E.B.2 イテレータとジェネレータの応用
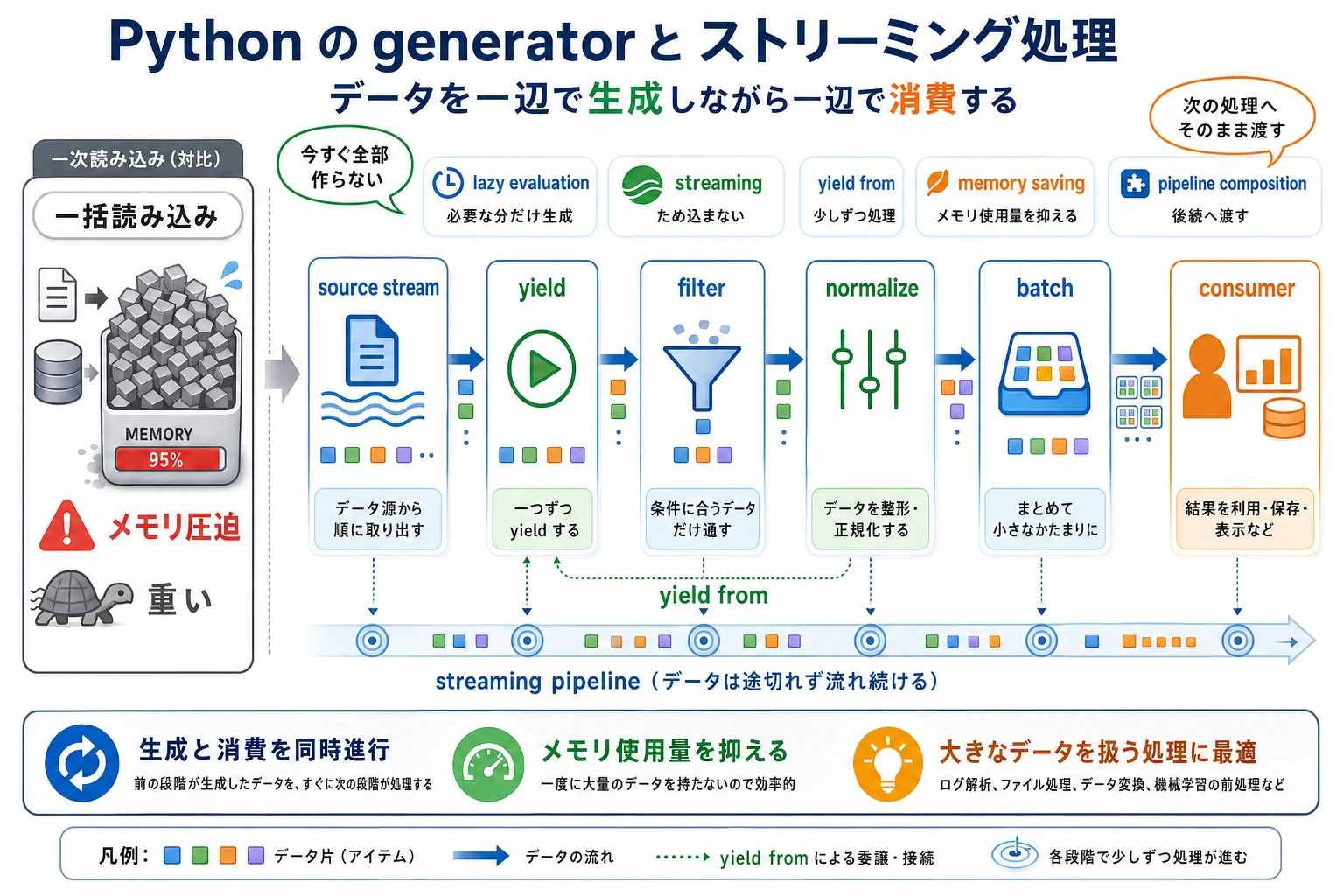
データがストリームとして届くとき、ジェネレータは役に立ちます。ログ、ファイル、API ページ、サンプル batch、検索結果、モデル出力などです。値を一つずつ出すため、不要な中間リストを作らずに済みます。
準備するもの
Section titled “準備するもの”- Python 3.10+
- 外部パッケージ不要
forループの基本理解
- Iterator(イテレータ):次の値を順に出せるオブジェクト。
- Generator(ジェネレータ):
yieldで値を遅延生成する関数。 - Lazy evaluation(遅延評価):次の値が必要になったときだけ計算すること。
- Pipeline(パイプライン):小さな処理ステップをつなげた流れ。
yield from:別の iterable の値をそのまま外へ流す構文。
ストリーミングパイプラインを動かす
Section titled “ストリーミングパイプラインを動かす”generator_pipeline.py を作成します。
def read_events(): events = [ "INFO request ok", "ERROR db timeout", "INFO cache hit", "ERROR auth failed", "ERROR model busy", ] for event in events: yield event
def filter_errors(events): for event in events: if event.startswith("ERROR"): yield event
def normalize(events): for event in events: yield event.lower()
def batch(items, size): group = [] for item in items: group.append(item) if len(group) == size: yield group group = [] if group: yield group
pipeline = batch(normalize(filter_errors(read_events())), size=2)
for group in pipeline: print(group)実行します。
python generator_pipeline.py期待される出力:
['error db timeout', 'error auth failed']['error model busy']このパイプラインは、読み取り、フィルタ、正規化、batch 化を行いますが、各段階で完全なリストを作りません。
yield from を使う
Section titled “yield from を使う”この単独で動く小さな例を実行します。
def flatten(groups): for group in groups: yield from group
pipeline = [ ["error db timeout", "error auth failed"], ["error model busy"],]
for item in flatten(pipeline): print(item)期待される出力:
error db timeouterror auth failederror model busyネストしたループよりも、「各グループ内の要素を外へ流す」という意図がはっきりします。
ジェネレータが役立つ場面
Section titled “ジェネレータが役立つ場面”向いているもの:
- 入力が大きくなる可能性がある。
- レコードを一件ずつ処理する。
- 読み取り、フィルタ、変換、batch 化をつなげたい。
- 全要素へのランダムアクセスが不要。
データが小さく、何度もアクセスするほうが分かりやすいなら、リストで十分です。
このページを終えたら、この証拠カードを残します。
- Pythonパターン
- デコレータ、イテレータ、ジェネレータ、並行処理プリミティブ、またはメタプログラミングフック
- コード成果物
- 最小限の実行可能な例と表示された出力
- 使用場面
- この pattern が AI app、pipeline、tool、または server を改善する場面
- 失敗確認
- 隠れた副作用、読みにくい抽象化、競合状態、または過度な設計
- 期待される成果
- 実践的なAIシステム用途のメモを含む小さな高度Python例
よくある間違い
Section titled “よくある間違い”- 消費済みのジェネレータを再利用できると思い込む。
- ジェネレータは常に速いと思う。主な価値はメモリと構造化にあることが多い。
- 単純なリスト変換まで無理に
yieldにして読みにくくする。
batch を変更し、batch_id も出力してください。その後、入力イベントを変えても、後続ステップを変えずに動くことを確認します。
参考実装と解説
一つの解答は、出力側で batch に番号を付けることです。
for batch_id, group in enumerate(batch(normalized, size=2), start=1): print(batch_id, group)これなら前段の読み込み、フィルタ、正規化は変えません。入力イベントを変えたときに出力されるグループだけが変わり、パイプライン構造が保たれていれば成功です。ジェネレータパイプラインの要点は、データを差し替えても後続ステップ全体を書き直さずに済むことです。