7.2.1 LLM 概要ロードマップ:能力、コスト、プロダクト適性
LLM 概要はモデル名リストではありません。大規模モデルに何ができ、何にコストがかかり、prompt、RAG、Agent、fine-tuning のどれが合うかを判断するための章です。
まず能力スタックを見る
Section titled “まず能力スタックを見る”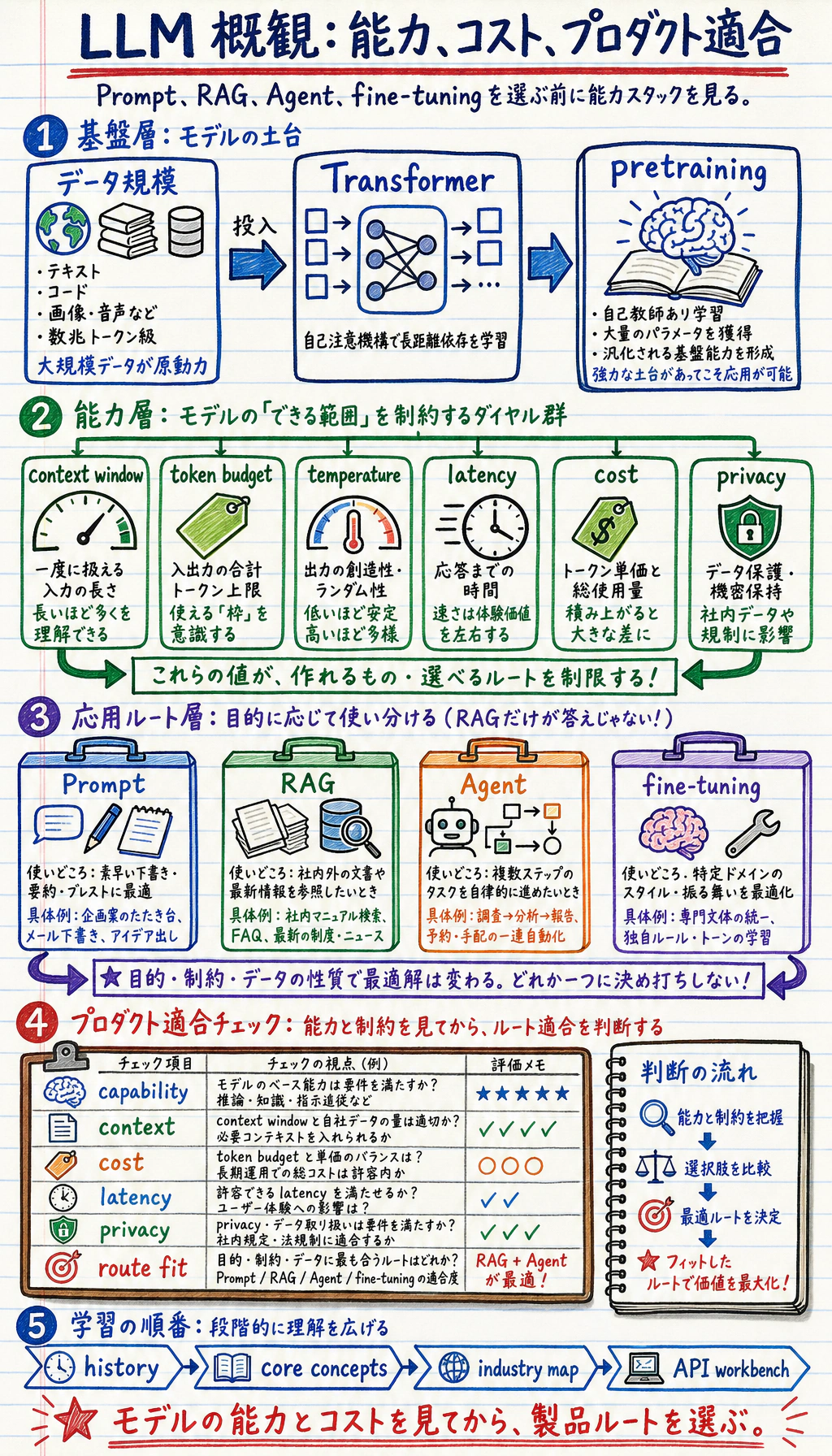

| ルート | 向いている場面 |
|---|---|
| prompt | モデルが十分知っていて、タスクが単純 |
| RAG | 私有知識や変化する知識を引用したい |
| Agent | ツール利用や複数ステップの行動が必要 |
| fine-tuning | 振る舞い、文体、形式を繰り返し適応したい |
ルート判断を一度動かす
Section titled “ルート判断を一度動かす”request = { "needs_private_docs": True, "needs_tool_action": False, "needs_repeated_style": False,}
if request["needs_tool_action"]: route = "Agent"elif request["needs_private_docs"]: route = "RAG"elif request["needs_repeated_style"]: route = "fine-tuning"else: route = "prompt"
print("recommended_route:", route)期待される出力:
recommended_route: RAG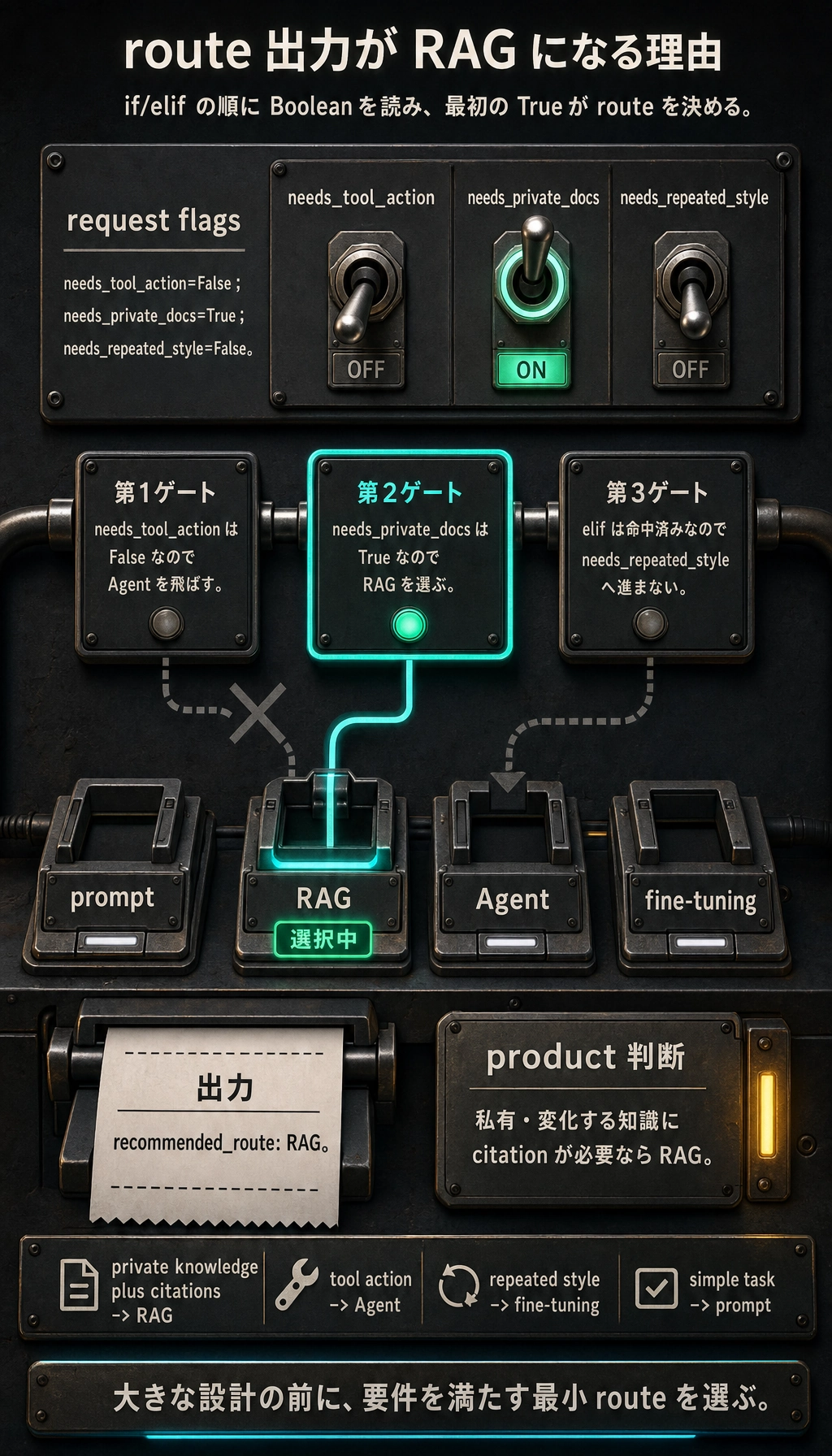
これは完全な設計判断ではありません。実際のプロダクト要件を満たす最小ルートを選ぶ練習です。
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | 残すもの |
|---|---|---|
| 1 | 7.2.2 発展史 | scaling と instruction tuning がなぜ重要か |
| 2 | 7.2.3 コア概念 | コンテキスト、token、temperature、遅延、コスト |
| 3 | 7.2.4 業界地図 | モデル/プロバイダ選択メモ |
| 4 | 7.2.5 LLM 呼び出しワークベンチ | 1つの request/response 記録 |
このページを終えたら、この証拠カードを残します。
- 機能スタック
- tokens、context、pretraining、instruction、alignment
- コスト確認
- 文脈長と出力長がコスト/レイテンシに影響する
- 製品適合
- 話題性ではなく、タスク要件でモデルの振る舞いを選ぶ
- 評価ループ
- 固定ケース、スコア、失敗メモ
- 次の行動
- 概要を 7.5 の Prompt テストにつなげる
能力、context、コスト、遅延、データプライバシー、ルート適性からモデル選択を1つ説明できれば合格です。
確認の考え方と解説
- 合格レベルの答えでは、token、context、attention、prompt、生成挙動が1回の request-response path でどうつながるかを説明します。
- 証拠には、再現できる prompt または structured-output test を1つ残し、出力が通った理由または失敗した理由を書きます。
- prompt 設計、RAG、fine-tuning、alignment を切り分け、観察した問題を直す最も軽い方法を選べれば十分です。