7.1.3 単語埋め込みと意味表現
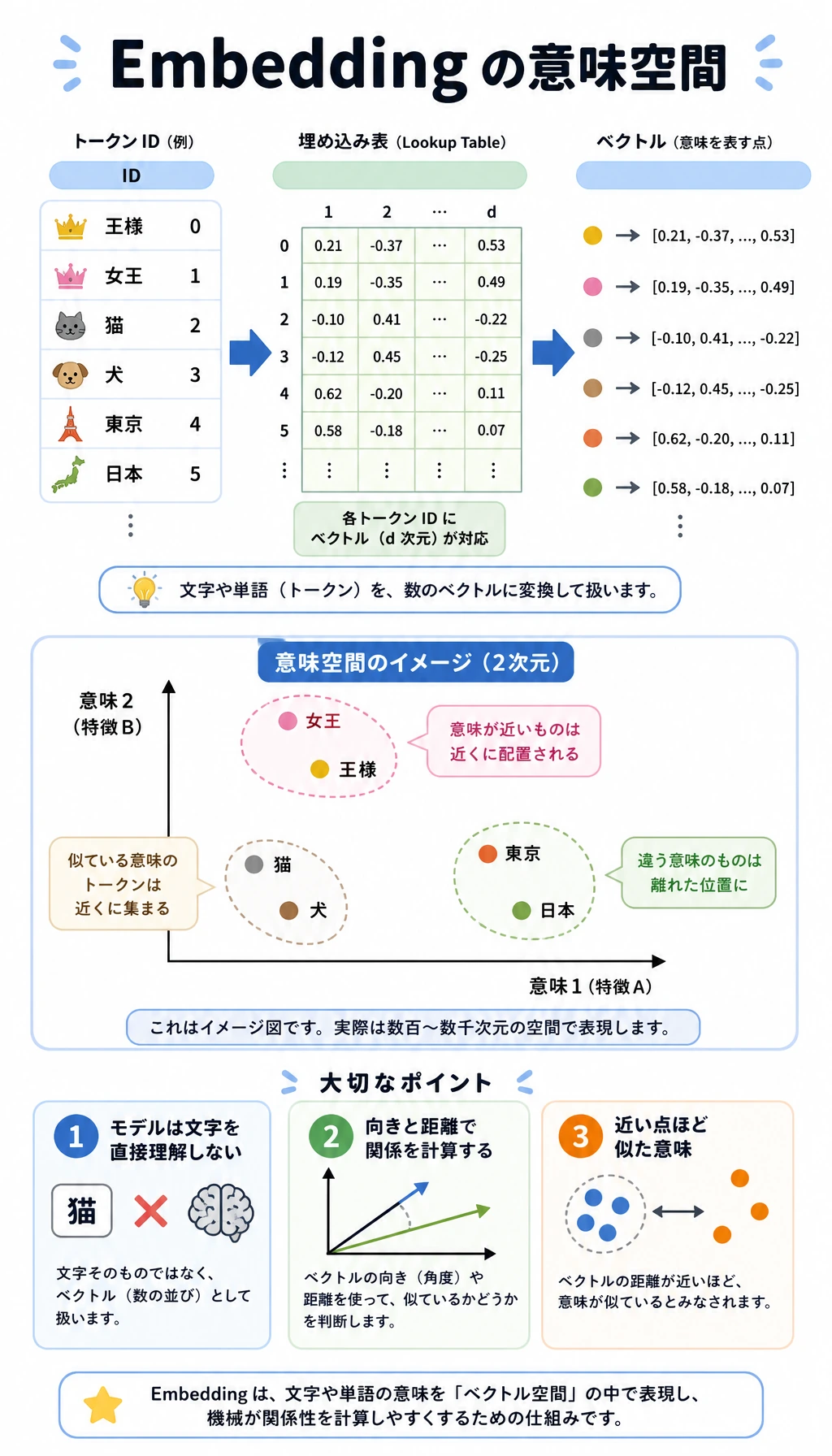
まずメンタルモデルを作る
Section titled “まずメンタルモデルを作る”One-hot ID は単語を区別できますが、どの単語が関連しているかは表せません。Dense embedding は token を vector space に置きます。
この空間では次のことができます。
- 近い vector は、関連した使われ方をしていることが多い。
- cosine similarity は方向の近さを測る。
- 文 vector は、token vector を pooling して作ることが多い。
- 文脈モデルでは、同じ token でも周囲の単語によって位置が変わる。
ワンホット表現(One-Hot)から密ベクトル(Dense Vector)へ
Section titled “ワンホット表現(One-Hot)から密ベクトル(Dense Vector)へ”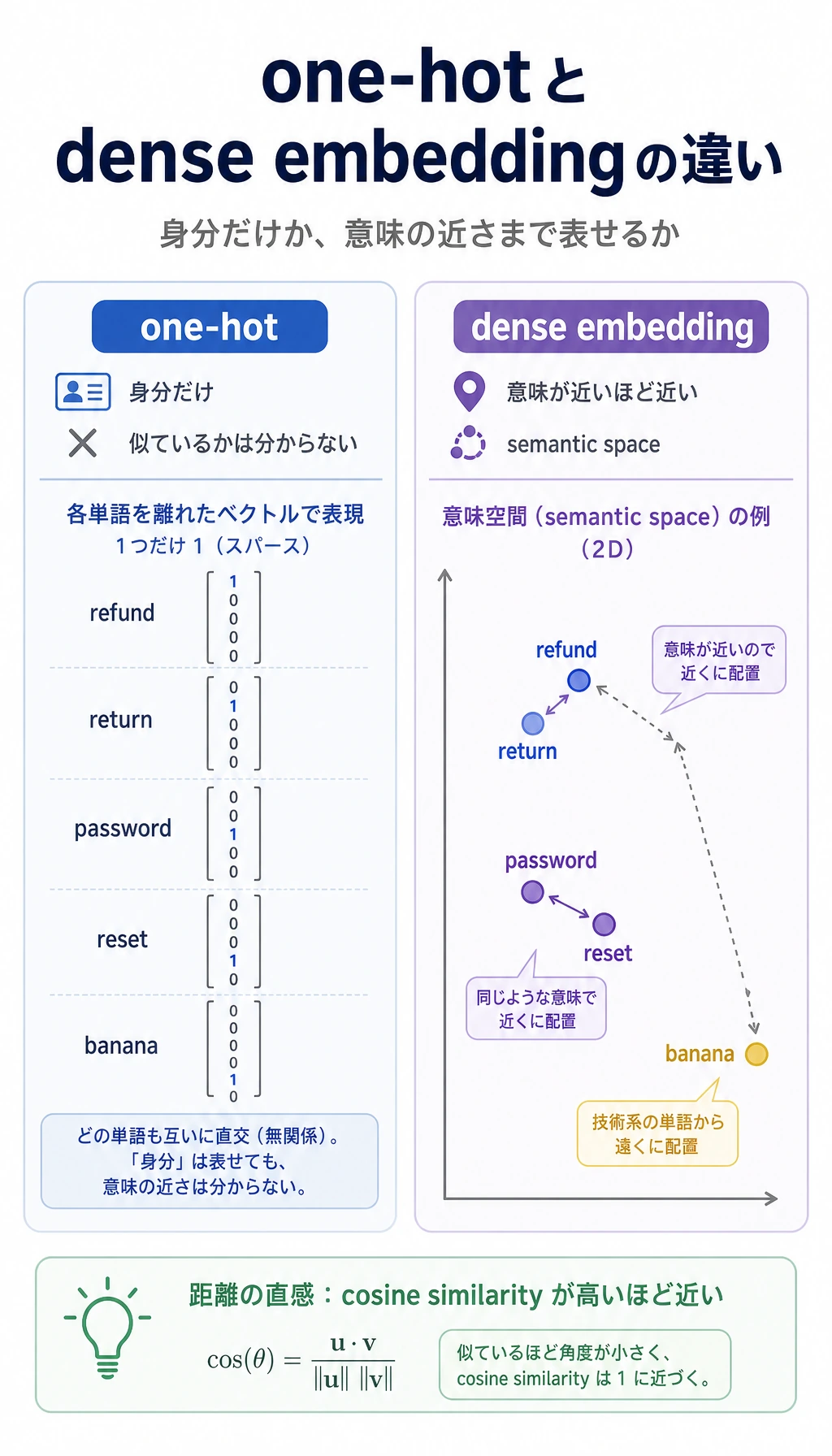
One-hot vector では、異なる単語はすべて同じように「違う」だけです。
refund -> [1, 0, 0, 0]return -> [0, 1, 0, 0]password -> [0, 0, 1, 0]coupon -> [0, 0, 0, 1]Dense vector では、より役に立つ幾何が表せます。
refund and return -> closepassword and reset -> closerefund and password -> farこの幾何は手作業のルールではなく、データから学習されます。似た文脈に出る単語は、近い vector になりやすいです。
実験 1:単語の類似度を比べる
Section titled “実験 1:単語の類似度を比べる”小さな embedding table を動かします。数字は学習用に手で作っていますが、操作は実際の vector retrieval と同じです。
from math import sqrt
embeddings = { "refund": [0.90, 0.80, 0.10], "return": [0.88, 0.78, 0.12], "password": [0.10, 0.20, 0.95], "reset": [0.12, 0.18, 0.92], "order": [0.75, 0.70, 0.15], "coupon": [0.05, 0.95, 0.10], "policy": [0.82, 0.74, 0.18],}
def cosine(a, b): dot = sum(x * y for x, y in zip(a, b)) norm_a = sqrt(sum(x * x for x in a)) norm_b = sqrt(sum(x * x for x in b)) return dot / (norm_a * norm_b)
print("refund vs return :", round(cosine(embeddings["refund"], embeddings["return"]), 3))print("refund vs password:", round(cosine(embeddings["refund"], embeddings["password"]), 3))print("password vs reset :", round(cosine(embeddings["password"], embeddings["reset"]), 3))期待される出力:
refund vs return : 1.0refund vs password: 0.293password vs reset : 1.0読み方:
- cosine が高いとは、方向が近いという意味で、完全に同じ意味ではない。
refundとreturnは、この玩具表ではカスタマーサポートの返金領域にある。passwordとresetはアカウント問題の領域にある。refundとpasswordは意図が違うので遠い。
実験 2:ミニ意味検索器を作る
Section titled “実験 2:ミニ意味検索器を作る”token vector を平均して文 vector を作り、query に対して 3 つの文書を順位付けします。
def mean_embedding(tokens): vectors = [embeddings[token] for token in tokens if token in embeddings] dim = len(vectors[0]) return [sum(vector[i] for vector in vectors) / len(vectors) for i in range(dim)]
query = mean_embedding(["reset", "password"])documents = { "A refund policy": ["refund", "policy"], "B password reset": ["password", "reset"], "C coupon return": ["coupon", "return"],}
ranked = sorted( ( (name, cosine(query, mean_embedding(tokens))) for name, tokens in documents.items() ), key=lambda item: item[1], reverse=True,)
for name, score in ranked: print(f"{name}: {score:.3f}")期待される出力:
B password reset: 1.000C coupon return: 0.335A refund policy: 0.333これが vector retrieval の基本です。
実際の RAG ではより強い embedding model と vector database を使いますが、考え方は similarity ranking です。
平均 vector は便利だが限界がある
Section titled “平均 vector は便利だが限界がある”Mean pooling は分かりやすい一方で、重要な情報を落とします。
- 語順
- 否定
- 強調
- 長距離依存
- どの token が重要か
たとえば玩具検索器では、reset password と password reset は同じになります。直感を作るには便利ですが、推論が必要なタスクには不十分です。
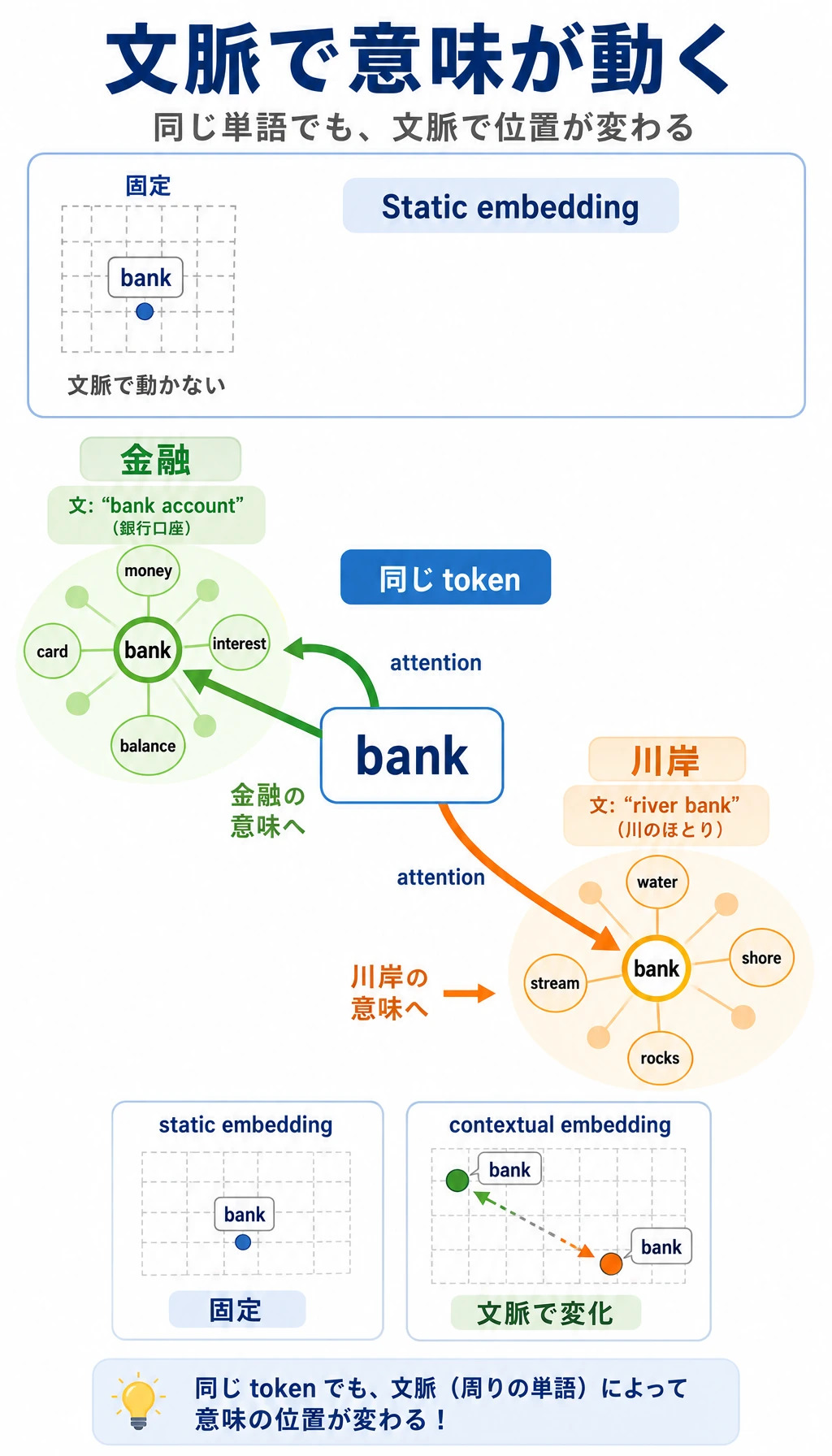
Static embedding は通常 1 単語に 1 vector です。文脈モデルでは、周囲の単語によって vector が変わります。
bank account -> bank は金融意味へ近づくriver bank -> bank は地理意味へ近づく小さなシミュレーションを動かします。
base_bank = [0.50, 0.50, 0.50]finance_context = [0.30, -0.10, 0.20]river_context = [-0.20, 0.25, -0.10]
bank_in_finance = [a + b for a, b in zip(base_bank, finance_context)]bank_in_river = [a + b for a, b in zip(base_bank, river_context)]
print("bank in finance:", [round(x, 2) for x in bank_in_finance])print("bank in river :", [round(x, 2) for x in bank_in_river])期待される出力:
bank in finance: [0.8, 0.4, 0.7]bank in river : [0.3, 0.75, 0.4]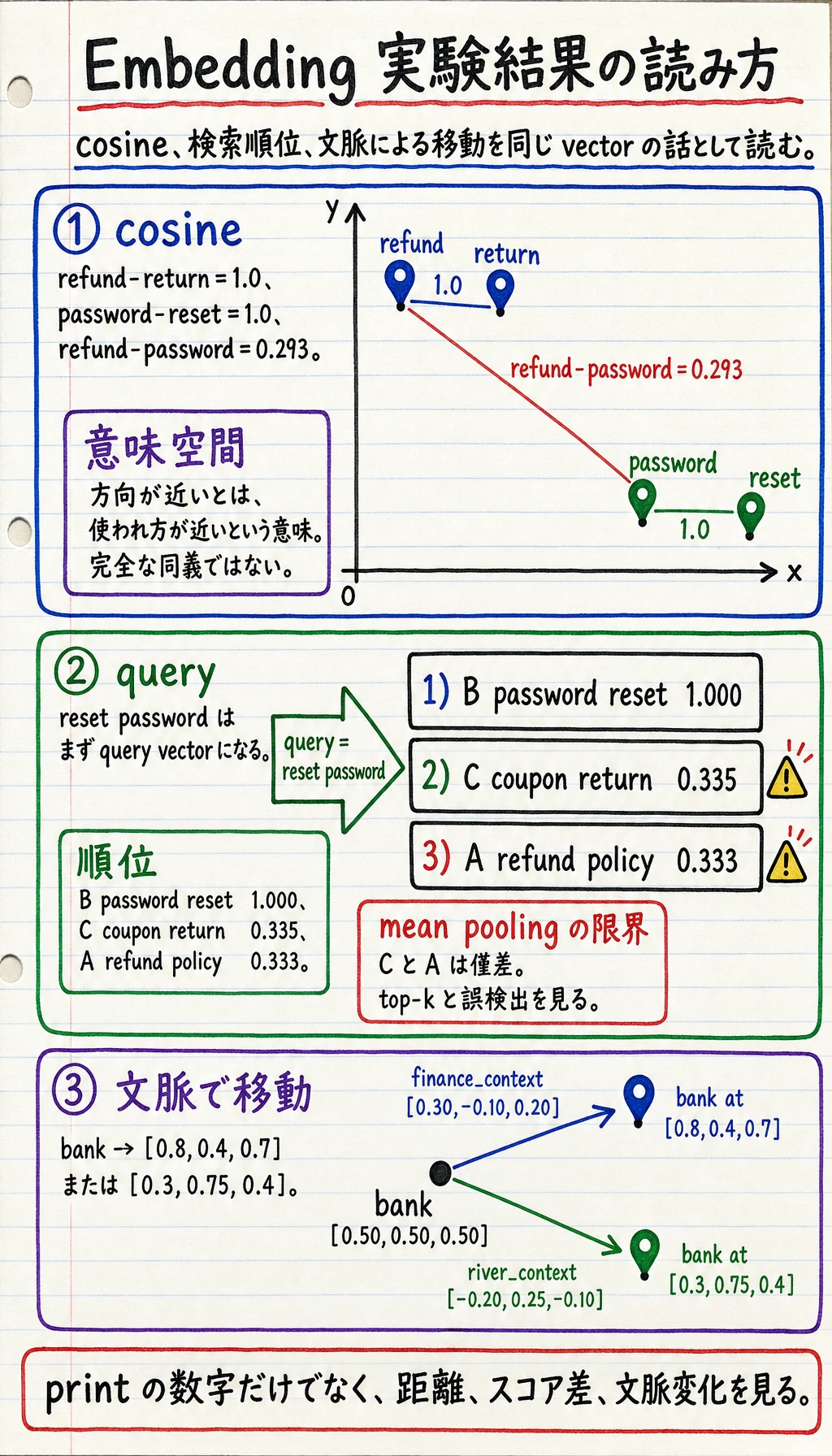
これは本物の Transformer ではありません。覚えるための小さな模型です。同じ token でも、文脈が混ざると別の表現になり得ます。
プロジェクトでの使い道
Section titled “プロジェクトでの使い道”| 用途 | embedding が提供するもの | 注意点 |
|---|---|---|
| RAG retrieval | 意味的に関連する chunk を探す | chunk や metadata が悪いと答えも悪くなる |
| FAQ clustering | 似た質問をまとめる | 近いことは重複と同じではない |
| Deduplication | 近似重複を探す | テンプレ文や言い換えでスコアが乱れる |
| Classification | テキストを特徴量にする | ラベル品質と calibration は別途必要 |
| Recommendation | user、item、クエリ を比較する | 人気バイアスが similarity を支配することがある |
デバッグチェックリスト
Section titled “デバッグチェックリスト”- ライブラリが自動でしない場合、cosine 前に vector を normalize する。
- top-1 だけでなく top-k スコアを出す。差が小さいなら retrieval は不確実。
- false positive を見る。関連語が必ず正解とは限らない。
- 同じデータで static、sentence、文脈依存 embedding を比較する。
- 多言語プロジェクトでは、言語間ペアを実測してからモデルを信頼する。
このページを終えたら、この証拠カードを残します。
- ベクトル
- 少なくとも 3 つのテキスト埋め込み、または小さな玩具ベクトル
- 類似性確認
- 最も近い組とスコア
- 検索結果
- 1つのクエリに対する上位一致
- 限界
- 平均化や類似度では文脈/否定/順序を見落とす
- 次の使い道
- これは Chapter 8 での retrieval の証拠になる
couponをpasswordに近づけると、検索はどう壊れるか。- 文書
D recover accountを追加し、recoverとaccountの vector を設計する。 - クエリ
refund orderを作る。どの文書が 1 位になるべきか。 doctorとhospitalが近くても同義語ではない理由を説明する。- RAG プロジェクトで embedding model が十分よいと示すには、どんな証拠を集めるか。
プロジェクト参考とレビュー観点
couponをpasswordに近づけると、account recovery の query に無関係な promotion や return-policy 文書が返るかもしれません。失敗は偶然ではなく、vector 空間の配置ミスです。recoverとaccountは、password や account support に近づけるべきです。無関係な promotion や return-policy とは離します。追加文書は account recovery query に合うはずです。- embedding 空間が refund intent と order の意味を捉えていれば、
refund orderは返金/注文関連文書を 1 位にすべきです。 doctorとhospitalは同じ domain によく現れるため近くなります。similarity は厳密な同義ではなく、topic 関連を表すことがあります。- 固定 query set、期待 top-k、retrieval score、既知の失敗例、latency、cost、言い換えに対する安定性を evidence として集めます。
Embedding は離散 token ID を幾何に変えます。
本当に大事なのは式そのものではありません。意味が、比較でき、順位付けでき、ニューラルネットワークへ渡せる形になることです。