9.2.4 ReAct フレームワーク
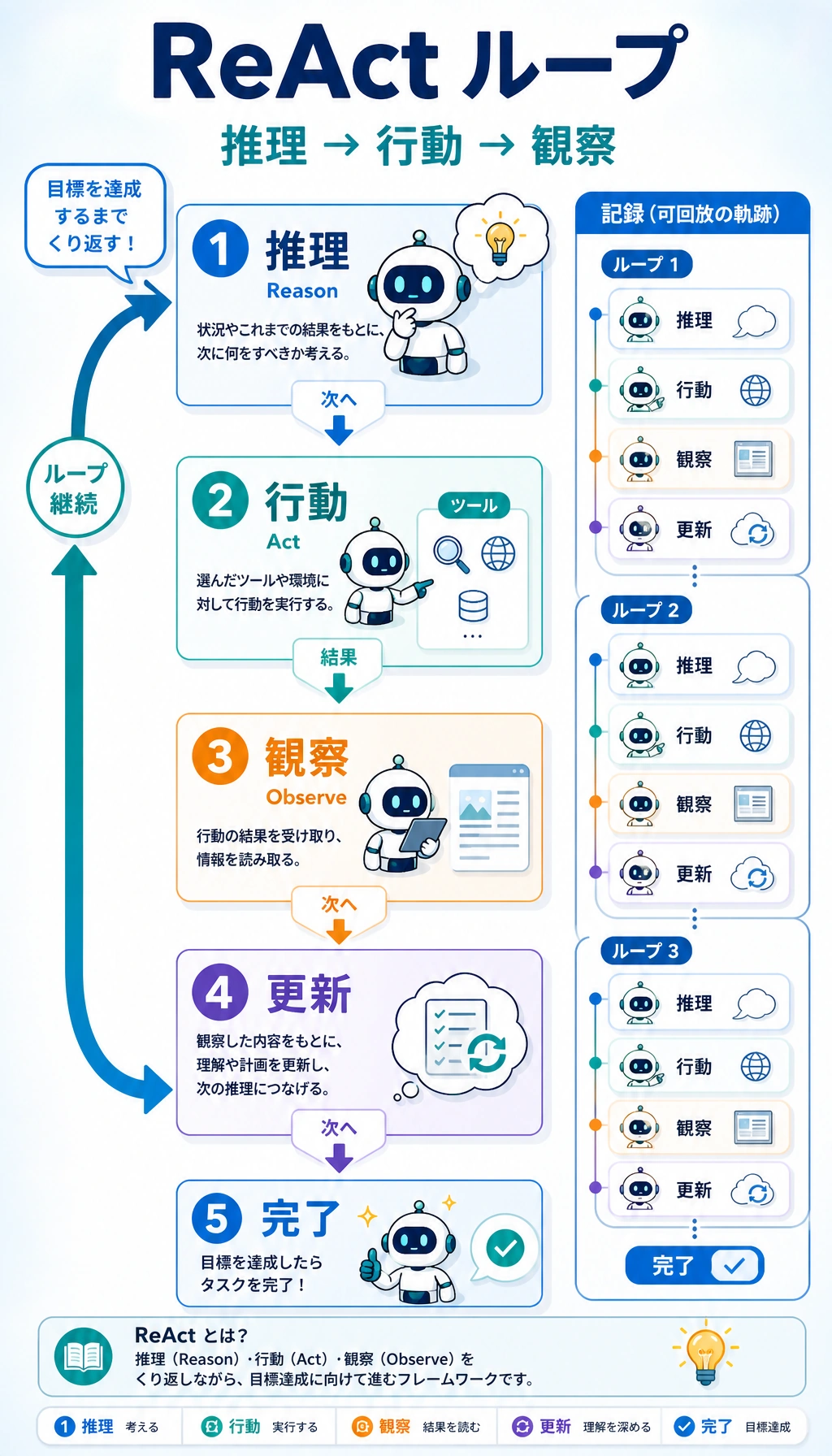
- ReAct の基本ループ:
Thought -> Action -> Observationを理解する - 純粋な CoT との違いを理解する
- 実行できる例を通して、最小限の ReAct agent loop を理解する
- ReAct がどんな問題に向いていて、どんなときに重くなりやすいかを理解する
なぜ「考える」だけでは足りないのか?
Section titled “なぜ「考える」だけでは足りないのか?”多くの答えはモデルの頭の中にないから
Section titled “多くの答えはモデルの頭の中にないから”例えば:
- 今日の北京の天気はどう?
- ある注文はいまどんな状態?
- この 2 つの数の正確な合計はいくら?
これらの問題はすべて次に依存します:
- リアルタイムの外部情報
- 正確なツール能力
モデルが自分だけで「推測」すると、
次のような問題が起きます:
- 幻覚
- 過度な自信
- 計算ミス
ReAct の本質:考えながら新しい情報を取りに行く
Section titled “ReAct の本質:考えながら新しい情報を取りに行く”典型的な循環は次のとおりです:
Thought
今、自分に足りない情報は何か?Action
どのツールを呼ぶべきか?Observation
ツールは何を返したか?- もう一度思考に戻る
これにより Agent は、もはや「答えを頭の中で補う」だけではなく、
少しずつ現実の環境に近づいていけます。
たとえるなら:閉じこもって文章を書くのではなく、調査する感じ
Section titled “たとえるなら:閉じこもって文章を書くのではなく、調査する感じ”純粋な CoT は、下書き用の紙の上で問題を解くようなものです。
ReAct は、むしろ調査に近いです:
- まず何を調べるべきか考える
- 証拠を取りに行く
- その証拠をもとに、さらに判断する
ReAct と CoT の根本的な違い
Section titled “ReAct と CoT の根本的な違い”CoT は「内部推論」が中心
Section titled “CoT は「内部推論」が中心”中心となる問いは:
- どうやって手順を分解するか
- どうやって途中状態を保つか
ReAct は「推論 + 外部とのやり取り」が中心
Section titled “ReAct は「推論 + 外部とのやり取り」が中心”さらに次の層があります:
- いつ外部に情報を取りに行くべきか
そのため ReAct は、次のようなイメージに近いです:
- CoT + ツールループ
なぜ Agent にとって特に重要なのか?
Section titled “なぜ Agent にとって特に重要なのか?”Agent は静的な Q&A をするだけではないからです。
よく次のようなことをします:
- ナレッジベースを検索する
- データベースを呼び出す
- 計算する
- コマンドを実行する
これらはすべて、思考の途中で外部世界につながることを必要とします。
まずは本物の ReAct 最小ループを動かしてみよう
Section titled “まずは本物の ReAct 最小ループを動かしてみよう”次の例では、小さな EC アシスタントをシミュレーションします。
ユーザーの質問は:
- 返金ルールは何ですか?
- 注文金額
299 + 15の最終返金額はいくらですか?
Agent は次の順で動く必要があります:
- まず返金ポリシーを確認する
- 次に計算機を呼ぶ
- 最後に答えをまとめる
import astimport operator
OPS = { ast.Add: operator.add, ast.Sub: operator.sub, ast.Mult: operator.mul, ast.Div: operator.truediv,}
def safe_calculate(expression): def visit(node): if isinstance(node, ast.Expression): return visit(node.body) if isinstance(node, ast.Constant) and isinstance(node.value, (int, float)): return node.value if isinstance(node, ast.BinOp) and type(node.op) in OPS: return OPS[type(node.op)](visit(node.left), visit(node.right)) if isinstance(node, ast.UnaryOp) and isinstance(node.op, ast.USub): return -visit(node.operand) raise ValueError("unsupported_expression")
return visit(ast.parse(expression, mode="eval"))
def search_policy(topic): policies = { "refund": "未発送の注文はそのまま返金申請できます。返金は元の支払い方法に戻り、通常 3〜7 営業日で着金します。", } return policies.get(topic, "関連するポリシーが見つかりません。")
def calculator(expression): return str(safe_calculate(expression))
def policy(state): trace = state["trace"] question = state["question"]
if not any(item["action"] == "search_policy" for item in trace): return { "thought": "まず返金ポリシーを確認して、ルール部分に答える必要がある。", "action": "search_policy", "args": {"topic": "refund"}, }
if not any(item["action"] == "calculator" for item in trace): return { "thought": "ポリシーは分かった。次は返金額 299 + 15 を計算する。", "action": "calculator", "args": {"expression": "299 + 15"}, }
policy_text = next(item["observation"] for item in trace if item["action"] == "search_policy") amount = next(item["observation"] for item in trace if item["action"] == "calculator")
return { "thought": "情報は十分そろったので、最終回答を出せる。", "action": None, "answer": f"{policy_text} この注文の予想返金額は {amount} 円です。", }
TOOLS = { "search_policy": search_policy, "calculator": calculator,}
def run_react(question, max_steps=5): state = {"question": question, "trace": []}
for _ in range(max_steps): decision = policy(state)
if decision["action"] is None: return state["trace"], decision["answer"]
tool_name = decision["action"] observation = TOOLS[tool_name](**decision["args"])
state["trace"].append( { "thought": decision["thought"], "action": tool_name, "args": decision["args"], "observation": observation, } )
return state["trace"], "最大ステップ数に達したため、タスクを完了できませんでした。"
trace, answer = run_react("返金ルールは何ですか?注文金額 299 + 15 の最終返金額はいくらですか?")
print("trace:")for item in trace: print(item)print("\nfinal answer:")print(answer)期待される出力:
trace:{'thought': 'まず返金ポリシーを確認して、ルール部分に答える必要がある。', 'action': 'search_policy', 'args': {'topic': 'refund'}, 'observation': '未発送の注文はそのまま返金申請できます。返金は元の支払い方法に戻り、通常 3〜7 営業日で着金します。'}{'thought': 'ポリシーは分かった。次は返金額 299 + 15 を計算する。', 'action': 'calculator', 'args': {'expression': '299 + 15'}, 'observation': '314'}
final answer:未発送の注文はそのまま返金申請できます。返金は元の支払い方法に戻り、通常 3〜7 営業日で着金します。 この注文の予想返金額は 314 円です。
このコードはどう読むべき?
Section titled “このコードはどう読むべき?”次の順で読むのがおすすめです:
- まず
policyを見る
agent が各ラウンドでどうやって「次に何をするか」を決めるかを理解する - 次に
TOOLSを見る
外部能力がどこから来るかを理解する - 最後に
run_reactを見る
完全なループがどのように trace を少しずつ積み上げるかを理解する
なぜ trace がそんなに重要なのか?
Section titled “なぜ trace がそんなに重要なのか?”ReAct は一度で答えを出すのではなく、
段階的に進むからです。
trace があれば、次のことが分かります:
- 何を考えたか
- 何を呼んだか
- 何を見たか
- なぜ最後にその答えになったか
これはデバッグでとても重要です。
なぜ ReAct は「ツールを一回直接呼ぶ」より強いことが多いのか?
Section titled “なぜ ReAct は「ツールを一回直接呼ぶ」より強いことが多いのか?”現実の問題は、たいてい 1 ステップでは終わらないからです。
ツールを呼ぶ順番は、前のステップの結果に左右されることがあります。
たとえばこの例では:
- まずポリシーを確認する
- 次に金額を計算する
- 最後に答えを組み立てる
これこそが ReAct の最も得意な形です。
ReAct はいつ最も有効か?
Section titled “ReAct はいつ最も有効か?”何度も観察が必要なタスク
Section titled “何度も観察が必要なタスク”例えば:
- 先に検索してから計算する
- 先に確認してから比較する
- 先に状態を見てから次の手を決める
ツール呼び出しの順番が固定ではない
Section titled “ツール呼び出しの順番が固定ではない”もし毎回のタスクが厳密に次の順なら:
- A を確認
- B を確認
- 出力
普通の workflow だけで十分かもしれません。
ReAct が向いているのは、次のような場合です:
- 今のステップの結果が、次のステップ選択に影響する
プロセスを追跡したい
Section titled “プロセスを追跡したい”ReAct には自然に次が含まれます:
- thought
- action
- observation
そのため次の用途にとても向いています:
- デバッグ
- 再生
- エラー分析
ReAct でよくある問題は何か?
Section titled “ReAct でよくある問題は何か?”ループが長くなりすぎる
Section titled “ループが長くなりすぎる”agent がずっと次を繰り返すと:
- 考える
- 呼ぶ
- また考える
- また呼ぶ
次のような問題が出ます:
- 遅い
- 高い
- ずれやすい
ツール選択を間違える
Section titled “ツール選択を間違える”ReAct は毎回正しいツールを選ぶとは限りません。
次のようなミスが起こりえます:
- 間違った情報源を検索する
- 同じ呼び出しを繰り返す
- 実は不要なツールを呼ぶ
Observation の統合に失敗する
Section titled “Observation の統合に失敗する”ツールが正しい情報を返しても、
agent が次のようにしてしまうことがあります:
- 重要なフィールドを無視する
- 結果を読み違える
- 最後のまとめを間違える
つまり ReAct の難しさは「ツールがあるかどうか」だけではなく、
「ツールの出力を正しく読めるか」にもあります。
実務ではどうやって ReAct を安定させるか?
Section titled “実務ではどうやって ReAct を安定させるか?”action スキーマ を分かりやすくする
Section titled “action スキーマ を分かりやすくする”ツールの説明が明確であるほど、
agent は迷いにくくなります。
最大ステップ数を制限する
Section titled “最大ステップ数を制限する”意味のないループを防ぐ最も簡単な方法の 1 つは:
max_stepsを明示すること
observation を構造化する
Section titled “observation を構造化する”ツールがごちゃごちゃした自然言語を大量に返すと、
agent は読み違えやすくなります。
より安定しやすいのは通常:
- 構造化されたフィールドを返すこと
例えば:
{"refund_days": "3-7", "channel": "original_payment"}
このページを終えたら、この証拠カードを残します。
- タスク目標
- Agent が解決しようとしていること
- 計画またはトレース
- 推論手順、計画、ReAct trace、または実行グラフ
- 観察
- 各アクションの後に何が変わったか
- 失敗確認
- 幻覚のステップ、古い観測、ループ、または未検証の結論
- 評価アクション
- 期待結果と比較して計画を修正する
よくある誤解
Section titled “よくある誤解”誤解 1:ReAct は「ツールを呼べる」こと
Section titled “誤解 1:ReAct は「ツールを呼べる」こと”それだけでは不十分です。
ReAct の大事な点は:
- 推論と行動を交互に進めること
誤解 2:トレース があれば必ず信頼できる
Section titled “誤解 2:トレース があれば必ず信頼できる”trace は追跡できますが、自動的に正しさを保証するわけではありません。
誤解 3:すべての Agent は ReAct を使うべき
Section titled “誤解 3:すべての Agent は ReAct を使うべき”そうとは限りません。
流れが非常に固定されているなら、
明示的な workflow のほうが簡単で、安定することもあります。
この節で最も大事なのは、ReAct を流行の言葉として覚えることではなく、
それがなぜ重要なのかを理解することです:
タスクが「考えながら外部世界から情報を取りに行く」必要があるとき、ReAct は「推論」と「行動」を組み合わせ、証拠を少しずつ集めながら答えに近づく循環を作れる。
この理解がしっかりしていれば、
次にもっと複雑な Agent の軌跡、ツール戦略、多段実行フレームワークを見るときも、ずっと理解しやすくなります。
- 例に
check_order_statusなどのツールを 1 つ追加して、agent にもう 1 ステップ判断させてみましょう。 - なぜ ReAct は「次の行動が前の observation に依存する」タスクに向いていると言えるのでしょうか?
- ツールの出力が乱雑なとき、なぜ ReAct は間違えやすいのでしょうか?
- 固定された ワークフロー には向いていて、ReAct にはあまり向いていないタスクを 1 つ考えてみましょう。
参考実装と解説
check_order_statusは新しい action の選択肢を増やし、次の判断を変える observation を返すようにします。- ReAct は、検索結果、ツールエラー、不足フィールド、権限結果、計算結果など、各 observation が次の計画を変えるタスクに向いています。
- ツール出力が乱雑だと observation を正しく解釈しにくくなり、次の action が誤ったシグナルに基づいて選ばれます。
- パスワードリセット、請求書作成、承認フローのように手順が厳密に決まっている処理は、開いた ReAct ループより固定ワークフローに向いています。