3.3.6 データ変換
apply、map、applymapの使い方と違いを理解する- 並び替え(sort_values)とランキング(rank)を学ぶ
- データの置換とマッピングを身につける
まずは全体像をつかもう
Section titled “まずは全体像をつかもう”データ変換は、「この列を最終的にどうしたいか」で考えると理解しやすいです。
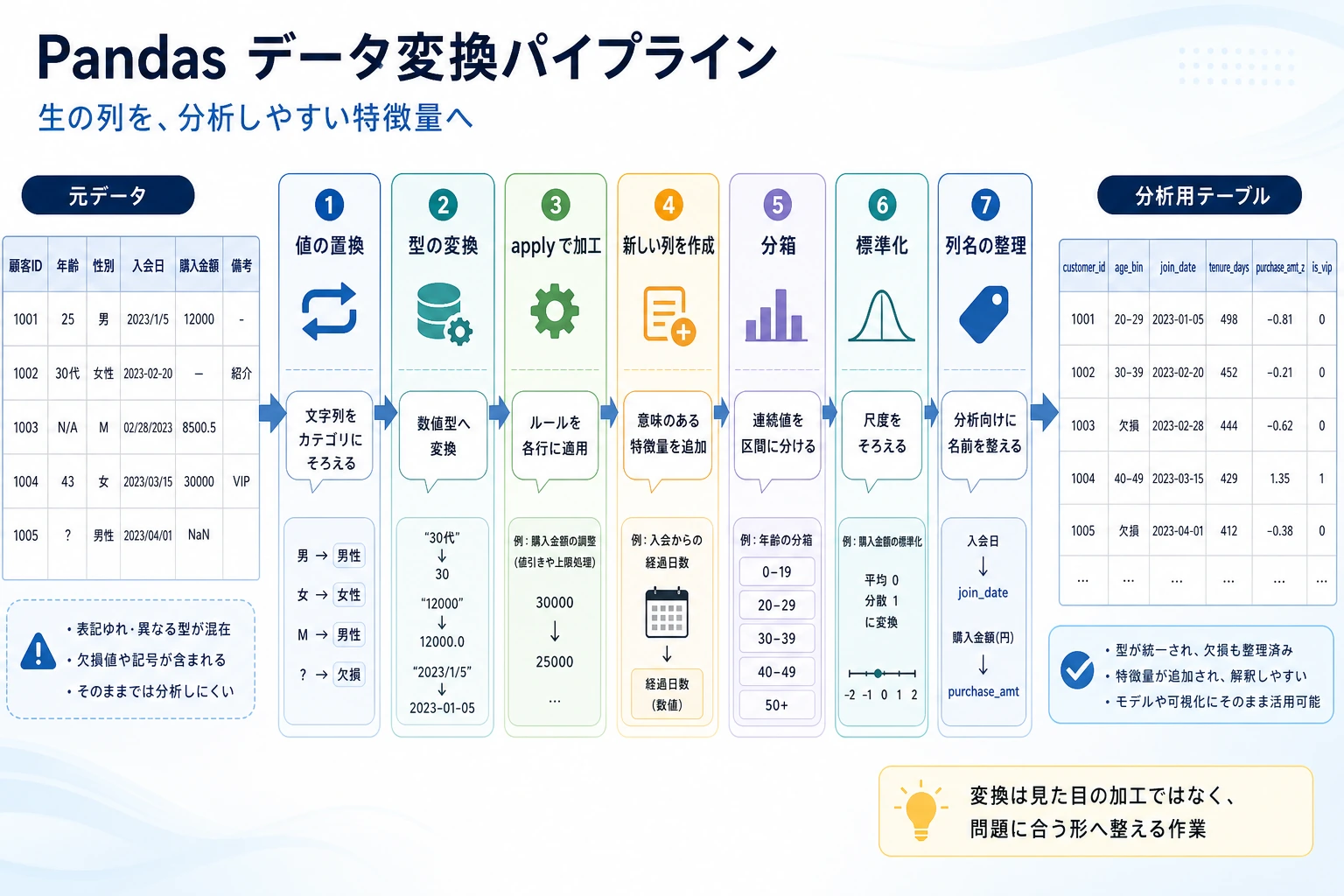
この節で本当に解決したいのは、次のことです。
- それぞれの変換操作が何を補ってくれるのか
- いつ
mapを先に思いつくべきか、いつapplyを先に思いつくべきか
apply:行や列に関数を適用する
Section titled “apply:行や列に関数を適用する”
apply は Pandas の中でもとても柔軟な変換ツールです。任意の関数を、各行または各列に適用できます。
新人向けの分かりやすいイメージ
Section titled “新人向けの分かりやすいイメージ”データ変換は、次のように考えると理解しやすいです。
- 元データに「翻訳」「加工」「再ラベル付け」をする
たとえば、やりたいことは次のように分かれます。
- コードを中文に変換したい
- 1行の中の複数列から新しい結果を計算したい
- 連続した数値を高・中・低の3段階に分けたい
見た目はどれも「変換」ですが、実際には別の種類の問題です。
Series に対して使う
Section titled “Series に対して使う”import pandas as pdimport numpy as np
df = pd.DataFrame({ "氏名": ["张三", "李四", "王五", "赵六"], "数学": [85, 92, 78, 95], "英语": [90, 88, 72, 85]})
# 単一列に組み込み関数を適用print(df["数学"].apply(np.sqrt)) # 各点数の平方根を求める
# 単一列にカスタム関数を適用def grade(score): if score >= 90: return "優秀" elif score >= 80: return "良好" elif score >= 70: return "普通" else: return "合格"
df["数学等级"] = df["数学"].apply(grade)print(df)
# lambda を使うとより簡潔df["英语等级"] = df["英语"].apply(lambda x: "合格" if x >= 60 else "不合格")DataFrame に対して行単位で適用する
Section titled “DataFrame に対して行単位で適用する”# axis=1 は各行に対して処理するという意味df["总分"] = df[["数学", "英语"]].apply(np.sum, axis=1)
# カスタムの行処理def student_info(row): return f"{row['氏名']}の数学は{row['数学']}点です"
df["描述"] = df.apply(student_info, axis=1)print(df[["氏名", "描述"]])apply を初めて学ぶとき、一番大事なのは?
Section titled “apply を初めて学ぶとき、一番大事なのは?”まず覚えるべきなのは、次の1点です。
applyは「既存の方法だけでは足りないときの、自作の計算」に向いている。
つまり、最初に思いつく道具というより、
- ルールが少し複雑で、組み込み関数だけでは対応しにくいときに使う
というイメージです。
map:値の対応付け
Section titled “map:値の対応付け”map は Series に対して使い、古い値を新しい値へ対応付けします。
df = pd.DataFrame({ "氏名": ["张三", "李四", "王五"], "性别": ["M", "F", "M"], "部署代码": [1, 2, 1]})
# 辞書で対応付けdf["性别中文"] = df["性别"].map({"M": "男", "F": "女"})
# 部門コードを対応付けdept_map = {1: "技術部", 2: "市場部", 3: "管理部"}df["部署名称"] = df["部署代码"].map(dept_map)
# 関数を使って対応付けdf["氏名长度"] = df["氏名"].map(len)
print(df)いつ map を先に思いつくとよい?
Section titled “いつ map を先に思いつくとよい?”頭の中で次のような対応関係を考えているときです。
- A コード -> A 名称
- M / F -> 男 / 女
- 月の省略形 -> 中国語の月名
このような「1つの値を別の1つの値へ変換する」関係なら、
まず map を思い出すとよいです。
map と apply の違い
Section titled “map と apply の違い”| 特性 | map | apply |
|---|---|---|
| 対象 | Series のみ | Series または DataFrame |
| 辞書マッピング対応 | ✅ | ❌ |
| 関数対応 | ✅ | ✅ |
| 行単位の処理 | ❌ | ✅(axis=1) |
replace:値を置き換える
Section titled “replace:値を置き換える”df = pd.DataFrame({ "城市": ["BJ", "SH", "GZ", "SZ", "BJ"], "等级": ["A", "B", "C", "A", "B"]})
# 単一値の置換df["城市"] = df["城市"].replace("BJ", "北京")
# 複数値の置換(辞書)city_map = {"SH": "上海", "GZ": "广州", "SZ": "深圳"}df["城市"] = df["城市"].replace(city_map)
print(df)map と replace はどこで混同しやすい?
Section titled “map と replace はどこで混同しやすい?”まずは次のように覚えると分かりやすいです。
mapは「対応付けして変換する」イメージreplaceは「特定の古い値をそのまま置き換える」イメージ
目的が、
- 一連のコードを名前に変換する
なら map に近いです。
一方で、ただ
- ある汚い値だけを別の値に直したい
なら replace に近いです。
sort_values:値で並び替える
Section titled “sort_values:値で並び替える”df = pd.DataFrame({ "氏名": ["张三", "李四", "王五", "赵六", "钱七"], "年龄": [22, 28, 25, 35, 21], "給与": [15000, 22000, 18000, 35000, 12000]})
# 薪資の昇順print(df.sort_values("給与"))
# 薪資の降順print(df.sort_values("給与", ascending=False))
# 複数列で並び替え:まず年齢の昇順、年齢が同じなら薪資の降順print(df.sort_values(["年龄", "給与"], ascending=[True, False]))
# 上位 3 件を取る(nlargest を使うのがおすすめ)print(df.nlargest(3, "給与"))
# 下位 3 件を取るprint(df.nsmallest(3, "給与"))sort_index:インデックスで並び替える
Section titled “sort_index:インデックスで並び替える”df_indexed = df.set_index("氏名")print(df_indexed.sort_index()) # 名前順に並べるprint(df_indexed.sort_index(ascending=False))rank:順位をつける
Section titled “rank:順位をつける”df = pd.DataFrame({ "氏名": ["张三", "李四", "王五", "赵六", "钱七"], "成绩": [85, 92, 78, 92, 88]})
# デフォルトの順位付け(同じ値は平均順位)df["排名"] = df["成绩"].rank(ascending=False)print(df)# 氏名 成绩 排名# 0 张三 85 4.0# 1 李四 92 1.5 ← 同率1位なので (1+2)/2# 2 王五 78 5.0# 3 赵六 92 1.5# 4 钱七 88 3.0
# いろいろな順位付けの方法df["最小排名"] = df["成绩"].rank(ascending=False, method="min") # 同率は最小順位df["最大排名"] = df["成绩"].rank(ascending=False, method="max") # 同率は最大順位df["密集排名"] = df["成绩"].rank(ascending=False, method="dense") # 飛び番なしprint(df[["氏名", "成绩", "排名", "最小排名", "密集排名"]])| method | 同順位の扱い | 例(92,92) |
|---|---|---|
average | 平均を取る | 1.5, 1.5 |
min | 最小順位を取る | 1, 1 |
max | 最大順位を取る | 2, 2 |
dense | 密な順位(飛び番なし) | 1, 1(次は 2) |
first | 出現順で決める | 1, 2 |
初学者がまず覚えるとよい選択表
Section titled “初学者がまず覚えるとよい選択表”| 今やりたいこと | まず思い浮かべたい方法 |
|---|---|
| コードを中文ラベルに変えたい | map |
| 1行の複数列から新しい結果を計算したい | apply(axis=1) |
| Top N を取りたい / 並び替えたい | sort_values / nlargest |
| 順位をつけたい | rank |
| 連続値を区間に分けたい | cut / qcut |
この表は、新人の方にとってとても役立ちます。 「変換方法はたくさんある」という状態を、よくある数個の問題に整理し直してくれるからです。
そのほかのよく使う変換
Section titled “そのほかのよく使う変換”値の出現回数を数える
Section titled “値の出現回数を数える”df = pd.DataFrame({ "部署": ["技術", "市場", "技術", "管理", "技術", "市場"]})
# 各値の出現回数print(df["部署"].value_counts())# 技術 3# 市場 2# 管理 1
# 割合print(df["部署"].value_counts(normalize=True))print(df["部署"].unique()) # ['技術' '市場' '管理']print(df["部署"].nunique()) # 3(ユニーク値の個数)ビン分割(cut / qcut)
Section titled “ビン分割(cut / qcut)”ages = pd.Series([18, 22, 25, 30, 35, 42, 55, 68])
# 固定区間で分けるbins = [0, 18, 30, 50, 100]labels = ["少年", "青年", "中年", "老年"]age_group = pd.cut(ages, bins=bins, labels=labels)print(age_group)
# 分位数で分ける(各グループの人数をできるだけ近くする)quartile_group = pd.qcut(ages, q=4, labels=["Q1", "Q2", "Q3", "Q4"])print(quartile_group)このページを終えたら、この evidence card を残します。
- データフレーム状態
- 列、dtype、行数、欠損値、サンプル行
- 操作
- read/write、select/filter、clean、transform、groupby、merge、または時系列処理
- 出力
- resulting table、保存ファイル、aggregation、join結果、または時系列インデックスビュー
- 失敗確認
- dtype 不一致、欠損データ、重複キー、チェーン代入、または誤った時間頻度
- 期待される成果
- 前後の表サンプルと、変換理由
| 操作 | 方法 | よくある用途 |
|---|---|---|
| 自作の変換 | apply() | 複雑な行単位・列単位の計算 |
| 値の対応付け | map() | 辞書による対応付け、コード変換 |
| 値の置換 | replace() | 間違った値の修正 |
| 並び替え | sort_values() | Top N、ランキング |
| 順位付け | rank() | 成績順位 |
| 値のカウント | value_counts() | カテゴリ集計 |
| 区間分け | cut() / qcut() | 年齢層、収入層 |
この節で一番持ち帰ってほしいこと
Section titled “この節で一番持ち帰ってほしいこと”- データ変換で大事なのは関数名を覚えることより、まず「データをどう変えたいか」をはっきりさせること
mapは対応付け、applyは自作の加工、というイメージを持つと分かりやすい- 並び替え、順位付け、ビン分割は、どれもデータの見せ方を整理し直す操作
やってみよう
Section titled “やってみよう”練習 1:データのマッピング
Section titled “練習 1:データのマッピング”# 英語の月名の省略形を含むデータを作る# 1. 月名の省略形を中国語に変換する# 2. 月を四半期(Q1, Q2, Q3, Q4)に変換する練習 2:順位付けの応用
Section titled “練習 2:順位付けの応用”# 20人の学生の3科目の成績 DataFrame を作る# 1. 合計点を計算する# 2. 合計点で順位をつける(密集順位)# 3. 合計点で並び替えて、上位5名を取る# 4. 各科目の点数にランクを付ける(優秀/良好/普通/合格/不合格)練習 3:ビン分割の練習
Section titled “練習 3:ビン分割の練習”# 100人のユーザーの消費金額データがある# 1. cut を使って消費金額を "低消費/中消費/高消費" の3段階に分ける# 2. qcut を使って5グループに均等分割する# 3. 各グループの人数と平均消費額を集計する参考実装と解説
- 月やカテゴリの再コード化は明示的な辞書を使い、
isna()やvalue_countsで未変換の値を確認します。気づかない未変換カテゴリは、集計ミスのよくある原因です。 - 売上の派生列は、乗算、
rank、sort_values、nlargestなどのベクトル化操作で、合計、順位、上位項目を計算します。 - ビン分けでは、業務上のしきい値が固定なら
cut、各グループの件数を近づけたいならqcutを使います。ラベルを解釈する前に必ず各グループの件数を表示します。