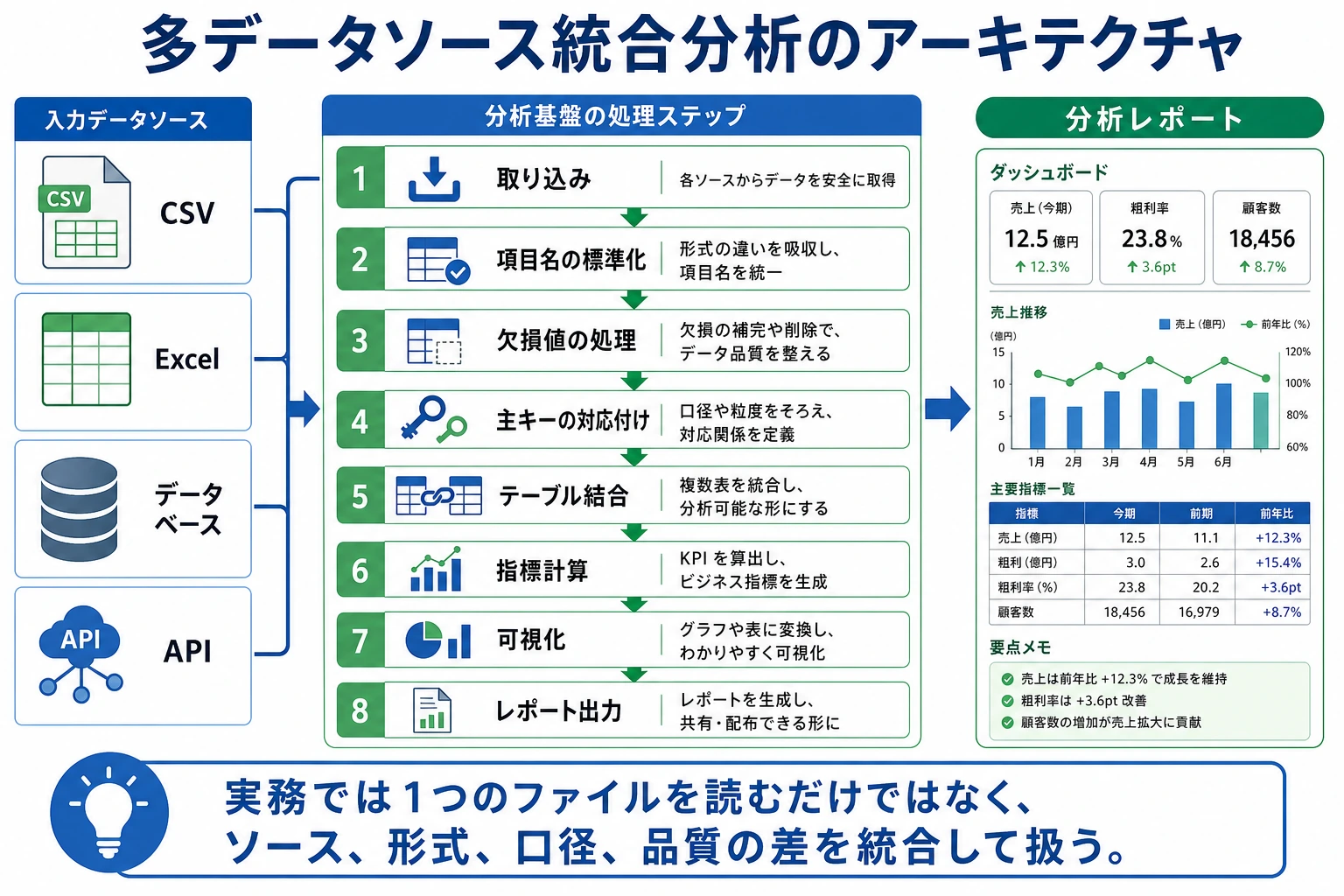
Section titled “まずは全体像をつかもう”このプロジェクトを初学者が理解しやすい順番は、「まず merge を始める」ではなく、先に次をはっきりさせることです。
flowchart LR A["複数ソースのデータを読み込む"] --> B["主キーとフィールドを確認する"] B --> C["まず 1 つの広い表に統合する"] C --> D["それからクレンジングと派生特徴量を作る"] D --> E["最後に分析とダッシュボードを作る"]この節で本当に練習したいのは次の点です。
- 複数ソースのデータを、どうやって同じ分析表に入れるか
- いつキーを確認すべきか、いつから分析を始めるべきか
プロジェクト概要
Section titled “プロジェクト概要”実務では、データがきれいに 1 つの CSV にまとまっていることはほとんどありません。CSV、JSON、データベースなど複数のソースからデータを取り、まずクレンジングして統合し、その後で分析します。
flowchart TD A["CSV ファイル<br/>注文データ"] --> D["データ統合<br/>Pandas merge/concat"] B["JSON ファイル<br/>商品データ"] --> D C["SQLite データベース<br/>ユーザーデータ"] --> D D --> E["データクレンジング"] E --> F["分析と可視化"] F --> G["レポート/ダッシュボード出力"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style B fill:#fff3e0,stroke:#e65100,color:#333 style C fill:#e8f5e9,stroke:#2e7d32,color:#333 style G fill:#f3e5f5,stroke:#7b1fa2,color:#333初学者向けのわかりやすい見立て
Section titled “初学者向けのわかりやすい見立て”このプロジェクトは、次のように考えると理解しやすいです。
- 別々の部署から来た表をつなぎ合わせて、実際に報告できる総合表を作る
つまり、このプロジェクトで本当に難しいのは次のような点です。
- グラフを描けるかどうか
ではなく、
- データを先に正しくそろえられるか
- 表同士を正しくつなげられるか
プロジェクトのシナリオ
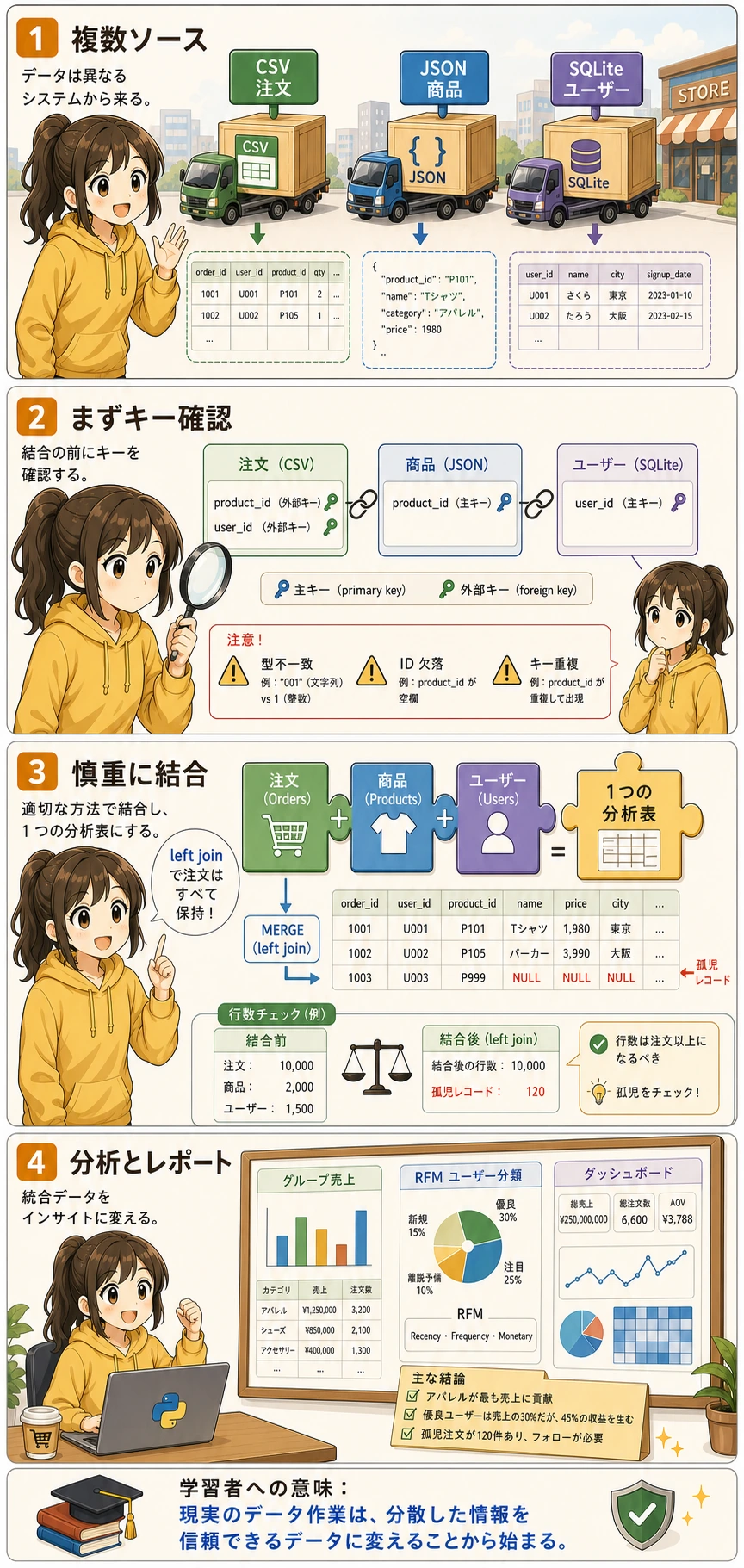
Section titled “プロジェクトのシナリオ”あなたは、あるオンライン小売会社のデータアナリストです。会社のデータは、いくつかのシステムに分散しています。
| データソース | 形式 | 内容 |
|---|---|---|
| 販売システムの出力 | CSV | 注文記録(注文ID、ユーザーID、商品ID、数量、日付) |
| 商品管理システム API | JSON | 商品情報(商品ID、名称、カテゴリ、価格) |
| ユーザーシステムのデータベース | SQLite | ユーザー情報(ユーザーID、名前、都市、登録日) |
あなたの仕事は、これらのデータを統合して売上状況を分析し、価値のある分析レポートを作ることです。
まず理解しておきたい略語
Section titled “まず理解しておきたい略語”| 用語 | 英語の正式名称 | 初学者向けの意味 |
|---|---|---|
CSV | Comma-Separated Values | カンマ区切りの値。業務システムからよく出力される表形式のテキスト |
JSON | JavaScript Object Notation | API がよく返す構造化テキスト形式 |
API | Application Programming Interface | あるシステムが別のシステムにデータや機能を渡すための入口 |
ID | Identifier | ユーザー、商品、注文、レコードを安定して識別する値 |
PK | Primary Key | 主キー。その表の中で 1 行を一意に識別する ID |
FK | Foreign Key | 外部キー。別の表の行を指す ID |
RFM | Recency, Frequency, Monetary | 最近の購入、購入頻度、総購入額でユーザーを分ける代表的な方法 |
このプロジェクトで一番大切な実務習慣は、結合前に ID / PK / FK を確認することです。分析ミスの多くはグラフや統計ではなく、最初に違う行同士を結合してしまうことから起きます。
関連する知識
Section titled “関連する知識”| スキル | 対応章 |
|---|---|
| CSV/JSON の読み書き | 第 3 章 3.2 節 |
| Pandas merge による結合 | 第 3 章 3.7 節 |
| グループ集計とピボットテーブル | 第 3 章 3.6 節 |
| 時系列処理 | 第 3 章 3.8 節 |
| Matplotlib/Seaborn による可視化 | 第 4 章 |
| SQLite データベース操作 | 第 5 章 |
一、モックデータを準備する
Section titled “一、モックデータを準備する”実際のプロジェクトではデータはすでにありますが、学習のためにまず Python でモックデータを作ります。
注文データを生成する(CSV)
Section titled “注文データを生成する(CSV)”import numpy as npimport pandas as pdimport jsonimport sqlite3from datetime import datetime, timedelta
rng = np.random.default_rng(seed=42)
# ---------- 注文データ ----------n_orders = 2000order_dates = pd.date_range('2024-01-01', '2024-12-31', freq='h')order_dates = rng.choice(order_dates, n_orders)
orders = pd.DataFrame({ 'order_id': range(1, n_orders + 1), 'user_id': rng.integers(1, 201, n_orders), # 200 人のユーザー 'product_id': rng.integers(1, 51, n_orders), # 50 商品 'quantity': rng.choice([1, 1, 1, 2, 2, 3], n_orders), 'order_date': order_dates})
# CSV として保存orders.to_csv('orders.csv', index=False)print(f"注文データ:{orders.shape}")orders.head()商品データを生成する(JSON)
Section titled “商品データを生成する(JSON)”# ---------- 商品データ ----------categories = ['電子製品', '衣類', '食品', '家具', '書籍']products = []
for i in range(1, 51): cat = rng.choice(categories) # カテゴリごとに価格帯が異なる price_ranges = { '電子製品': (200, 5000), '衣類': (50, 800), '食品': (10, 100), '家具': (30, 500), '書籍': (20, 150), } low, high = price_ranges[cat] price = round(rng.uniform(low, high), 2)
products.append({ 'product_id': i, 'name': f'{cat}_{i:03d}', 'category': cat, 'price': price })
# JSON として保存with open('products.json', 'w', encoding='utf-8') as f: json.dump(products, f, ensure_ascii=False, indent=2)
print(f"商品データ:{len(products)} 商品")pd.DataFrame(products).head()ユーザーデータを生成する(SQLite)
Section titled “ユーザーデータを生成する(SQLite)”# ---------- ユーザーデータ ----------cities = ['北京', '上海', '广州', '深圳', '杭州', '成都', '武汉', '南京', '重庆', '西安']
users = pd.DataFrame({ 'user_id': range(1, 201), 'name': [f'ユーザー_{i:03d}' for i in range(1, 201)], 'city': rng.choice(cities, 200), 'register_date': pd.date_range('2022-01-01', periods=200, freq='2D')})
# SQLite に保存conn = sqlite3.connect('users.db')users.to_sql('users', conn, if_exists='replace', index=False)conn.close()
print(f"ユーザーデータ:{users.shape}")users.head()二、複数ソースのデータを読み込む
Section titled “二、複数ソースのデータを読み込む”CSV を読む
Section titled “CSV を読む”import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport jsonimport sqlite3
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = Falsesns.set_theme(style="whitegrid", font_scale=1.1)
# 1. CSV を読み込むorders = pd.read_csv('orders.csv', parse_dates=['order_date'])print(f"注文データ:{orders.shape}")print(orders.dtypes)orders.head()JSON を読む
Section titled “JSON を読む”# 2. JSON を読み込むwith open('products.json', 'r', encoding='utf-8') as f: products_list = json.load(f)
products = pd.DataFrame(products_list)print(f"\n商品データ:{products.shape}")products.head()Pandas なら直接読むこともできます。
# Pandas なら 1 行でOKproducts = pd.read_json('products.json')SQLite を読む
Section titled “SQLite を読む”# 3. SQLite を読み込むconn = sqlite3.connect('users.db')users = pd.read_sql_query("SELECT * FROM users", conn, parse_dates=['register_date'])conn.close()
print(f"\nユーザーデータ:{users.shape}")users.head()データの全体確認
Section titled “データの全体確認”print("=" * 50)print("データソースのまとめ")print("=" * 50)print(f"注文表:{orders.shape[0]} 行 × {orders.shape[1]} 列")print(f"商品表:{products.shape[0]} 行 × {products.shape[1]} 列")print(f"ユーザー表:{users.shape[0]} 行 × {users.shape[1]} 列")
# 連結キーを確認するprint(f"\n注文データの user_id 範囲:{orders['user_id'].min()} ~ {orders['user_id'].max()}")print(f"注文データの product_id 範囲:{orders['product_id'].min()} ~ {orders['product_id'].max()}")print(f"ユーザー表の user_id 範囲:{users['user_id'].min()} ~ {users['user_id'].max()}")print(f"商品表の product_id 範囲:{products['product_id'].min()} ~ {products['product_id'].max()}")初めて多ソース分析をするとき、まず何を確認するべき?
Section titled “初めて多ソース分析をするとき、まず何を確認するべき?”まず確認したいのは、次の 3 つです。
- どのキーで表同士をつなぐのか
- キーの範囲や型が一致しているか
- 結合後に、マッチしないレコードが大量に出ないか
ここはとても大事です。後で「分析がおかしい」と見える問題の多くは、 最初の結合が正しくできていないことが原因です。
三、データを統合する
Section titled “三、データを統合する”これが本プロジェクトの中心部分です。3 つの表を 1 つの広い表にまとめます。
flowchart LR O["orders 表"] -->|"product_id"| OP["orders + products"] P["products 表"] --> OP OP -->|"user_id"| FULL["完全な広い表"] U["users 表"] --> FULL
style O fill:#e3f2fd,stroke:#1565c0,color:#333 style P fill:#fff3e0,stroke:#e65100,color:#333 style U fill:#e8f5e9,stroke:#2e7d32,color:#333 style FULL fill:#f3e5f5,stroke:#7b1fa2,color:#333# 1 つ目:注文 + 商品情報df = orders.merge(products, on='product_id', how='left')print(f"商品を結合後:{df.shape}")
# 2 つ目:+ ユーザー情報df = df.merge(users, on='user_id', how='left')print(f"ユーザーを結合後:{df.shape}")
df.head()重要指標を計算する
Section titled “重要指標を計算する”# 注文金額 = 単価 × 数量df['amount'] = df['price'] * df['quantity']
# 時間軸の特徴を取り出すdf['month'] = df['order_date'].dt.monthdf['weekday'] = df['order_date'].dt.day_name()df['quarter'] = df['order_date'].dt.quarter
# 結果を確認print(f"\n完全なデータセット:{df.shape[0]} 行 × {df.shape[1]} 列")print(f"総売上:¥{df['amount'].sum():,.0f}")print(f"平均注文金額:¥{df['amount'].mean():,.0f}")df[['order_id', 'name_x', 'category', 'quantity', 'price', 'amount', 'city', 'month']].head(10)データ品質の確認
Section titled “データ品質の確認”# 結合後のデータの完全性を確認するprint("=== 結合後のデータ品質チェック ===")print(f"総行数:{len(df)}")print(f"欠損値:")print(df.isnull().sum()[df.isnull().sum() > 0])
# 欠損値がある場合、いくつかの ID が対応表に存在しない可能性がある# 孤立レコードを確認するorphan_products = set(orders['product_id']) - set(products['product_id'])orphan_users = set(orders['user_id']) - set(users['user_id'])print(f"\n対応できない product_id:{orphan_products if orphan_products else 'なし'}")print(f"対応できない user_id:{orphan_users if orphan_users else 'なし'}")初学者がそのまま使える統合チェックリスト
Section titled “初学者がそのまま使える統合チェックリスト”初めて複数ソースを統合するときは、次のチェックを先に行うと安全です。
- 主キーが一意で、型も一致しているか
- 結合後に行数が不自然に増減していないか
- マッチしない孤立レコードが大量に出ていないか
- 結合後の列名に衝突やあいまいさがないか
この 4 点を先に確認してから分析すると、かなり安定します。
四、分析 1:売上の全体像
Section titled “四、分析 1:売上の全体像”print("=" * 50)print(" 2024 年の売上概要")print("=" * 50)print(f" 総注文数:{df['order_id'].nunique():,}")print(f" 総売上:¥{df['amount'].sum():,.0f}")print(f" 平均客単価:¥{df.groupby('order_id')['amount'].sum().mean():,.0f}")print(f" アクティブユーザー数:{df['user_id'].nunique()}")print(f" 商品数:{df['product_id'].nunique()}")カテゴリ分析
Section titled “カテゴリ分析”# 各カテゴリの売上と注文数cat_stats = df.groupby('category').agg( 売上=('amount', 'sum'), 注文数=('order_id', 'count'), 平均単価=('price', 'mean'), 商品数=('product_id', 'nunique')).round(0).sort_values('売上', ascending=False)
print(cat_stats)fig, axes = plt.subplots(1, 2, figsize=(14, 5))
# カテゴリ別売上比率colors = ['#2196f3', '#ff9800', '#4caf50', '#f44336', '#9c27b0']axes[0].pie(cat_stats['売上'], labels=cat_stats.index, autopct='%1.1f%%', colors=colors, startangle=90, pctdistance=0.85)axes[0].set_title('各カテゴリの売上比率')
# カテゴリ別注文数比較cat_stats['注文数'].plot(kind='barh', ax=axes[1], color=colors)axes[1].set_title('各カテゴリの注文数')axes[1].set_xlabel('注文数')
plt.tight_layout()plt.savefig('07_category.png', dpi=150, bbox_inches='tight')plt.show()# 売上上位の都市city_stats = df.groupby('city').agg( 売上=('amount', 'sum'), 注文数=('order_id', 'count'), ユーザー数=('user_id', 'nunique')).sort_values('売上', ascending=False)
fig, ax = plt.subplots(figsize=(10, 5))city_stats['売上'].plot(kind='bar', color='steelblue', ax=ax)ax.set_title('都市別売上')ax.set_ylabel('売上(元)')ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
# 棒の上に数値を表示for i, v in enumerate(city_stats['売上']): ax.text(i, v + v*0.01, f'¥{v:,.0f}', ha='center', va='bottom', fontsize=9)
plt.tight_layout()plt.savefig('08_city.png', dpi=150, bbox_inches='tight')plt.show()この段階でまず学びたいこと
Section titled “この段階でまず学びたいこと”まず押さえたいのは次の点です。
- 複数ソースのプロジェクトでも、統合ができれば、その後の分析はだんだん単一表の分析に近づく
つまり、このプロジェクトの本当の関門は、グラフそのものよりも次の部分です。
- 結合前のデータ理解
- 結合時のキーの対応づけ
五、分析 2:時間トレンド
Section titled “五、分析 2:時間トレンド”月別トレンド
Section titled “月別トレンド”# 月ごとに集計monthly = df.groupby('month').agg( 売上=('amount', 'sum'), 注文数=('order_id', 'count')).reset_index()
fig, ax1 = plt.subplots(figsize=(12, 5))
# 二軸グラフ:売上を棒グラフ、注文数を折れ線グラフcolor1 = 'steelblue'color2 = 'coral'
bars = ax1.bar(monthly['month'], monthly['売上'], color=color1, alpha=0.7, label='売上')ax1.set_xlabel('月')ax1.set_ylabel('売上(元)', color=color1)ax1.tick_params(axis='y', labelcolor=color1)ax1.set_xticks(range(1, 13))
ax2 = ax1.twinx()ax2.plot(monthly['month'], monthly['注文数'], color=color2, marker='o', linewidth=2, label='注文数')ax2.set_ylabel('注文数', color=color2)ax2.tick_params(axis='y', labelcolor=color2)
ax1.set_title('月別売上トレンド(2024 年)')
# 凡例をまとめるlines1, labels1 = ax1.get_legend_handles_labels()lines2, labels2 = ax2.get_legend_handles_labels()ax1.legend(lines1 + lines2, labels1 + labels2, loc='upper left')
plt.tight_layout()plt.savefig('09_monthly.png', dpi=150, bbox_inches='tight')plt.show()# 曜日ごとに集計weekday_order = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'Sunday']weekday_cn = ['月', '火', '水', '木', '金', '土', '日']
weekday_stats = df.groupby('weekday')['amount'].agg(['sum', 'count']).reindex(weekday_order)weekday_stats.index = weekday_cn
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
weekday_stats['sum'].plot(kind='bar', color='mediumseagreen', ax=axes[0])axes[0].set_title('曜日別売上')axes[0].set_ylabel('売上(元)')axes[0].set_xticklabels(weekday_cn, rotation=0)
weekday_stats['count'].plot(kind='bar', color='salmon', ax=axes[1])axes[1].set_title('曜日別注文数')axes[1].set_ylabel('注文数')axes[1].set_xticklabels(weekday_cn, rotation=0)
plt.tight_layout()plt.savefig('10_weekday.png', dpi=150, bbox_inches='tight')plt.show()カテゴリ別の月次トレンド
Section titled “カテゴリ別の月次トレンド”# 各カテゴリの月別売上cat_monthly = df.groupby(['month', 'category'])['amount'].sum().reset_index()
plt.figure(figsize=(12, 6))sns.lineplot(data=cat_monthly, x='month', y='amount', hue='category', marker='o', linewidth=2)plt.title('各カテゴリの月別売上トレンド')plt.xlabel('月')plt.ylabel('売上(元)')plt.xticks(range(1, 13))plt.legend(title='カテゴリ', bbox_to_anchor=(1.02, 1), loc='upper left')plt.tight_layout()plt.savefig('11_cat_monthly.png', dpi=150, bbox_inches='tight')plt.show()六、分析 3:ユーザー分析
Section titled “六、分析 3:ユーザー分析”ユーザー消費の層別化
Section titled “ユーザー消費の層別化”RFM モデル の簡易版でユーザーを分類します。
flowchart LR A["RFM モデル"] --> R["R — Recency<br/>最近の購入"] A --> F["F — Frequency<br/>購入頻度"] A --> M["M — Monetary<br/>購入総額"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style R fill:#fff3e0,stroke:#e65100,color:#333 style F fill:#fff3e0,stroke:#e65100,color:#333 style M fill:#fff3e0,stroke:#e65100,color:#333# RFM を計算するtoday = pd.Timestamp('2025-01-01') # 参照日
rfm = df.groupby('user_id').agg( Recency=('order_date', lambda x: (today - x.max()).days), # 最終購入からの日数 Frequency=('order_id', 'nunique'), # 注文回数 Monetary=('amount', 'sum') # 購入総額).round(0)
print(rfm.describe().round(1))rfm.head(10)ユーザー層の可視化
Section titled “ユーザー層の可視化”fig, axes = plt.subplots(1, 3, figsize=(16, 4))
axes[0].hist(rfm['Recency'], bins=30, color='steelblue', edgecolor='white')axes[0].set_title('R:最終購入からの日数')axes[0].set_xlabel('日数')
axes[1].hist(rfm['Frequency'], bins=20, color='coral', edgecolor='white')axes[1].set_title('F:購入頻度')axes[1].set_xlabel('注文数')
axes[2].hist(rfm['Monetary'], bins=30, color='mediumseagreen', edgecolor='white')axes[2].set_title('M:購入総額')axes[2].set_xlabel('金額(元)')
plt.tight_layout()plt.savefig('12_rfm.png', dpi=150, bbox_inches='tight')plt.show()簡単なユーザーセグメント分け
Section titled “簡単なユーザーセグメント分け”# 購入金額と頻度でユーザーを 4 つのグループに分けるrfm['value_group'] = pd.qcut(rfm['Monetary'], q=4, labels=['低価値', '中低', '中高', '高価値'])rfm['freq_group'] = pd.qcut(rfm['Frequency'], q=3, labels=['低頻度', '中頻度', '高頻度'], duplicates='drop')
# クロス集計:価値 × 頻度cross = pd.crosstab(rfm['value_group'], rfm['freq_group'], margins=True)print("ユーザーセグメントのクロス表:")print(cross)# 高価値ユーザーの特徴high_value = rfm[rfm['value_group'] == '高価値']print(f"\n高価値ユーザー:{len(high_value)} 人")print(f" 平均購入額:¥{high_value['Monetary'].mean():,.0f}")print(f" 平均頻度:{high_value['Frequency'].mean():.1f} 回")print(f" 平均間隔:{high_value['Recency'].mean():.0f} 日")都市 × ユーザー層
Section titled “都市 × ユーザー層”# RFM セグメントを主表に戻すuser_city = df.groupby('user_id')['city'].first().reset_index()rfm_city = rfm.reset_index().merge(user_city, on='user_id')
# 各都市の高価値ユーザー比率city_value = pd.crosstab(rfm_city['city'], rfm_city['value_group'], normalize='index') * 100
plt.figure(figsize=(12, 6))city_value[['高価値', '中高']].plot(kind='barh', stacked=True, color=['#2196f3', '#90caf9'], figsize=(10, 6))plt.title('各都市における中高/高価値ユーザー比率')plt.xlabel('割合(%)')plt.legend(title='ユーザーセグメント')plt.tight_layout()plt.savefig('13_city_value.png', dpi=150, bbox_inches='tight')plt.show()七、分析 4:総合ダッシュボード
Section titled “七、分析 4:総合ダッシュボード”重要な指標とグラフを 1 枚の大きな図にまとめます。
fig = plt.figure(figsize=(18, 14))fig.suptitle('2024 年 オンライン小売分析ダッシュボード', fontsize=18, fontweight='bold', y=0.98)
# ---------- 1. 主要指標(テキスト) ----------ax_text = fig.add_subplot(4, 3, (1, 3))ax_text.axis('off')
metrics = [ (f"¥{df['amount'].sum():,.0f}", "総売上"), (f"{df['order_id'].nunique():,}", "総注文数"), (f"{df['user_id'].nunique()}", "アクティブユーザー"), (f"¥{df.groupby('order_id')['amount'].sum().mean():,.0f}", "平均客単価"),]
for i, (value, label) in enumerate(metrics): x_pos = 0.12 + i * 0.22 ax_text.text(x_pos, 0.6, value, fontsize=22, fontweight='bold', color='#1565c0', ha='center', transform=ax_text.transAxes) ax_text.text(x_pos, 0.2, label, fontsize=12, color='#666', ha='center', transform=ax_text.transAxes)
# ---------- 2. 月次トレンド ----------ax2 = fig.add_subplot(4, 3, (4, 6))monthly_amount = df.groupby('month')['amount'].sum()ax2.fill_between(monthly_amount.index, monthly_amount.values, alpha=0.3, color='steelblue')ax2.plot(monthly_amount.index, monthly_amount.values, color='steelblue', linewidth=2, marker='o')ax2.set_title('月別売上トレンド', fontsize=13)ax2.set_xlabel('月')ax2.set_ylabel('売上')ax2.set_xticks(range(1, 13))
# ---------- 3. カテゴリ円グラフ ----------ax3 = fig.add_subplot(4, 3, 7)cat_amount = df.groupby('category')['amount'].sum().sort_values(ascending=False)colors = ['#2196f3', '#ff9800', '#4caf50', '#f44336', '#9c27b0']ax3.pie(cat_amount, labels=cat_amount.index, autopct='%1.0f%%', colors=colors, startangle=90, textprops={'fontsize': 9})ax3.set_title('カテゴリ売上比率', fontsize=13)
# ---------- 4. Top 商品 ----------ax4 = fig.add_subplot(4, 3, 8)# product_id に紐づく name 列を使う(name または product_name の可能性あり)product_col = 'name' if 'name' in df.columns else df.columns[df.columns.str.contains('name')][0]top_products = df.groupby('product_id')['amount'].sum().nlargest(8)product_names = products.set_index('product_id').loc[top_products.index, 'name']ax4.barh(product_names.values[::-1], top_products.values[::-1], color='coral')ax4.set_title('売れ筋商品 Top 8', fontsize=13)ax4.set_xlabel('売上')
# ---------- 5. 都市比較 ----------ax5 = fig.add_subplot(4, 3, 9)city_amount = df.groupby('city')['amount'].sum().sort_values(ascending=True)ax5.barh(city_amount.index, city_amount.values, color='mediumseagreen')ax5.set_title('都市別売上ランキング', fontsize=13)ax5.set_xlabel('売上')
# ---------- 6. ユーザー消費分布 ----------ax6 = fig.add_subplot(4, 3, (10, 12))user_amount = df.groupby('user_id')['amount'].sum()ax6.hist(user_amount, bins=40, color='#7986cb', edgecolor='white', alpha=0.8)ax6.axvline(user_amount.mean(), color='red', linestyle='--', linewidth=2, label=f'平均: ¥{user_amount.mean():,.0f}')ax6.axvline(user_amount.median(), color='orange', linestyle='--', linewidth=2, label=f'中央値: ¥{user_amount.median():,.0f}')ax6.set_title('ユーザー購入金額分布', fontsize=13)ax6.set_xlabel('購入総額(元)')ax6.set_ylabel('ユーザー数')ax6.legend()
plt.tight_layout(rect=[0, 0, 1, 0.96])plt.savefig('14_dashboard.png', dpi=150, bbox_inches='tight')plt.show()八、分析結果と提案
Section titled “八、分析結果と提案” root((分析結果)) 売上の傾向 総売上と注文数の分布 カテゴリ差が大きい 電子製品の貢献が最大 時間の規則性 月ごとの変動 平日 vs 週末の差 季節性の特徴 ユーザーの洞察 少数のユーザーが大半の売上を支える 都市間の差が大きい ユーザー消費はロングテール分布 業務提案 高価値ユーザーに注力する 有望な都市を広げる カテゴリ別の販促を行う会社への提案
Section titled “会社への提案”- 高価値ユーザーの維持:上位 20% のユーザーが売上の大部分を生み出しているため、VIP 施策や専用サービスを用意する
- カテゴリ戦略:電子製品は単価が高い一方で、食品や書籍で集客し、ユーザーの定着を高める
- 都市展開:各都市の浸透率を分析し、ユーザー数は少ないが一人当たり消費が高い都市には、積極的にプロモーションを行う価値がある
- 時系列運営:月次や週内の傾向に合わせて、販促企画や在庫配置を調整する
- ユーザー獲得:新規・既存ユーザーの転換率に注目し、低頻度ユーザーにはクーポンを配布して再活性化する
九、プロジェクトまとめと発展
Section titled “九、プロジェクトまとめと発展”学習内容の振り返り
Section titled “学習内容の振り返り”| ステップ | 使ったスキル | 対応コード |
|---|---|---|
| データ読み込み | read_csv, read_json, read_sql_query | 第 2 節 |
| データ結合 | merge(複数表の連結) | 第 3 節 |
| グループ集計 | groupby, agg, pivot_table | 第 4〜6 節 |
| 時間処理 | dt.month, dt.day_name(), date_range | 第 5 節 |
| 可視化 | Matplotlib のサブプロット、二軸、Seaborn | 全体 |
課題 1:もっと多くのデータソースを追加する
ネットワーク API からデータ(例:サービス状態やキャンペーン流入)を取得し、コンバージョンへの影響を分析します。
# 例:モックのサービス状態データrng = np.random.default_rng(seed=42)service_status = pd.DataFrame({ 'date': pd.date_range('2024-01-01', '2024-12-31'), 'latency_ms': rng.normal(180, 35, 366).clip(40, None), 'incident': rng.choice([0, 0, 0, 1], 366) # 0=正常 1=インシデント})課題 2:Plotly でインタラクティブなダッシュボードを作る
import plotly.express as pxfrom plotly.subplots import make_subplots
# インタラクティブな月次トレンドfig = px.line(monthly, x='month', y='売上', title='月別売上トレンド', markers=True)fig.show()課題 3:PDF レポートを自動生成する
matplotlib の PdfPages または reportlab ライブラリを調べて、PDF 分析レポートを自動生成してみましょう。
課題 4:実データセットを使う
Kaggle で実際の EC データセット(例:Brazilian E-Commerce)を見つけて、このプロジェクトをやり直してみましょう。
十、プロジェクトチェックリスト
Section titled “十、プロジェクトチェックリスト”| チェック項目 | 完了したか |
|---|---|
| CSV から注文データを読み込む | ☐ |
| JSON から商品データを読み込む | ☐ |
| SQLite からユーザーデータを読み込む | ☐ |
| merge で 3 つの表を結合する | ☐ |
| 結合後のデータ品質を確認する | ☐ |
| 売上概要分析(カテゴリ、都市)を完了する | ☐ |
| 時間トレンド分析(月次、週内)を完了する | ☐ |
| ユーザー分析(RFM、セグメント分け)を完了する | ☐ |
| 総合ダッシュボード(大きな図)を作る | ☐ |
| 少なくとも 3 つの分析結果を書く | ☐ |
| 業務提案を出す | ☐ |
プロジェクト参考とレビュー観点
- 完成したプロジェクトでは、各データソースを読み込んだこと、結合キーを確認したこと、各 join の前後で行数を比較したこと、未一致レコードを調べたことを示します。
- 最終分析には、単なる 3 つのグラフではなく、ビジネスやプロダクト上の意味を持つ洞察を少なくとも 3 つ含めます。各洞察には支える表またはグラフが必要です。
- よい提案は、証拠、行動、リスクまたは前提を示します。単に「売上を伸ばす」ではなく、どのセグメントを、なぜ、何を監視するかまで書きます。
バージョンの進め方のおすすめ
Section titled “バージョンの進め方のおすすめ”| バージョン | 目標 | 仕上げのポイント |
|---|---|---|
| 基本版 | 最小の閉ループを動かす | 入力できる、処理できる、出力できる。さらに 1 組のサンプルを残す |
| 標準版 | 見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| チャレンジ版 | ポートフォリオ品質に近づける | 評価、比較実験、失敗サンプル分析、次の改善方針を追加する |
まずは基本版を完成させましょう。最初から大きく作り込みすぎないことが大切です。バージョンを 1 つ上げるたびに、「何が増えたか」「どう検証したか」「まだ何が課題か」を README に書き足していきましょう。
このページを終えたら、この evidence card を残します。
- 分析目標
- ビジネス/データの質問と成功基準
- データの証拠
- 取得元、クレンジングメモ、特徴量、図表の出力
- 結果
- 洞察、metric、dashboard、または report のセクション
- 失敗確認
- 汚れたデータ、偏ったサンプル、誤った集計、または再現不能な Notebook
- 期待される成果
- データ、図表、短いレポートを含む再現可能な分析フォルダ