9.2.6 高度なプランニング戦略【選択】
- 複雑なタスクで、なぜ線形ステップだけではなく依存グラフが必要なのかを理解する
- プランニングにおける並列性、クリティカルパス、リソース制約の役割を理解する
- 実行可能な例を通して、最小限の DAG スケジューラを理解する
- 高度なプランニングと、普通の Plan-and-Execute の違いを理解する
なぜ線形プランでは不十分なことがあるのか?
Section titled “なぜ線形プランでは不十分なことがあるのか?”現実のタスクでは「A のあとに B、B のあとに C」とは限らないから
Section titled “現実のタスクでは「A のあとに B、B のあとに C」とは限らないから”たとえば、調査レポートを作るとき、
次のような作業が必要かもしれません。
- 製品資料を集める
- ユーザーフィードバックを集める
- 過去データを読む
これらは、必ずしも完全に順番通りにやる必要はありません。
もし無理に一直線で書くと、
プランは次のようになりがちです。
- 長くなる
- 効率が悪くなる
- 本当の依存関係を表しにくい
高度なプランニングで最も大事な問題
Section titled “高度なプランニングで最も大事な問題”大事なのは「何ステップ書くか」ではなく、
次の点です。
- どのステップがどの前提条件に依存しているか
- どのステップを並行できるか
- どれがクリティカルパスか
つまり、高度なプランニングの対象は、
もっと次のものに近いです。
- タスクグラフ
たとえでいうと:作業メモではなく施工図
Section titled “たとえでいうと:作業メモではなく施工図”普通のプランは ToDo リストのようなものです。
高度なプランニングは、もっと施工図に近いです。
- どの工程を同時に始められるか
- どの工程は検査完了を待つ必要があるか
- どの工程の遅れが全体に影響するか
高度なプランニングでよく出る3つの概念
Section titled “高度なプランニングでよく出る3つの概念”タスク B が、タスク A の結果を待たないといけないなら、
次のように表せます。
A -> B
たとえば:
- 先にデータを収集してから、データをクリーンアップする
- 先に集計を終えてから、レポートを書く
2つのタスクが互いに依存していなければ、
理論上は同時に進められます。
これは次のことを意味します。
- 全体の所要時間を短くできる可能性がある
- ただし、スケジューリングはより複雑になる
クリティカルパス
Section titled “クリティカルパス”クリティカルパスとは、
次の意味です。
- 全体の所要時間を決める最長の依存チェーン
すべてのタスクが同じくらい重要なわけではありません。
全体の進行を本当に遅くするのは、たいていクリティカルパス上のノードです。
まずは本物の DAG スケジューリング例を動かしてみよう
Section titled “まずは本物の DAG スケジューリング例を動かしてみよう”次のコードは、とても代表的なことをします。
- タスクの依存関係と所要時間を与える
- 2人の ワーカー 制約のもとでスケジューリングする
- 各時刻に何が動いているかを出力する
これで、高度なプランニングでいちばん大事な直感がつかめます。
- プランは順番だけではなく、リソースと依存関係の組み合わせでもある
tasks = { "collect_policy_docs": {"deps": [], "duration": 2}, "collect_user_cases": {"deps": [], "duration": 3}, "summarize_policy": {"deps": ["collect_policy_docs"], "duration": 2}, "analyze_cases": {"deps": ["collect_user_cases"], "duration": 2}, "draft_report": {"deps": ["summarize_policy", "analyze_cases"], "duration": 2},}
def schedule(task_graph, workers=2): completed = set() running = [] timeline = [] time = 0
while len(completed) < len(task_graph): # まず、この時刻に終了するタスクを完了扱いにする just_finished = [task for task, end_time in running if end_time == time] if just_finished: for task in just_finished: completed.add(task) running = [(task, end_time) for task, end_time in running if end_time != time]
# 現在実行可能なタスクを見つける available = [] for task, meta in task_graph.items(): if task in completed: continue if any(task == running_task for running_task, _ in running): continue if all(dep in completed for dep in meta["deps"]): available.append(task)
# 空いている worker に割り当てる free_slots = workers - len(running) for task in available[:free_slots]: end_time = time + task_graph[task]["duration"] running.append((task, end_time))
timeline.append( { "time": time, "running": [task for task, _ in running], "completed": sorted(completed), } )
if len(completed) == len(task_graph): break
time += 1
return timeline
timeline = schedule(tasks, workers=2)for item in timeline: print(item)期待される出力:
{'time': 0, 'running': ['collect_policy_docs', 'collect_user_cases'], 'completed': []}{'time': 1, 'running': ['collect_policy_docs', 'collect_user_cases'], 'completed': []}{'time': 2, 'running': ['collect_user_cases', 'summarize_policy'], 'completed': ['collect_policy_docs']}{'time': 3, 'running': ['summarize_policy', 'analyze_cases'], 'completed': ['collect_policy_docs', 'collect_user_cases']}{'time': 4, 'running': ['analyze_cases'], 'completed': ['collect_policy_docs', 'collect_user_cases', 'summarize_policy']}{'time': 5, 'running': ['draft_report'], 'completed': ['analyze_cases', 'collect_policy_docs', 'collect_user_cases', 'summarize_policy']}{'time': 6, 'running': ['draft_report'], 'completed': ['analyze_cases', 'collect_policy_docs', 'collect_user_cases', 'summarize_policy']}{'time': 7, 'running': [], 'completed': ['analyze_cases', 'collect_policy_docs', 'collect_user_cases', 'draft_report', 'summarize_policy']}このコードで特に見るべきところは?
Section titled “このコードで特に見るべきところは?”細かい文法よりも、次の3点が大事です。
- タスクは線形リストではなく、
depsのグラフになっている - 依存条件を満たしたタスクだけが
availableに入る - ワーカー 数が並列度を制限する
この3つが合わさったものが、
高度なプランニングにおける現実的な制約です。
なぜ draft_report は最後でないといけないのか?
Section titled “なぜ draft_report は最後でないといけないのか?”なぜなら、draft_report は次に依存しているからです。
summarize_policyanalyze_cases
なので、たとえ worker がもっと多くても、
前提となる結果が出るまでは開始できません。
これは、高度なプランニングが「タスクが多ければ多いほど並列化できる」という話ではなく、
依存グラフそのものを見る必要があることを示しています。
ワーカー を 2 から 1 に変えたらどうなるか?
Section titled “ワーカー を 2 から 1 に変えたらどうなるか?”プランがかなり長くなるのが見えるはずです。
これは次の理解につながります。
- プランニングはロジックの問題だけではない
- リソースの問題でもある
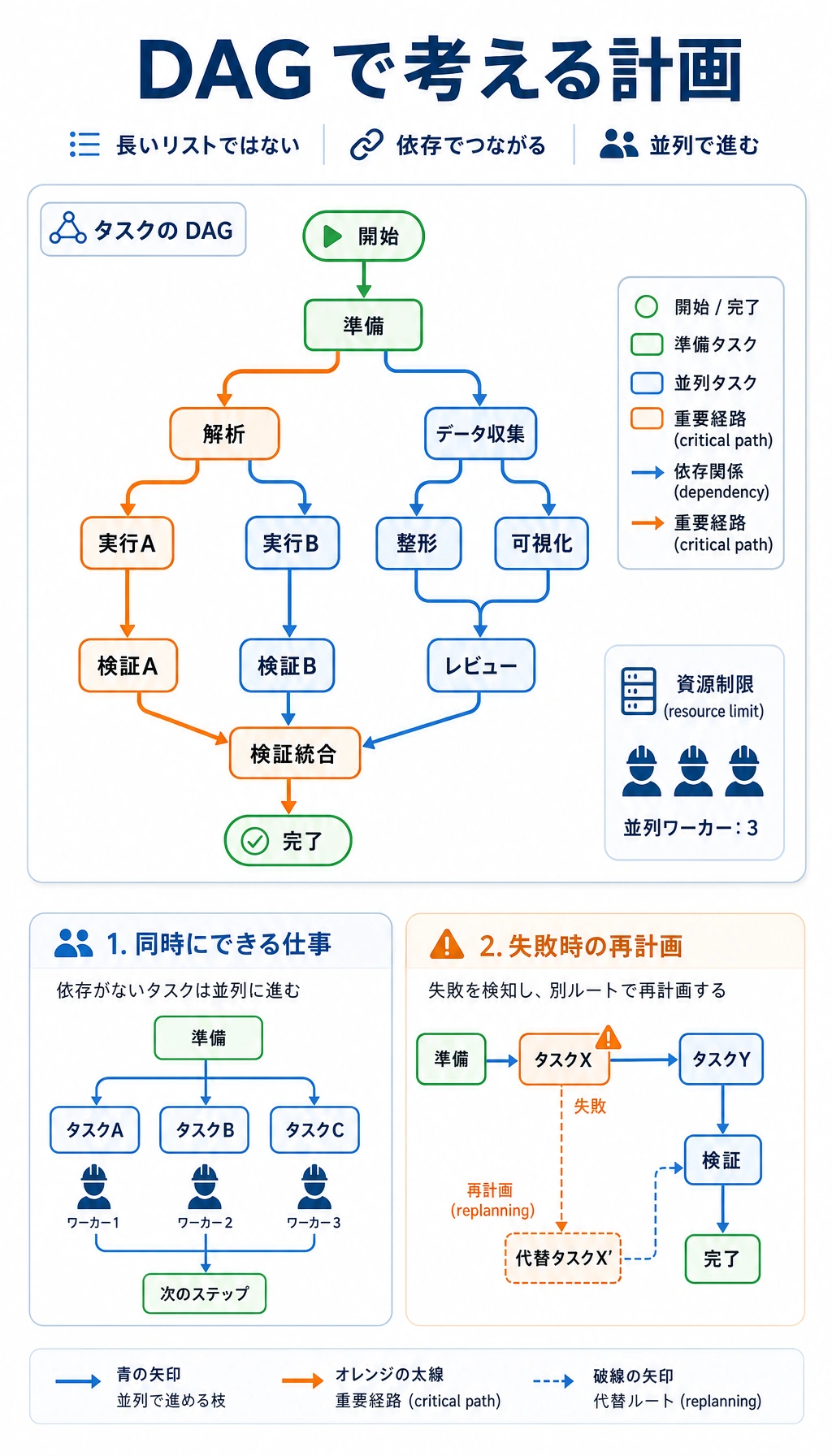
いつ高度なプランニングが必要で、いつ普通のプランで十分か?
Section titled “いつ高度なプランニングが必要で、いつ普通のプランで十分か?”タスクがもともとグラフ構造を持っているとき
Section titled “タスクがもともとグラフ構造を持っているとき”たとえば:
- 調査レポート
- 複数ソースのデータ集約
- 複雑なコード改修
- 複数ステップの業務承認
並列化で大きな効果が出るとき
Section titled “並列化で大きな効果が出るとき”タスクの中に独立した前提作業が多いなら、
高度なプランニングによって次の点が見えやすくなります。
- どのタスクを並列にすべきか
- どの待ち時間が避けられないか
失敗復旧や再プランニングが重要なとき
Section titled “失敗復旧や再プランニングが重要なとき”複雑なタスクでは、次のようなことがよく起こります。
- あるノードが失敗する
- 新しい観察で元のプランが崩れる
- ある前提条件がもう成り立たない
このときシステムには、ただ「プランがある」だけでなく、
次のことも必要です。
- 局所的な再計算
- 局所的な巻き戻し
- 局所的な再プランニング
なぜ高度なプランニングは「リスト化」よりも「グラフ探索」に近いのか?
Section titled “なぜ高度なプランニングは「リスト化」よりも「グラフ探索」に近いのか?”理由は、経路が1つとは限らないから
Section titled “理由は、経路が1つとは限らないから”複雑なタスクには、唯一の正解がないことがよくあります。
次のような選択肢があるかもしれません。
- タスクの分け方が複数ある
- リソースの割り当て方が複数ある
- 実行順序が複数ある
理由は、コスト関数を考える必要があるから
Section titled “理由は、コスト関数を考える必要があるから”ときには、最適化したいのは次のようなものです。
- 総所要時間
- 総コスト
- 最小リスク
目標が違えば、選ばれるプランも変わります。
理由は、「最適なプラン」が環境で変わるから
Section titled “理由は、「最適なプラン」が環境で変わるから”もしあるツールが遅くなったり、あるリソースが使えなくなったりしたら、
もともとの最適グラフは最適ではなくなるかもしれません。
だからこそ、高度なプランニングでは次のものが重要になります。
- 動的スケジューリング
- オンライン再プランニング
実務でよくある落とし穴
Section titled “実務でよくある落とし穴”落とし穴1:依存グラフを描けばそれで終わり
Section titled “落とし穴1:依存グラフを描けばそれで終わり”グラフはスタート地点にすぎません。
さらに次のものを定義する必要があります。
- ノードの入力と出力
- 失敗時の処理
- ノードのリトライ方針
落とし穴2:並列は多ければ多いほど良い
Section titled “落とし穴2:並列は多ければ多いほど良い”並列化すると、次のような問題が増えます。
- スケジューリングの複雑さ
- リソース競合
- 状態同期の問題
無制限に並列化すれば、必ず良くなるわけではありません。
落とし穴3:高度なプランニングは常に単純なプランより優れている
Section titled “落とし穴3:高度なプランニングは常に単純なプランより優れている”タスクが短くて固定的なら、
高度なプランニングは逆に過剰設計に見えることがあります。
このページを終えたら、この証拠カードを残します。
- タスク目標
- Agent が解決しようとしていること
- 計画またはトレース
- 推論手順、計画、ReAct trace、または実行グラフ
- 観察
- 各アクションの後に何が変わったか
- 失敗確認
- 幻覚のステップ、古い観測、ループ、または未検証の結論
- 評価アクション
- 期待結果と比較して計画を修正する
この節でいちばん大事なのは、DAG という言葉を覚えることではありません。
もっと大事なのは、次の現実的な見方を持つことです。
タスクに依存関係、並列性、リソース制約があるなら、プランニングの中心は長いリストを書くことではなく、タスクをグラフとして整理し、そのグラフに沿ってスケジューリングすることになる。
この理解が身につくと、
後で次の内容を見るときも、ずっと自然に理解できます。
- マルチ Agent の協調
- ワークフローのオーケストレーション
- スケジューラ設計
- 例の ワーカー 数を
1と3に変えて、タイムラインの違いを比べてみましょう。 - タスクグラフに
review_reportノードを追加し、draft_reportの後ろにつないで、スケジューリングの変化を観察しましょう。 - なぜ「並行できる」ことは「極限まで並行すべき」という意味ではないのでしょうか?
- 自分がよく知っている複雑なタスクを1つ思い浮かべ、それを依存グラフとして描いてみましょう。
参考実装と解説
- worker が 1 つならタスクはほぼ直列になり、critical path は見えやすい一方で遅くなります。3 つなら独立タスクは早く終わりますが、調整と review のリスクも増えます。
draft_reportの後にreview_reportを追加すると依存チェーンが長くなり、承認済みレポートを必要とする下流タスクが遅れる可能性があります。- 極端な並列化は、コンテキスト切り替え、マージ衝突、重複作業、品質管理の負荷を増やします。明確に独立していて責任範囲が分かれている作業だけを並列化します。
- 良い依存グラフは、独立タスク、ブロッキングタスク、review gate、最終統合を分けて表します。