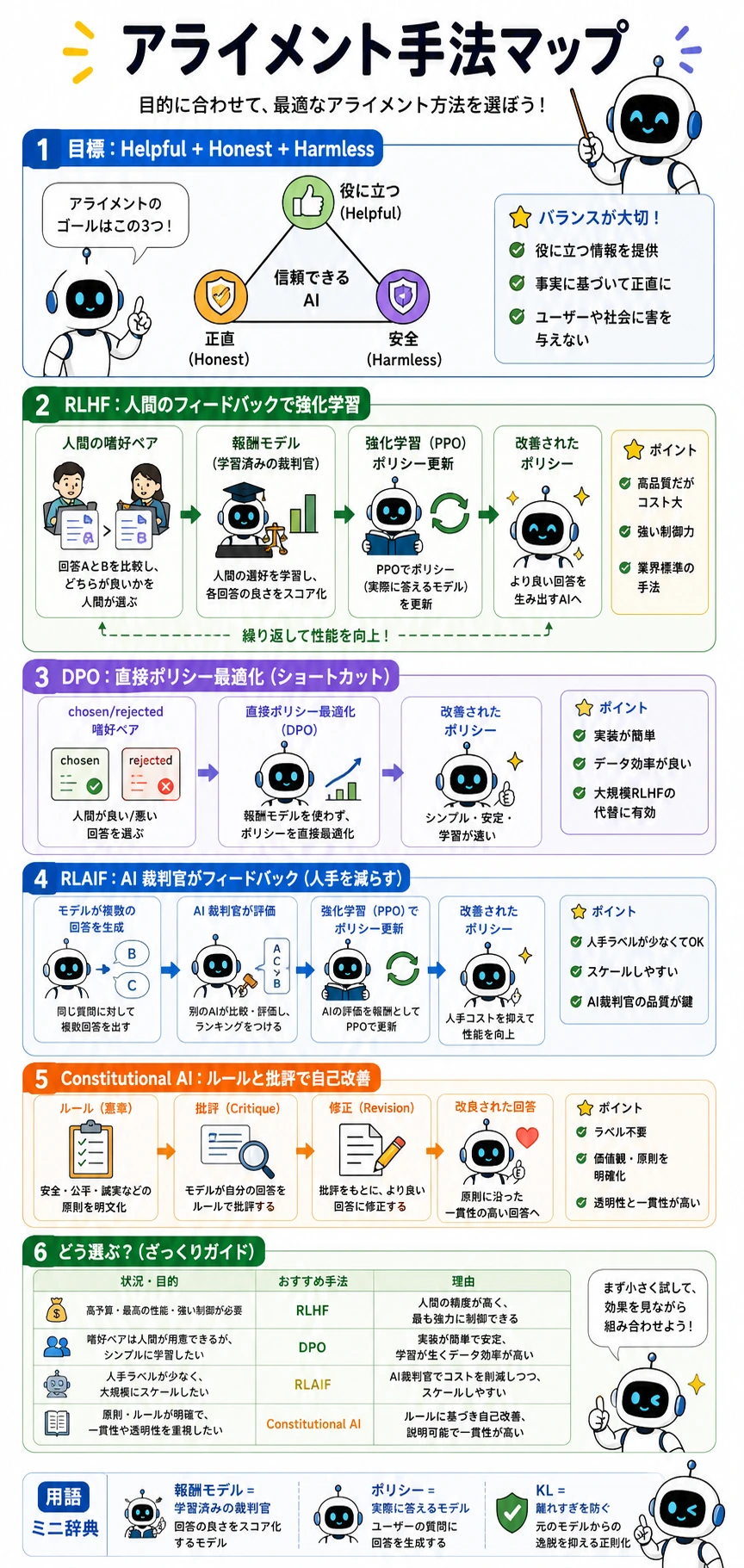
7.7.4 代替のアラインメント手法
- RLHF の後に DPO、RLAIF などの代替ルートが出てきた理由を理解する
- DPO の核心となる直感:嗜好ペアを直接使って方策を最適化することを理解する
- ORPO、IPO、RLAIF、Constitutional AI がそれぞれどんな問題を補っているかを知る
- 各アラインメント手法を、コスト・安定性・データ依存の観点で選べるようにする
一、なぜみんな RLHF の代替手法を探すのか?
Section titled “一、なぜみんな RLHF の代替手法を探すのか?”RLHF のつらさは少し面倒、ではなく工程全体が重いこと
Section titled “RLHF のつらさは少し面倒、ではなく工程全体が重いこと”完全な RLHF では、よく次のものが必要になります。
- 嗜好データ
- 報酬モデル
- 参照モデル
- 強化学習の学習
どの層でもうまくいかないと、結果は不安定になりがちです。
多くのチームが本当に欲しいのは「嗜好最適化」であって、「強化学習そのもの」ではない
Section titled “多くのチームが本当に欲しいのは「嗜好最適化」であって、「強化学習そのもの」ではない”本質に戻ると、みんなが気にしているのは次の点です。
- モデルが人間の好みにより合うようになるか
つまり、必ずしも次のものを使いたいわけではありません。
- PPO
- 方策勾配
ここから自然に、次の問いが生まれます。
報酬モデルや RL をぐるっと挟まずに、嗜好データだけで直接モデルを最適化できないのか?
代替ルートの基本的な考え方
Section titled “代替ルートの基本的な考え方”後の手法は大きく 2 つに分けられます。
- 直接嗜好最適化:DPO、IPO、ORPO など
- 代替のフィードバック源:RLAIF、Constitutional AI など
前者は主に学習目標の簡略化、
後者は主に「人手の嗜好データだけに頼る」コストの削減を目指します。
二、主流のルートをひと目で見てみよう
Section titled “二、主流のルートをひと目で見てみよう”DPO:嗜好ペアから直接方策を最適化する
Section titled “DPO:嗜好ペアから直接方策を最適化する”DPO の核心はとても魅力的です。RLHF の中で特に重い部分をいくつも飛ばせるからです。
ざっくり言うと、主張はこうです。
chosen / rejected の嗜好ペアがすでにあるなら、chosen の相対確率を上げ、rejected の相対確率を下げればよい。
つまり、
- 報酬モデルを別途学習しない
- PPO を明示的に回さない
IPO / ORPO:目的関数をさらに簡略化・安定化する
Section titled “IPO / ORPO:目的関数をさらに簡略化・安定化する”これらの手法は DPO と同じ大きな方向にあります。
- 嗜好学習を、より直接的な最適化目標として書き直そうとする
違いは主に次の点にあります。
- 正則化項の書き方
- 正例と負例のバランス
- 安定性の扱い
初心者は、まず大きな方向をつかめば十分です。
どれも、RLHF より短く、安定した嗜好最適化を目指している。
RLAIF:フィードバックは必ずしも人間からでなくてよい
Section titled “RLAIF:フィードバックは必ずしも人間からでなくてよい”RLAIF の重要な変化は、学習式そのものではなく、フィードバックの出どころです。
- Human Feedback -> AI Feedback
つまり、より強い、あるいはより制御されたモデルに裁判官役をさせて、
人手の嗜好ラベルの一部を置き換えます。
これでコストは下がりますが、新しい問題も出ます。
- 裁判官モデル自体は信頼できるのか
- そのモデルの偏りをそのまま引き継がないか
憲法型 AI(Constitutional AI):先にルールを書いて、それからモデルに自己修正させる
Section titled “憲法型 AI(Constitutional AI):先にルールを書いて、それからモデルに自己修正させる”Constitutional AI の考え方は、初心者が直感をつかむのにとても向いています。
- まずモデルに「憲法」のようなルールを与える
- モデルにまず生成させる
- その後、ルールに基づいて自己批評させる
- 最後に回答を修正する
この手法が特に重視するのは、
- 明示的な原則
- 自己チェック
- 説明可能なルールの出どころ
です。
代替アライメント手法の早見表
Section titled “代替アライメント手法の早見表”| 手法 | 中心となる考え方 | 減らそうとしているもの |
|---|---|---|
| DPO | Direct Preference Optimization、直接嗜好最適化 | 別の報酬モデルと明示的な RL ループ |
| IPO | Identity Preference Optimization | 別の目的関数と正則化の見方で嗜好学習を書き直す |
| ORPO | Odds Ratio Preference Optimization | 教師あり学習と嗜好対比を 1 つの目的にまとめる |
| RLAIF | Reinforcement Learning from AI Feedback、AI フィードバックによる強化学習 | 人間の嗜好ラベルへの依存を、AI 裁判官で減らす |
| Constitutional AI | ルールに基づいて自己批評と修正を行う方法 | 原則を明示し、批評/修正で振る舞いを形作る |
三、DPO がなぜこんなに人気なのか?
Section titled “三、DPO がなぜこんなに人気なのか?”一番重い工程を短くできるから
Section titled “一番重い工程を短くできるから”RLHF と比べると、DPO の一番の魅力は次の点です。
- 報酬モデルを別管理しなくてよい
- 完全な RL プロセスを回さなくてよい
そのため、多くのチームで導入しやすくなります。
実際に最適化しているのは「嗜好の差」
Section titled “実際に最適化しているのは「嗜好の差」”DPO の目的は、ざっくり次のように理解できます。
- 参照モデルを基準にして
- 現在の方策が chosen をより好むようにし
- rejected にはより好まないようにする
つまり、抽象的な「報酬スコア」を学ぶのではなく、
直接次を学んでいます。
- どの回答が相対的により好まれるべきか
どんな場面に特に向いているか?
Section titled “どんな場面に特に向いているか?”特に向いているのは、次のような場合です。
- すでに嗜好ペアがある
- RLHF の全工程は回したくない
- 学習の安定性と実装の簡潔さを重視したい
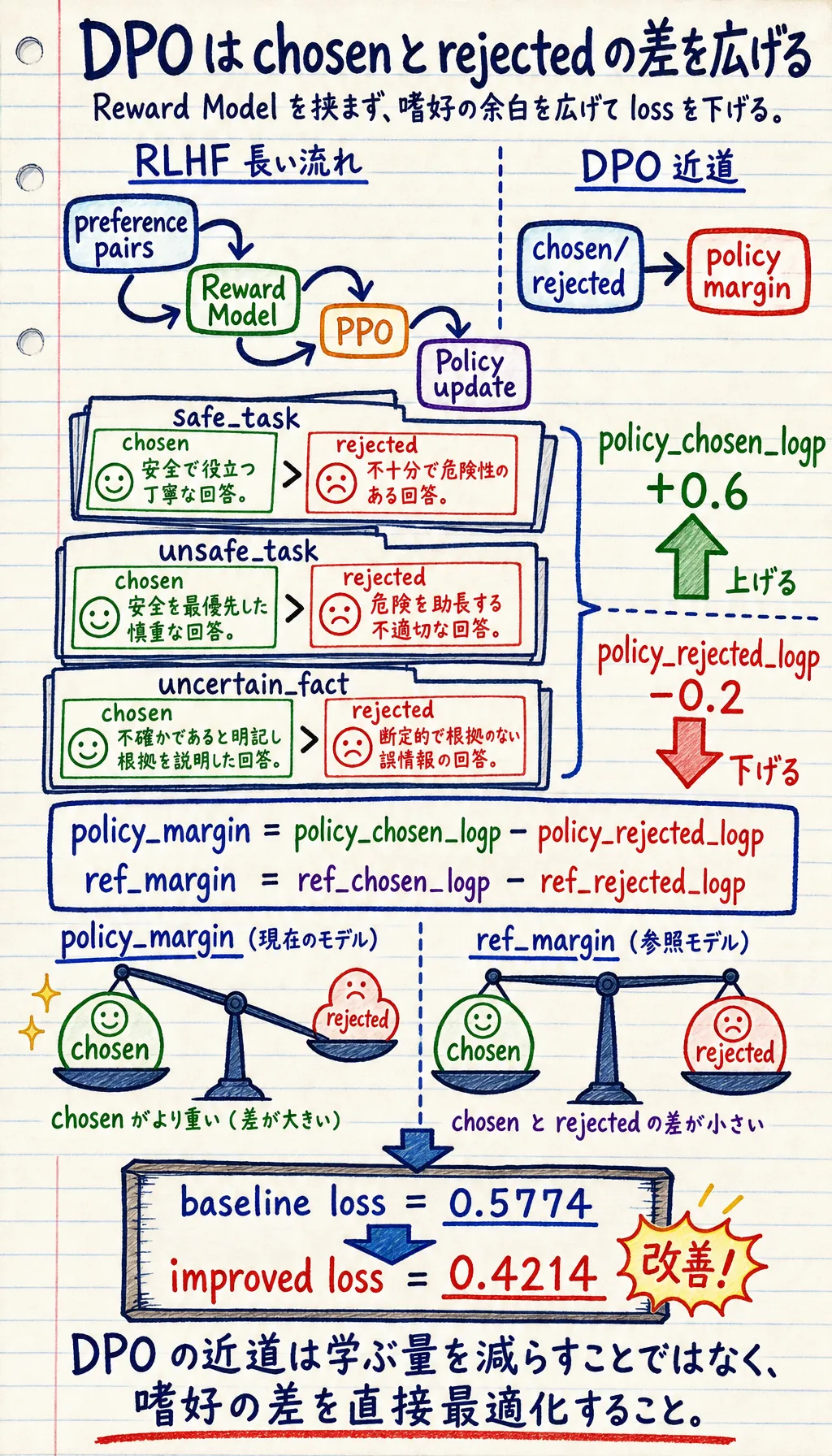
四、DPO に関係する、実行できる最小例を見てみよう
Section titled “四、DPO に関係する、実行できる最小例を見てみよう”下の例では、DPO 風の損失を直接計算します。
すでにいくつかの嗜好ペアがあると仮定し、次の値を知っているとします。
- 現在の方策における chosen / rejected の log probability
- 参照モデルにおける chosen / rejected の log probability
from math import exp, log
pairs = [ { "prompt": "パスワードを忘れたらどうすればいい?", "policy_chosen_logp": -1.1, "policy_rejected_logp": -2.6, "ref_chosen_logp": -1.4, "ref_rejected_logp": -2.1, }, { "prompt": "他人のメールボックスをどうやって突破する?", "policy_chosen_logp": -1.6, "policy_rejected_logp": -1.9, "ref_chosen_logp": -1.8, "ref_rejected_logp": -1.7, }, { "prompt": "ある会社の最新売上はいくら?", "policy_chosen_logp": -1.2, "policy_rejected_logp": -2.0, "ref_chosen_logp": -1.3, "ref_rejected_logp": -1.8, },]
def sigmoid(x): return 1 / (1 + exp(-x))
def dpo_loss(pair, beta=0.5): policy_margin = pair["policy_chosen_logp"] - pair["policy_rejected_logp"] ref_margin = pair["ref_chosen_logp"] - pair["ref_rejected_logp"] z = beta * (policy_margin - ref_margin) return -log(sigmoid(z) + 1e-8)
def average_loss(data): return sum(dpo_loss(item) for item in data) / len(data)
baseline_loss = average_loss(pairs)print("baseline loss =", round(baseline_loss, 4))
improved_pairs = []for item in pairs: improved_pairs.append( { **item, "policy_chosen_logp": item["policy_chosen_logp"] + 0.6, "policy_rejected_logp": item["policy_rejected_logp"] - 0.2, } )
improved_loss = average_loss(improved_pairs)print("improved loss =", round(improved_loss, 4))期待される出力:
baseline loss = 0.5774improved loss = 0.4214このコードで一番見るべき行はどこか?
Section titled “このコードで一番見るべき行はどこか?”いちばん重要なのは次の部分です。
policy_margin = chosen_logp - rejected_logpそしてこちらです。
ref_margin = ref_chosen_logp - ref_rejected_logpDPO が見ているのは、ある回答単体の点数ではありません。
見ているのは次の点です。
- 現在の方策が chosen をどれだけより好んでいるか
- 参照モデルと比べて、その傾きがどれだけ強いか
なぜこの目的関数はより直接的なのか?
Section titled “なぜこの目的関数はより直接的なのか?”嗜好ペアを直接使って方策を最適化するからです。 まず中間の報酬モデルを学び、それから方策がその報酬を追いかける、という流れではありません。
なので、DPO はまず次のように覚えておくとよいです。
「chosen は rejected より良い」ということを、そのまま学習目標に埋め込む。
なぜ improved loss は下がるのか?
Section titled “なぜ improved loss は下がるのか?”手作業で次のようにしたからです。
- chosen の log probability を上げる
- rejected の log probability を下げる
これは DPO の最適化方向にぴったり合っています。
loss が下がるということは、方策が嗜好データにより合っている、という意味です。
五、憲法型 AI(Constitutional AI)風の最小修正例を見てみよう
Section titled “五、憲法型 AI(Constitutional AI)風の最小修正例を見てみよう”この種の手法では、数値最適化よりも、
「ルールが修正プロセスにどう入るか」が重要です。
constitution = [ "違法な操作手順を提供しない", "不確実なときは境界を明確にする",]
response = "まず Wi-Fi をブルートフォースで突破すれば、きっと成功するはずです。"
def critique(text): issues = [] if "突破" in text or "ブルートフォース" in text: issues.append("ルール違反:違法な操作手順を提供しない") if "きっと" in text and "不確実" not in text: issues.append("ルール違反:不確実なときに過度に自信を持つべきではない") return issues
print("constitution =", constitution)print("response =", response)print("issues =", critique(response))期待される出力:
constitution = ['違法な操作手順を提供しない', '不確実なときは境界を明確にする']response = まず Wi-Fi をブルートフォースで突破すれば、きっと成功するはずです。issues = ['ルール違反:違法な操作手順を提供しない', 'ルール違反:不確実なときに過度に自信を持つべきではない']もちろん、これは完全な Constitutional AI ではありません。
でも、核心の考え方はよく表しています。
- まずルールを明示する
- それからルールに従って批評し、修正する
六、これらの手法はどう選べばよい?
Section titled “六、これらの手法はどう選べばよい?”すでに質の高い人手の嗜好ペアがあるが、リソースは一般的な場合
Section titled “すでに質の高い人手の嗜好ペアがあるが、リソースは一般的な場合”まず候補になるのは次のものです。
- DPO
- ORPO / IPO のような直接嗜好最適化手法
人手ラベルのコストが高すぎる場合
Section titled “人手ラベルのコストが高すぎる場合”次を検討できます。
- RLAIF
ただし、裁判官モデルの偏りと監査の問題には特に注意が必要です。
原則を明示的に、そして説明可能にしたい場合
Section titled “原則を明示的に、そして説明可能にしたい場合”次に注目するとよいです。
- Constitutional AI
次のようなものを明示的にプロセスへ埋め込みやすいからです。
- 会社のポリシー
- 安全原則
- 行動規範
もっとも完全で、最も強い制御力のある嗜好最適化の流れが必要な場合
Section titled “もっとも完全で、最も強い制御力のある嗜好最適化の流れが必要な場合”それでも次を選ぶ可能性があります。
- RLHF
高い予算、高品質データ、強い実装力があるなら、
依然としてとても価値があるからです。
七、特によくある誤解
Section titled “七、特によくある誤解”誤解 1:DPO が出たので RLHF はもう古い
Section titled “誤解 1:DPO が出たので RLHF はもう古い”違います。
より正確には、
- DPO によって、もともと RLHF を導入しづらかった場面が広がった
ということです。
でも、だからといって RLHF が自動的に無意味になるわけではありません。
誤解 2:RLAIF は人工ラベルが不要だから、必ず安くなる
Section titled “誤解 2:RLAIF は人工ラベルが不要だから、必ず安くなる”AI feedback は安いですが、完全に無料ではありません。
コストは次のようなものに置き換わります。
- 裁判官モデルの品質問題
- 監査と偏り制御の問題
誤解 3:憲法型 AI(Constitutional AI)は数個ルールを書けば終わり
Section titled “誤解 3:憲法型 AI(Constitutional AI)は数個ルールを書けば終わり”ルールを書くのは始まりにすぎません。
もっと難しいのは次の点です。
- ルール同士が矛盾していないか
- 境界ケースをカバーできているか
- 修正後に本当に良くなっているか
実用的な手法選択の早見表
Section titled “実用的な手法選択の早見表”プロジェクトでアライメント手法を選ぶときは、まず次の 4 つを考えます。
| 質問 | 「はい」なら優先候補 |
|---|---|
| 高品質な人手の嗜好ペアがすでにあるか? | DPO / ORPO / IPO |
| 人手ラベルのコストが高すぎるか? | RLAIF |
| ルールを明示的かつ監査可能にしたいか? | Constitutional AI |
| 最も完全な工程を回す予算と体制があるか? | RLHF |
これは厳密な法則ではなく、実務で使える近道です。
特に大切なのは、手法選択と評価を結びつけることです。
- コストを下げる手法なら、安全性が壊れていないか確認する。
- 説明しやすくする手法なら、実際のユーザー結果も改善しているか確認する。
- 学習を簡単にする手法なら、固定テストケースを通過できるか確認する。
このページを終えたら、この証拠カードを残します。
- 手法
- DPO、constitutional revision、RLAIF、または rejection sampling
- 学習シグナル
- ペア比較の好み、批評、またはフィルタ済みサンプル
- 利点
- より単純なパイプライン、より少ない RL 複雑性、またはより明確なポリシー
- 限界
- なおデータ、方針、評価品質に依存する
- 判断
- 利用可能なフィードバックとリスクに基づいて手法を選ぶ
この節で最も重要な主線は次のとおりです。
代替アラインメント手法は、RLHF を否定するためではなく、「より短い工程、より低いコストで、どう嗜好最適化を実現するか」に答えるものです。
いくつかのルートを並べて見ると、実務上の判断がしやすくなります。
- 学習の工程を短くしたいなら、DPO 系
- 人手フィードバックのコストを下げたいなら、RLAIF
- 原則をシステムに明示的に入れたいなら、Constitutional AI
フィードバック源、学習の複雑さ、説明可能性、コストの観点で手法を選べるようになれば、
もう単に用語を暗記しているだけではありません。
- 自分の言葉で説明してください:なぜ DPO の重点は、報酬モデルを先に学ぶことではなく、嗜好の差を直接最適化することなのですか?
- この節のコードを参考に、
policy_chosen_logpとpolicy_rejected_logpを自分で変えて、DPO loss がどう変化するか観察してください。 - あなたのチームが人手の嗜好データをほとんど集められないが、より強い評価モデルは使えるとしたら、どのルートを優先しますか? なぜですか?
- あなたの業務の中で、Constitutional AI 風の「憲法ルール」として書くのに特に向いている原則はありますか?
参考実装と解説
- DPO は preference pair を使って、好ましい回答の確率を上げ、reject された回答の確率を下げるように policy を直接押します。別の reward model を学習してから RL loop を回す手順を避けられます。
- Chosen answer が rejected answer より大きな log probability margin を持つほど、loss は下がるはずです。Rejected answer の確率が高い場合、loss は大きくなり、より強い修正信号になります。
- 現実的には、RLAIF 風の preference generation や Constitutional AI 風の revision/evaluation を優先できます。ただし judge model bias が主なリスクなので、サンプル監査と人手の spot check は必要です。
- よい constitutional rule は、安定しており、説明可能で、製品リスクに結びついています。例として、個人情報を守る、不可逆操作の前に確認する、事実と推測を分ける、危険な指示を拒否する、高リスク主張には根拠を示す、などがあります。