6.2.8 実用テクニック
- CPU、CUDA、Apple MPS に対応した device-safe なコードを書ける。
- よくある乱数要因を固定し、デバッグしやすくする。
- 勾配爆発時に gradient clipping を使う。
- CUDA が使えるときは AMP を使い、それ以外では安全に通常精度へ戻す。
- checkpoint を保存・復元できる。
- loss が下がらないときの確認順序を使える。
まず確認順序を見る
Section titled “まず確認順序を見る”学習が壊れているときは、モデルを作り直す前に単純なエンジニアリング問題を確認します。
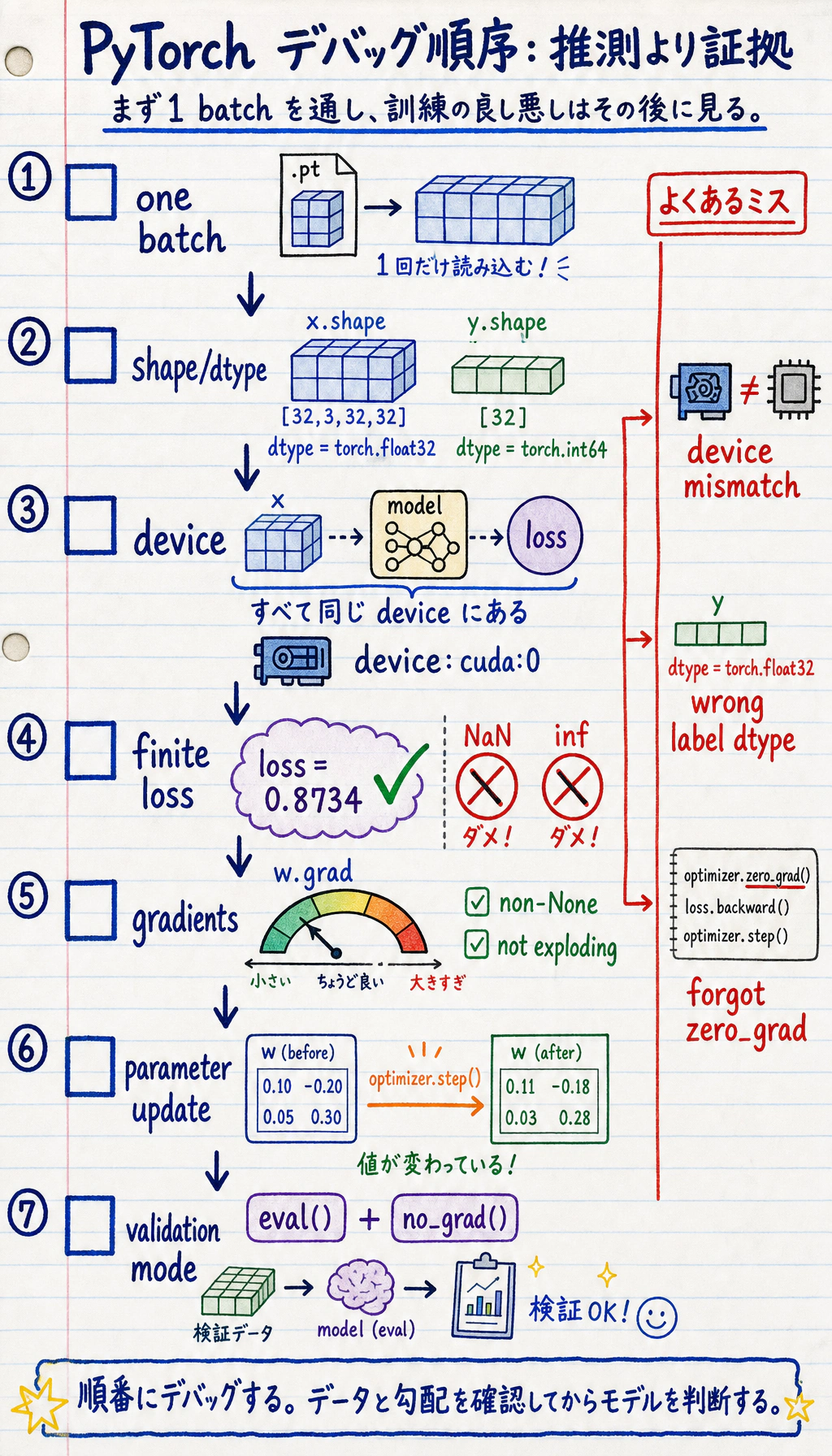
この順番で見ます。
- 1 batch は正しく読み込めているか?
- shape と dtype はモデルと loss に合っているか?
- モデルとデータは同じ device にあるか?
- loss は有限値か?
- 勾配は
Noneではなく、爆発していないか? optimizer.step()後にパラメータは更新されているか?- 検証と予測は
eval()とno_grad()で囲まれているか?
実験 1: Device と Seed
Section titled “実験 1: Device と Seed”この実験は CPU、CUDA、Apple Silicon MPS で動きます。
import random
import numpy as npimport torch
if torch.cuda.is_available(): device = torch.device("cuda")elif torch.backends.mps.is_available(): device = torch.device("mps")else: device = torch.device("cpu")
def set_seed(seed=42): random.seed(seed) np.random.seed(seed) torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed_all(seed)
print("device_seed_lab")print("device:", device)
set_seed(42)a = torch.randn(3)set_seed(42)b = torch.randn(3)
print("same random:", torch.equal(a, b))print("sample:", a)出力例:
device_seed_labdevice: mpssame random: Truesample: tensor([0.3367, 0.1288, 0.2345])あなたの環境では device が cpu、cuda、mps のどれかになります。
再現性について:
- seed はデバッグをかなり楽にします。
- 一部の GPU 演算や並列実行の細部では、まだ小さな差が出ることがあります。
- 目標は「デバッグできる程度に再現できること」であり、すべての環境で数学的に完全一致することではありません。
実験 2: 勾配クリッピング
Section titled “実験 2: 勾配クリッピング”勾配クリッピングは、optimizer の更新前に勾配ノルムを制限します。RNN、Transformer、不安定な深いネットワークでよく使われます。
import torchfrom torch import nn
torch.manual_seed(42)
model = nn.Sequential( nn.Linear(10, 20), nn.ReLU(), nn.Linear(20, 1),)
x = torch.randn(32, 10)y = torch.randn(32, 1) * 50
loss = nn.MSELoss()(model(x), y)loss.backward()
def grad_norm(model): total = 0.0 for param in model.parameters(): if param.grad is not None: total += param.grad.norm(2).item() ** 2 return total ** 0.5
print("grad_clip_lab")before = grad_norm(model)torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)after = grad_norm(model)
print("before:", round(before, 4))print("after:", round(after, 4))期待される出力:
grad_clip_labbefore: 38.7677after: 1.0クリッピングを置く場所:
zero_gradbackwardclip gradientsoptimizer.step
backward() の前にクリップしてはいけません。その時点では勾配がまだ存在しないからです。
実験 3: AMP と安全なフォールバック
Section titled “実験 3: AMP と安全なフォールバック”AMP は automatic mixed precision です。CUDA GPU ではメモリ使用量を減らし、学習を速くできることがあります。CPU や MPS では、この例は通常精度に戻ります。
import torchfrom torch import nn
if torch.cuda.is_available(): device = torch.device("cuda")elif torch.backends.mps.is_available(): device = torch.device("mps")else: device = torch.device("cpu")
model = nn.Sequential(nn.Linear(16, 32), nn.ReLU(), nn.Linear(32, 1)).to(device)optimizer = torch.optim.Adam(model.parameters(), lr=0.01)loss_fn = nn.MSELoss()
x = torch.randn(64, 16, device=device)y = torch.randn(64, 1, device=device)
print("amp_lab")if device.type == "cuda": scaler = torch.amp.GradScaler("cuda") for _ in range(3): optimizer.zero_grad() with torch.amp.autocast("cuda"): loss = loss_fn(model(x), y) scaler.scale(loss).backward() scaler.step(optimizer) scaler.update() print("used AMP on cuda")else: for _ in range(3): optimizer.zero_grad() loss = loss_fn(model(x), y) loss.backward() optimizer.step() print("used standard precision on", device.type)出力例:
amp_labused standard precision on mpsAMP が向いている場面:
- CUDA で学習している。
- メモリが足りない。
- モデルが mixed precision に向いている。
通常精度のままがよい場面:
- 数値問題をデバッグしている。
- CPU で小さな例を動かしている。
- できるだけ単純な baseline が必要。
実験 4: Checkpoint を保存して復元する
Section titled “実験 4: Checkpoint を保存して復元する”Checkpoint には通常、次を入れます。
model.state_dict()optimizer.state_dict()- epoch
- best validation metric
- 必要なら設定やラベルマッピング
この実験では一時ディレクトリを使うので、ファイルは残りません。
import osimport tempfile
import torchfrom torch import nn
model = nn.Linear(2, 1)optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
print("checkpoint_lab")with tempfile.TemporaryDirectory() as tmp: checkpoint_path = os.path.join(tmp, "demo_checkpoint.pt")
torch.save( { "model_state_dict": model.state_dict(), "optimizer_state_dict": optimizer.state_dict(), "epoch": 5, "best_val": 0.123, }, checkpoint_path, )
new_model = nn.Linear(2, 1) new_optimizer = torch.optim.SGD(new_model.parameters(), lr=0.1)
ckpt = torch.load(checkpoint_path, map_location="cpu") new_model.load_state_dict(ckpt["model_state_dict"]) new_optimizer.load_state_dict(ckpt["optimizer_state_dict"])
print("restored epoch:", ckpt["epoch"]) print("restored best_val:", ckpt["best_val"])期待される出力:
checkpoint_labrestored epoch: 5restored best_val: 0.123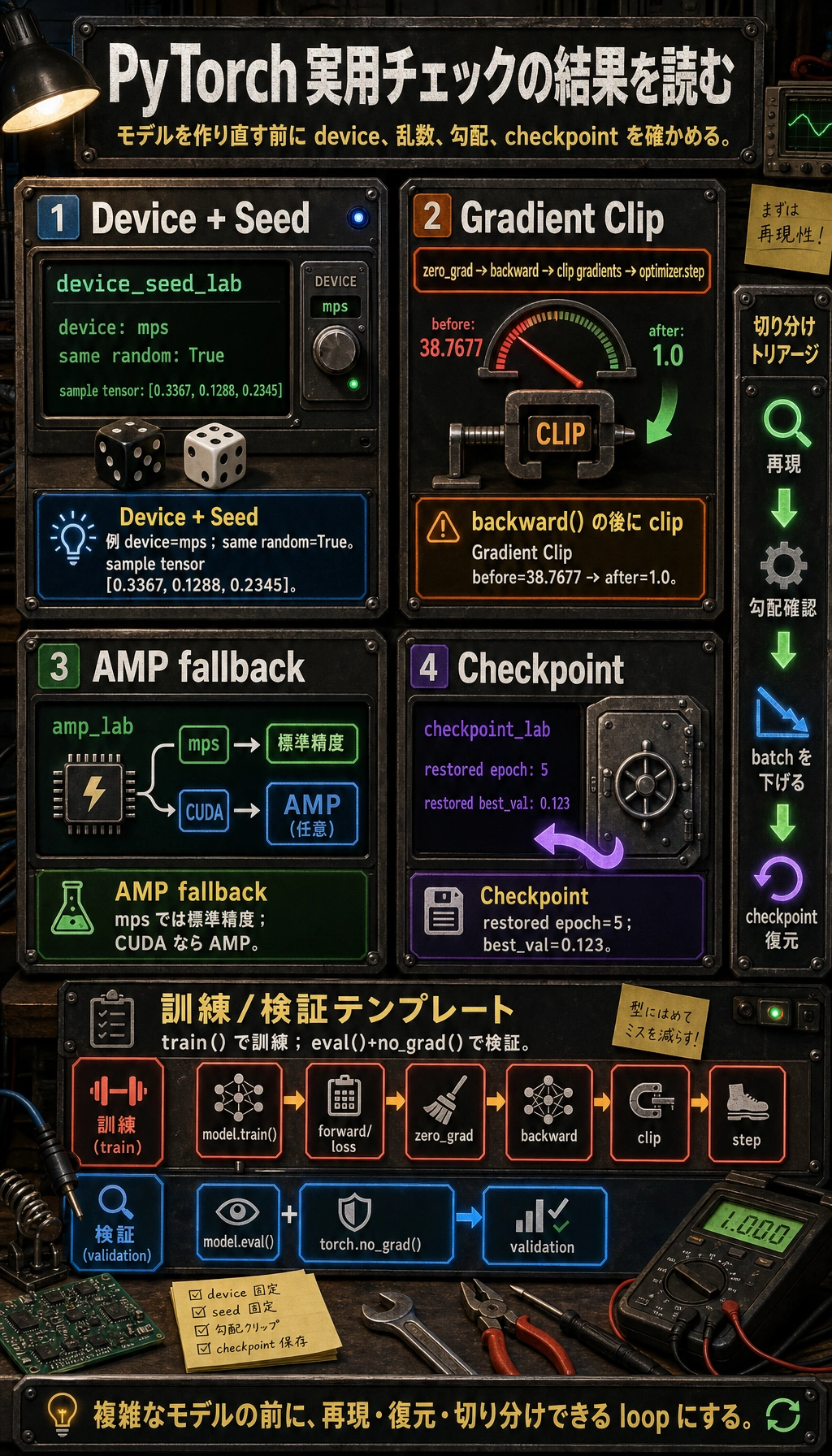
実プロジェクトでは、次のような安定したパスに保存します。
checkpoints/best_model.ptすべての PyTorch project で、短い実行安全メモを残します。
- デバイス
- cpu/cuda/mps とモデル/データの一致
- シード
- デバッグ前に設定する
- 勾配ノルム
- 不安定なときにクリッピング前後で測定
- 精度
- AMP は対応時のみ使用し、フォールバックも動作する
- チェックポイント
- model_state_dict、optimizer_state_dict、epoch、best_val
- デバッグ順序
- batch → shape → device → loss → gradients → update → validation
メモリと安定性の切り分け
Section titled “メモリと安定性の切り分け”| 症状 | 最初の対応 | 次の対応 |
|---|---|---|
| out of memory | batch_size を下げる | CUDA なら AMP、その後 gradient accumulation |
loss が nan になる | 学習率を下げる | 入力を確認し、gradient clipping を入れる |
| 検証が遅い | model.eval() と torch.no_grad() を入れる | 検証頻度を下げる |
| 実行ごとに結果が大きく変わる | seed を設定する | 設定とデータ分割をログに残す |
| checkpoint が読み込めない | アーキテクチャと key 名を確認する | state_dict().keys() を見る |
gradient accumulation の直感:
大きな有効 batch = 複数回の小さな forward/backward + 1 回の optimizer stepメモリに大きな batch を一度に載せられないときに便利です。
保存して使える学習テンプレート
Section titled “保存して使える学習テンプレート”model.train()for batch_x, batch_y in train_loader: batch_x = batch_x.to(device) batch_y = batch_y.to(device)
pred = model(batch_x) loss = loss_fn(pred, batch_y)
optimizer.zero_grad() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) optimizer.step()
model.eval()with torch.no_grad(): for batch_x, batch_y in val_loader: batch_x = batch_x.to(device) batch_y = batch_y.to(device) pred = model(batch_x) val_loss = loss_fn(pred, batch_y)地味ですが、PyTorch 学習でよくあるミスをかなり防げるテンプレートです。
- 以前の学習ループに device 処理を追加し、モデルとデータの device が一致することを確認してください。
- 自分のモデルで、勾配クリッピング前後の勾配ノルムを表示してください。
- best validation loss 用の checkpoint 保存を追加してください。
- loss が不安定になるまで一時的に学習率を上げ、その後、学習率を下げて gradient clipping を入れて回復させてください。
解法と解説
- モデル、入力 tensor、ラベル、ループ内で新しく作る tensor を同じ
deviceに移します。device を表示する、または簡単な assertion を入れると、多くの実行時エラーを早く防げます。 - clipping 後の勾配ノルムは、設定したしきい値付近に抑えられるはずです。clipping 前のノルムが非常に大きい場合は、learning rate、loss scale、データ値も確認します。
- 少なくとも
model.state_dict()、best validation loss、epoch を保存します。訓練を再開したいなら optimizer state と設定も保存します。 - 高すぎる learning rate は、loss のスパイク、振動、または
nanを起こしがちです。learning rate を下げ、gradient clipping を加えると安定化できますが、ラベル間違い、shape 間違い、data leakage は別途直す必要があります。
.cuda()を直接決め打ちせず、device を選び、モデルとデータの両方を移動します。- 学習挙動をデバッグする前に seed を設定します。
- 勾配クリッピングは
backward()の後、step()の前に入れます。 - AMP は主に CUDA 向けに使い、単純なフォールバック経路を残します。
- checkpoint には model state、optimizer state、epoch、validation metric を保存します。