7.2.2 大規模モデルの発展史
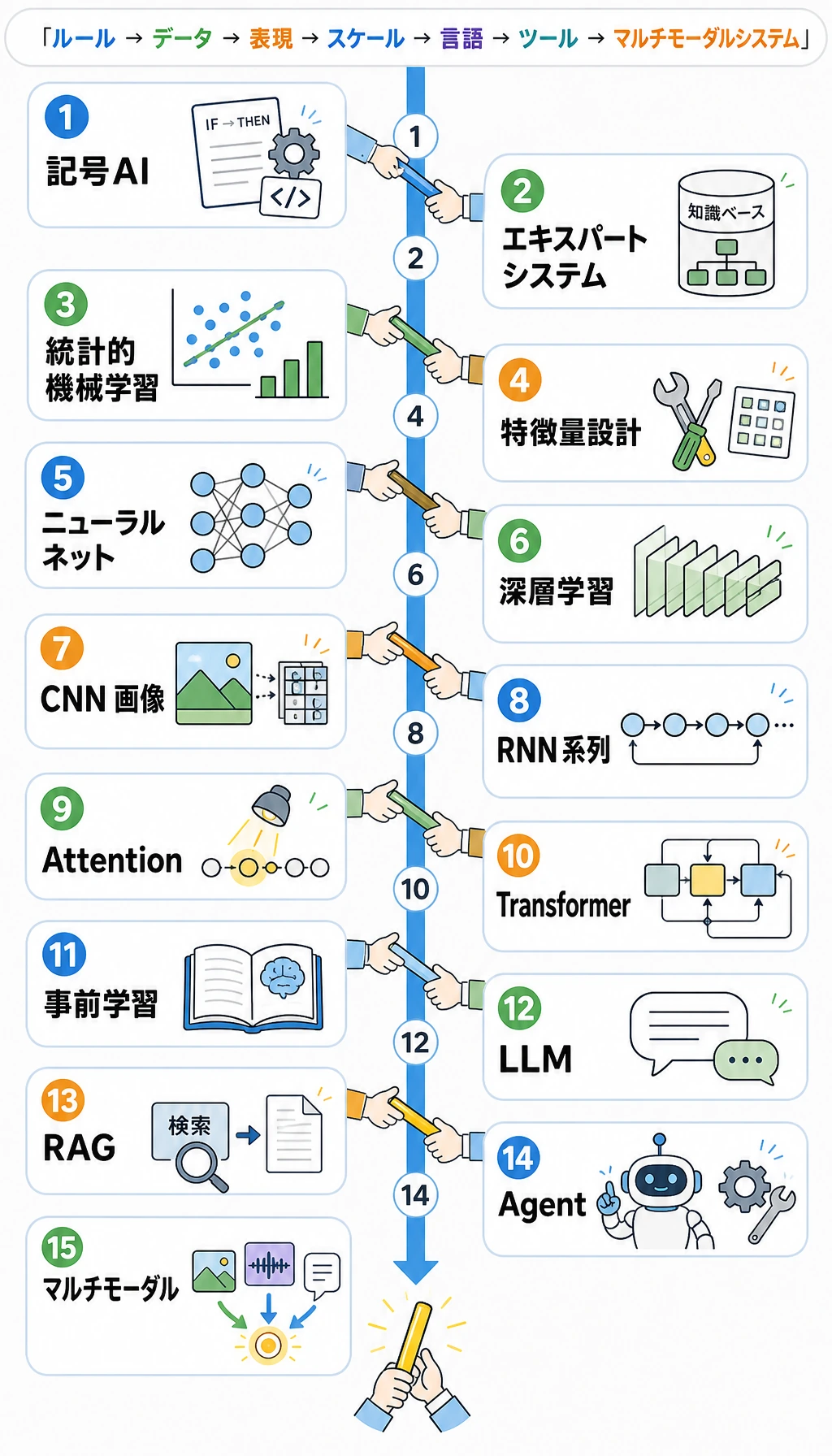
15 段階の全体像
Section titled “15 段階の全体像”| 段階 | 何が変わったか | LLM との関係 |
|---|---|---|
| 1. Turing question | 機械知能が具体的な問いになった | 言語が知能の重要なテストになった |
| 2. Dartmouth AI | AI が研究分野になった | 初期は symbolic reasoning が中心 |
| 3. Perceptron | 学習できる neural model が登場 | trainable model の第一波 |
| 4. Expert systems | rules が狭い領域で広がった | 価値と保守コストを同時に示した |
| 5. Backpropagation | 多層 neural nets が訓練可能になった | deep learning の基礎 |
| 6. LeNet | neural nets が実タスクで機能した | representation learning の実例 |
| 7. Statistical ML | data-driven methods が多くの手書き rules を超えた | NLP が corpus evidence へ移った |
| 8. ImageNet / AlexNet | deep learning が scale で勝った | data、compute、architecture が重要になった |
| 9. ResNet | 非常に深い networks が訓練しやすくなった | scale がより安定した |
| 10. RNN / LSTM | sequences が neural に扱われた | language modeling が n-gram を超えた |
| 11. Attention | 関連位置に focus できるようになった | long コンテキスト bottleneck を緩和 |
| 12. Transformer | attention が主アーキテクチャになった | parallel training と scaling が進んだ |
| 13. BERT / GPT | pretraining が shared foundation になった | 1 つの model を多タスクへ転用 |
| 14. RLHF / ChatGPT | behavior が instruction に合わせられた | capability が product behavior になった |
| 15. RAG / Agent | models が knowledge と tools を使い始めた | LLM が application system になった |
ここから言語モデルの主線に絞ります。
5 つの言語モデル時代
Section titled “5 つの言語モデル時代”| 時代 | 中心アイデア | 主な限界 |
|---|---|---|
| Rule-based systems | 人間が language rules を書く | 壊れやすく、保守が高コスト |
| Statistical language models | 頻度から次の単語を予測 | sparse data、short コンテキスト |
| Neural sequence models | vector と recurrent state を学ぶ | 長距離依存が難しく、訓練が遅い |
| Transformers | token 同士が直接 attention する | compute と data cost が高い |
| LLM + alignment | 大規模 pretraining 後に behavior を調整 | hallucination、安全、コスト、評価 |
主線は context です。各世代は、手書き仮定を減らしながら、より多くの context を使おうとしてきました。
実験:Bigram 言語モデルを作る
Section titled “実験:Bigram 言語モデルを作る”この小さな n-gram model は、現在の単語から次の単語を予測します。強くはありませんが、neural LM 以前の統計的な発想が見えます。
from collections import Counter, defaultdict
corpus = [ "I like learning AI", "I like learning Python", "You like learning NLP", "I like doing projects",]
next_word_counter = defaultdict(Counter)
for sentence in corpus: tokens = sentence.split() for current_word, next_word in zip(tokens[:-1], tokens[1:]): next_word_counter[current_word][next_word] += 1
def suggest_next(word): candidates = next_word_counter[word] return candidates.most_common() if candidates else []
print("Common words after I :", suggest_next("I"))print("Common words after like :", suggest_next("like"))print("Common words after learning:", suggest_next("learning"))期待される出力:
Common words after I : [('like', 3)]Common words after like : [('learning', 3), ('doing', 1)]Common words after learning: [('AI', 1), ('Python', 1), ('NLP', 1)]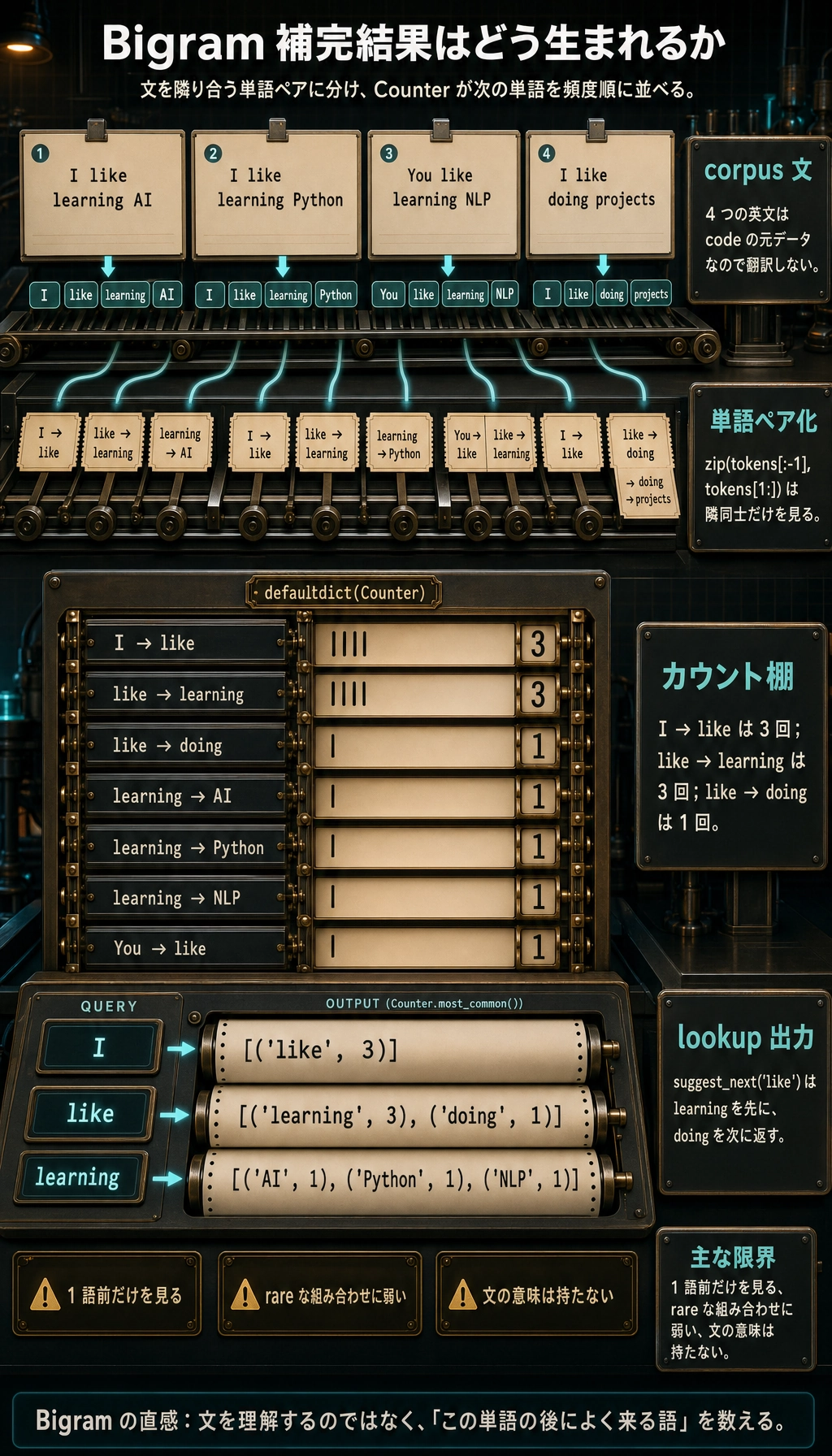
これは autocomplete に少し似ています。しかし限界も明確です。
- 1 つ前の単語しか見ない。
- rare な組み合わせは統計が弱い。
- 文の意味表現を持たない。
なぜニューラルモデル(Neural Models)が重要だったのか
Section titled “なぜニューラルモデル(Neural Models)が重要だったのか”Neural language models は、単なるカウントを learned representations に置き換えました。
Word2Vec、GloVe、RNN、LSTM、GRU により、language modeling は柔軟になりました。similarity と長めの context を学べるようになりましたが、逐次的に読むため訓練は遅く、長距離記憶も不安定でした。
なぜ Transformer が転換点だったのか
Section titled “なぜ Transformer が転換点だったのか”RNN は主に一歩ずつ読みます。Transformer では、token が attention を通して他の token と直接比較できます。
これにより 3 つの変化が起きました。
- 訓練をより並列化しやすい。
- 長距離関係を扱いやすい。
- parameters、data、compute の scale が効きやすい。
だから BERT、GPT、T5、後の LLM は Transformer family tree に属します。
なぜ Scale だけでは足りないのか
Section titled “なぜ Scale だけでは足りないのか”大規模 pretraining は広い capability を作りましたが、product behavior には別の層が必要でした。
| 必要なこと | 技術 |
|---|---|
| 指示に従う | instruction tuning |
| 役に立つ回答を好む | preference learning / RLHF |
| 最新または private knowledge を使う | RAG |
| 行動する | tool calling / Agent loop |
| unsafe behavior を減らす | safety evaluation and guardrails |
現代 LLM で重要な区別はこれです。
model capability != model behaviorモデルは強力でも、ポリシーに従わない、証拠を引用しない、安全に行動しないことがあります。
何を覚えるか
Section titled “何を覚えるか”大規模モデルは NLP の歴史に属しますが、今は狭い NLP を超えています。同じ architecture と training idea が、text、image、speech、code、video、multimodal QA、RAG、Agent に広がっています。
実務的な要点は次の通りです。
- rules は control を与えたが coverage が弱い。
- statistics は data evidence を与えたが コンテキスト が短い。
- neural representations は semantic space を作った。
- Transformer は scale を実用化した。
- alignment、RAG、tool calling が model を system に変えた。
このページを終えたら、この証拠カードを残します。
- タイムライン
- n-gram → neural LM → Transformer → scaling → instruction/alignment
- 転換点
- Transformer が context mixing をどう変えたか
- スケール注記
- データと計算量は能力を変えたが、信頼性だけを変えたわけではない
- bigram 実験
- 1 つの出力サンプルとその制約
- 記憶フック
- 歴史は解決されたボトルネックの連なりである
- bigram corpus に 2 文を追加し、suggestion がどう変わるか見る。
- bigram model が長い instruction に弱い理由を説明する。
- Transformer が RNN より並列訓練しやすい理由を説明する。
- model に capability はあるが、alignment または RAG が必要な例を 1 つ挙げる。
- 15 段階のどれか 1 つを選び、それが今日の LLM application にどう残っているか説明する。
解法と解説
- 文を追加すると、bigram model の局所的な transition count だけが変わります。追加 phrase の周辺ではよくなりますが、局所 pattern の外ではまだ失敗します。
- bigram model は短い局所 context しか見ません。長い instruction には、goal、constraint、関係を多くの token にわたって保持する力が必要です。
- Transformer の self-attention は training 中に各位置を並列に処理できます。一方 RNN は前の time step に依存するため、自然に逐次的です。
- model は fluent answer を書けても、private document には RAG が必要です。safety、refusal、instruction following には alignment が必要な場合があります。
- 例として Transformer 段階は今も重要です。attention による context mixing が、多くの LLM architecture の基礎だからです。