10.2.1 Image Classification ロードマップ:Image In、Label Out
Image classification は 1 つの問いに答えます:画像全体を見て、最も適切な class は何か。
まず classification loop を見る
Section titled “まず classification loop を見る”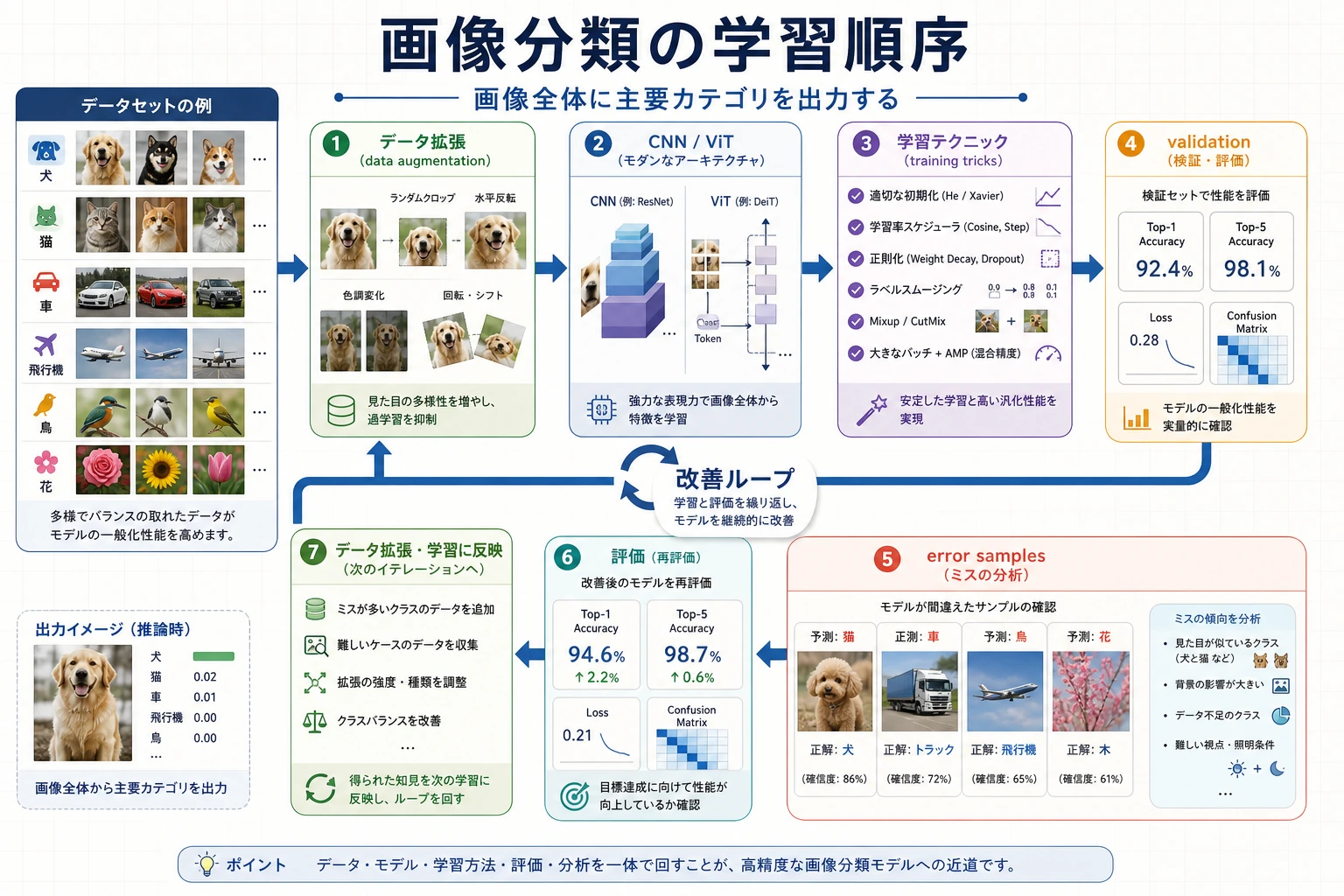

Classification は最も単純な vision output ですが、data split、augmentation、architecture、loss、metrics、error examples に依存します。
Prediction check を動かす
Section titled “Prediction check を動かす”この script は classifier の最後の step を再現します:score が最も高い label を選びます。
labels = ["cat", "dog", "panda"]scores = [0.12, 0.74, 0.14]
best_index = max(range(len(scores)), key=lambda index: scores[index])
print("prediction:", labels[best_index])print("confidence:", scores[best_index])出力:
prediction: dogconfidence: 0.74実プロジェクトでは top class だけを見せないでください。confidence、wrong examples、confusion patterns を残します。
この順番で学ぶ
Section titled “この順番で学ぶ”| 手順 | 読む内容 | 実践アウトプット |
|---|---|---|
| 1 | Data augmentation | class を保つ変化と risk を生む変化を説明する |
| 2 | Modern architectures | feature extractor、classifier head、pretrained backbone を比較する |
| 3 | Training techniques | split、loss、accuracy、overfitting、error samples を追跡する |
minimal classifier を動かし、train/validation metrics を示し、少なくとも 1 枚の failure image を説明できれば、この章は合格です。
確認の考え方と解説
- 合格レベルの答えでは、task を class label、bounding box、mask、OCR text、embedding、video event など正しい視覚出力に対応づけます。
- 証拠には、rendered visual artifact と、metric または定性的な error note を含めます。
- class confusion、missed object、bad mask、lighting shift、domain shift、annotation quality など、失敗モードを1つ説明できればよいです。
このページを終えたら、この evidence card を残します。
- データセット分割
- train/test 画像、クラス名、クラスの偏り
- 予測
- ラベル、信頼度、そして少なくとも 1 枚の誤分類画像
- 指標
- accuracy、F1、confusion matrix、およびクラスごとのエラー
- 失敗確認
- 拡張がラベルの意味を変える、クラス不均衡、リーク、または過学習
- 期待される成果
- モデル結果の表と保存済みのエラー例