6.8.2 プロジェクト:画像分類システム
- クラス境界が明確な分類タスクを定義できる。
- train/validation/test の証拠を整理できる。
- 予測を出す小さなベースラインを動かせる。
- 混同行列を作り、エラー例を取り出せる。
- 実際の CNN や転移学習プロジェクトで何を見せるべきか分かる。
まずプロジェクトの流れを見る
Section titled “まずプロジェクトの流れを見る”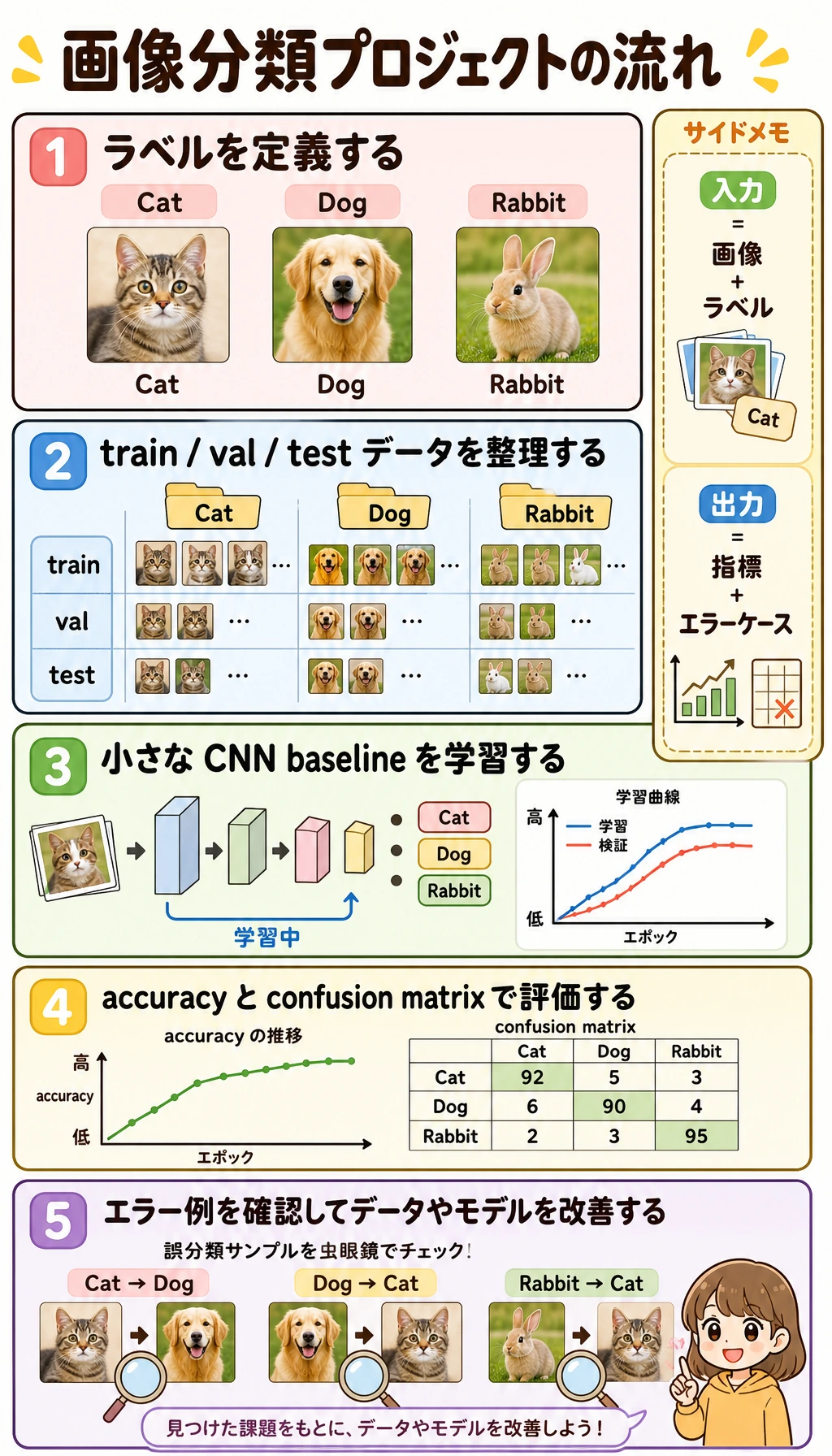
labelsdata splitbaselinemetricserror casesnext data/model action
題材は次を満たすものにします。
- クラス境界が明確。
- データを実際に集められる。
- 間違いを説明できる。
最初から数百の細かいクラスや、人間でも意見が割れるラベルにはしない方が安全です。
プロジェクト計画テンプレート
Section titled “プロジェクト計画テンプレート”from dataclasses import dataclass, field
@dataclassclass CVProjectPlan: name: str classes: list[str] dataset_split: dict[str, int] baseline: str metrics: list[str] risks: list[str] = field(default_factory=list)
plan = CVProjectPlan( name="pet_image_classifier", classes=["cat", "dog", "rabbit"], dataset_split={"train": 900, "val": 180, "test": 180}, baseline="small_cnn_then_transfer_learning", metrics=["accuracy", "confusion_matrix", "error_cases"], risks=["class imbalance", "background leakage", "label noise"],)
print(plan)これはプロジェクトの境界を決めるオブジェクトです。これを埋められないなら、モデル選択はまだ早いです。
実験:プロトタイプ基準モデルと混同行列
Section titled “実験:プロトタイプ基準モデルと混同行列”この小さな例では、実画像の代わりに 3 つの疑似特徴量を使います。あとで CNN でも使う評価ループを学ぶためのものです。
image_project_baseline.py を作成します。
from collections import defaultdict
train_data = [ ("cat", [0.9, 0.8, 0.4]), ("cat", [0.8, 0.7, 0.5]), ("dog", [0.7, 0.5, 0.8]), ("dog", [0.6, 0.4, 0.9]), ("rabbit", [0.5, 0.9, 0.3]), ("rabbit", [0.4, 0.8, 0.2]),]
val_data = [ ("cat", [0.85, 0.75, 0.45]), ("dog", [0.65, 0.45, 0.85]), ("rabbit", [0.45, 0.85, 0.25]), ("dog", [0.82, 0.72, 0.42]),]
labels = ["cat", "dog", "rabbit"]
def prototypes(data): groups = defaultdict(list) for label, features in data: groups[label].append(features)
result = {} for label, rows in groups.items(): result[label] = [ round(sum(row[i] for row in rows) / len(rows), 3) for i in range(len(rows[0])) ] return result
def l1(a, b): return sum(abs(x - y) for x, y in zip(a, b))
def predict(features, protos): distances = {label: round(l1(features, proto), 3) for label, proto in protos.items()} pred = min(distances, key=distances.get) return pred, distances
protos = prototypes(train_data)print("prototypes")for label in labels: print(label, protos[label])
rows = []for gold, features in val_data: pred, distances = predict(features, protos) rows.append({"gold": gold, "pred": pred}) print("prediction", gold, "->", pred, distances)
cm = {g: {p: 0 for p in labels} for g in labels}for row in rows: cm[row["gold"]][row["pred"]] += 1
print("confusion_matrix")for gold in labels: print(gold, [cm[gold][p] for p in labels])
errors = [row for row in rows if row["gold"] != row["pred"]]print("accuracy:", round((len(rows) - len(errors)) / len(rows), 3))print("errors:", errors)実行します。
python image_project_baseline.py期待される出力:
prototypescat [0.85, 0.75, 0.45]dog [0.65, 0.45, 0.85]rabbit [0.45, 0.85, 0.25]prediction cat -> cat {'cat': 0.0, 'dog': 0.9, 'rabbit': 0.7}prediction dog -> dog {'cat': 0.9, 'dog': 0.0, 'rabbit': 1.2}prediction rabbit -> rabbit {'cat': 0.7, 'dog': 1.2, 'rabbit': 0.0}prediction dog -> cat {'cat': 0.09, 'dog': 0.87, 'rabbit': 0.67}confusion_matrixcat [1, 0, 0]dog [1, 1, 0]rabbit [0, 0, 1]accuracy: 0.75errors: [{'gold': 'dog', 'pred': 'cat'}]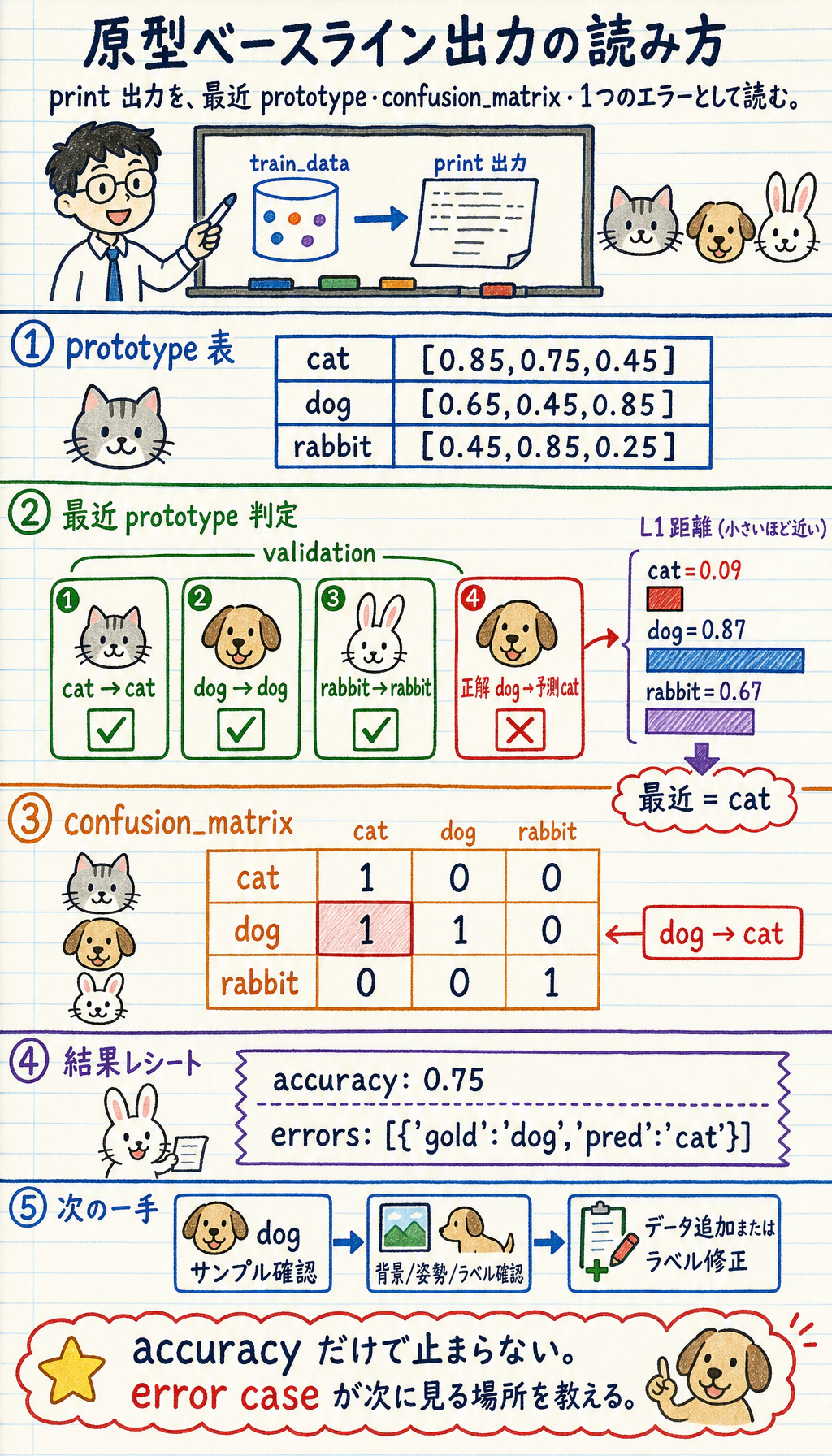
エラーの読み方:
- 最後の
dogサンプルはcatプロトタイプに近いです。 - 混同行列は
dog -> catを示しています。 - 次のアクションは、すぐ大きなモデルにすることではありません。dog 画像に cat らしい背景、姿勢、ラベル問題がないか確認します。
実プロジェクトの拡張ルート
Section titled “実プロジェクトの拡張ルート”| バージョン | 追加するもの | 見せる証拠 |
|---|---|---|
| ベースライン | small CNN または転移学習ベースライン | train/val 曲線、accuracy |
| 評価 | 混同行列とエラーサンプル | クラス単位の間違い |
| 頑健性 | augmentation と leakage checks | 前後比較 |
| 成果物 | README とデモコマンド | 再現可能な実行 |
実際の CNN プロジェクトでは、少なくとも次を残します。
- データセットディレクトリのスクリーンショット、またはクラス数の表。
- train/validation/test の分割ルール。
- ベースラインモデルの概要。
- 指標表。
- 混同行列。
- 6 から 12 個の正解例と誤答例。
- 次の改善計画。
画像分類プロジェクトでは、最低限この証拠を残します。
- ラベル規則
- クラスの定義方法
- 分割ルール
- train/val/test とリーク防止
- ベースライン
- 単純な CNN または転移学習のベースライン
- 指標
- accuracy と confusion matrix
- エラーケース
- 原因の見込みがある 1 つの誤予測
- 次の行動
- データ、augmentation、モデル、または split の変更
よくある間違い
Section titled “よくある間違い”| 間違い | 直し方 |
|---|---|
| accuracy だけ報告する | 混同行列とエラー例を見せる |
| 曖昧なクラスを選ぶ | データ収集前にラベル境界を定義する |
| 似た画像が train/test に漏れる | 必要なら出典や対象で分割する |
| 最初から巨大モデルを使う | 小さなベースラインを先に作る |
| 失敗例を隠す | 失敗例を次の改善の根拠にする |
dogの検証サンプルを 2 つ追加し、混同行列をもう一度作ってください。- 新しいクラス
hamsterを追加してください。labelsと行列はどう変わりますか。 dog -> catの誤分類について、考えられるデータ上の問題を 1 つ書いてください。- README でプロトタイプ基準モデルを小さな CNN の概要に置き換えてください。
- データセット、実行コマンド、指標、失敗例を含むプロジェクトチェックリストを作ってください。
プロジェクト参考とレビュー観点
- 混同行列の
dog行に証拠が増えます。追加サンプルが難しければ dog recall は下がるかもしれません。分かりやすいサンプルなら評価がより安定します。 labelsにhamsterを追加し、混同行列は新しい行と列を持つ形に広がります。クラス平均の指標表も新クラスを含める必要があります。- 例として、dog 画像が切り抜かれすぎている、ぼやけている、cat と似た姿勢が多い、dog サンプルが少ない、などが考えられます。大事なのは、エラーをデータ証拠と結びつけることです。
- README には、入力サイズ、convolution/ReLU/pooling blocks、classifier head、loss、metric、実行コマンド、期待される出力を書くとよいです。
- checklist は再現性を示すものにします。dataset split、training command、metric、confusion matrix、known failure cases、次の改善案を含めます。
- 画像分類プロジェクトはモデル名ではなく、全体の流れで評価されます。
- 混同行列はクラス単位の失敗を見せます。
- エラー例は恥ずかしいものではなくプロジェクトの証拠です。
- 強いポートフォリオプロジェクトは、何が改善し、何がまだ失敗するかを見せます。