5.4.1 評価ロードマップ:チューニング前にスコアを信頼できるか見る
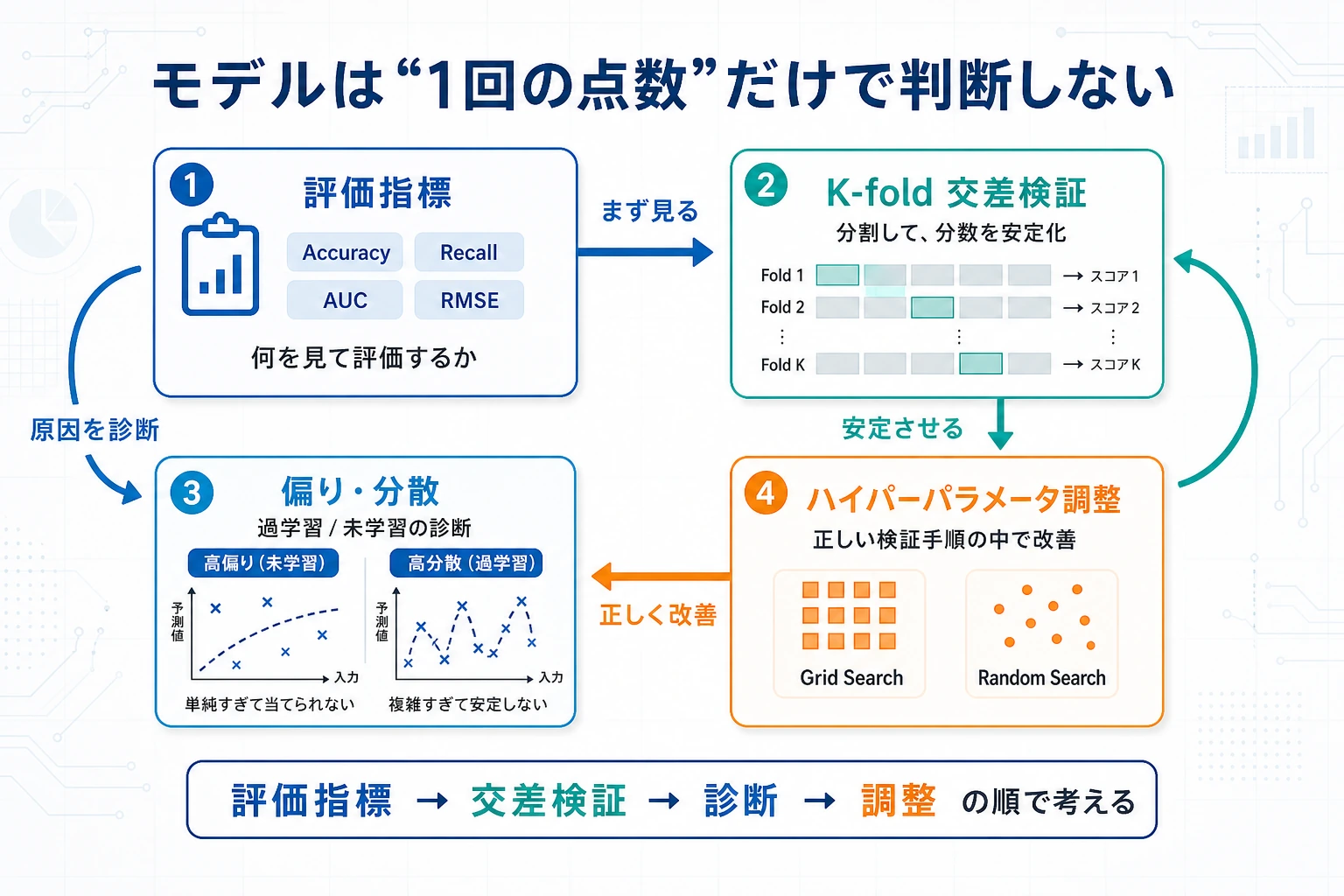
モデル評価は、モデルが本当に良いのか、それともたまたまスコアが良く見えただけなのかを確認します。
まず評価マップを見る
Section titled “まず評価マップを見る”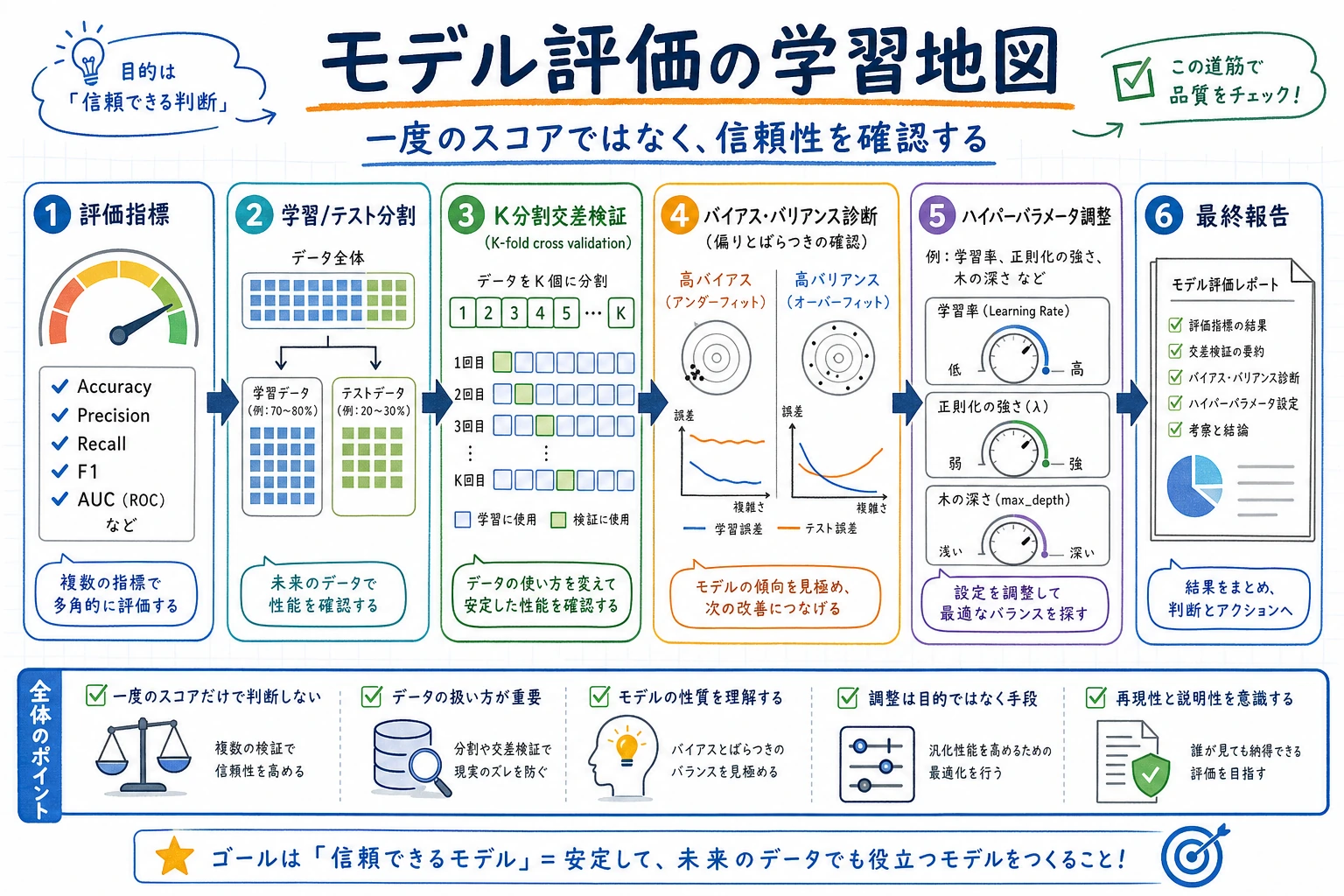
| テーマ | 最初に問うこと |
|---|---|
| 指標 | どのスコアがタスクに合うか |
| 交差検証 | 分割を変えてもスコアは安定するか |
| バイアスとバリアンス | モデルは単純すぎるか、柔軟すぎるか |
| チューニング | どのパラメータ変更が本当に良いか |
交差検証を一度動かす
Section titled “交差検証を一度動かす”evaluation_first_loop.py を作り、scikit-learn をインストールしてから実行します。
from sklearn.datasets import load_irisfrom sklearn.model_selection import cross_val_scorefrom sklearn.tree import DecisionTreeClassifier
X, y = load_iris(return_X_y=True)model = DecisionTreeClassifier(max_depth=2, random_state=42)scores = cross_val_score(model, X, y, cv=5)
print("fold_scores:", [float(round(score, 3)) for score in scores])print("mean_accuracy:", round(scores.mean(), 3))出力:
fold_scores: [0.933, 0.967, 0.9, 0.867, 1.0]mean_accuracy: 0.9331つのスコアはスナップショットです。複数 fold を見ると、信頼できるほど安定しているかがわかります。
このページを終えたら、この evidence card を残します。
- 評価設定
- 分割、交差検証、指標、ベースライン、比較対象
- 結果
- スコア表、曲線、confusion matrix、検証結果、または検索結果
- 判断
- データ、特徴量、モデル、閾値、またはハイパーパラメータを変えるかどうか
- 失敗確認
- リーク、不安定な検証、誤った指標、またはテストセットでのチューニング
- 期待される成果
- 次のモデリング判断を支える評価記録
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | 練習すること |
|---|---|---|
| 1 | 5.4.2 評価指標 | accuracy、precision、recall、F1、R2、RMSE |
| 2 | 5.4.3 交差検証 | 安定した見積もり、データ分割リスク |
| 3 | 5.4.4 バイアスとバリアンス | 未学習、過学習、学習曲線 |
| 4 | 5.4.5 ハイパーパラメータ調整 | グリッドサーチ、比較記録 |
タスクに合う指標を選び、スコア安定性チェックを1つ説明し、評価方法が信頼できない段階で急いでチューニングしなければ合格です。
確認の考え方と解説
- モデル調整の前に、タスク目標とミスのコストから指標を選びます。
- 交差検証は、分割を変えてもスコアが安定するかを確認します。たまたま良かった 1 回の分割だけでは十分な証拠になりません。
- 最終 test set で調整してはいけません。比較記録には baseline、指標、検証方法、結果、次の判断を残します。