7.5.4 構造化出力
- なぜ構造化出力が LLM アプリにとても重要なのかを理解する
- シンプルでわかりやすい JSON 出力形式を設計できるようになる
- フィールド設計、制約の説明、検証ロジックを理解する
- Prompt から JSON 解析までの最小の流れを理解する
- 「構造化出力」と「関数呼び出し」の違いと関係を区別できるようになる
一、なぜ自然言語だけでは足りないのか?
Section titled “一、なぜ自然言語だけでは足りないのか?”よくある壊れやすい場面
Section titled “よくある壊れやすい場面”たとえば、モデルにユーザーの意図を判定してほしいとします。
ユーザー入力:
「返金ポリシーについて知りたい」
モデルの返答が:
「このユーザーは返金関連の内容を知りたい可能性が高いので、返金モジュールに回すのがよさそうです。」
人間なら理解できます。 でも、プログラムはこの文を安定して使うのが難しいです。
なぜなら、プログラムがほしいのは次のような形だからです。
{ "intent": "refund_policy", "confidence": 0.92}本当の問題は何か?
Section titled “本当の問題は何か?”問題は、モデルが答えられないことではなく、次の点にあります。
自然言語の出力は自由すぎて、プログラムが安定して扱いにくい。
そのため、モデルの出力をさらに次へ渡す必要があるとき:
- フロントエンド
- バックエンド
- ワークフロー
- データベース
構造化出力は、ほぼ必須になります。
二、構造化出力とは何か?
Section titled “二、構造化出力とは何か?”一言で言うと
Section titled “一言で言うと”構造化出力 = あらかじめ決めたフィールドと形式に従って、モデルに結果を出させること。
よく使われる形式には次があります。
- JSON
- リスト
- 表
- 固定フィールドのオブジェクト
なぜ JSON が最もよく使われるのか?
Section titled “なぜ JSON が最もよく使われるのか?”理由は、次の3つを同時に満たすからです。
- 人間が読める
- プログラムが解析できる
- 構造がわかりやすい
そのため、LLM アプリでは JSON が構造化出力の第一候補になることが多いです。
スキーマを書く前に理解しておきたい用語
Section titled “スキーマを書く前に理解しておきたい用語”| 用語 | わかりやすい意味 | 実務での役割 |
|---|---|---|
| JSON | オブジェクト、配列、文字列、数値、真偽値、null で表す軽量なデータ形式 | モデル出力を json.loads() などでプログラムが解析できるようにする |
| スキーマ | 出力の形。フィールド名、型、許可値、必須項目を決めたもの | Prompt と下流プログラムの契約になる |
| フィールド(Field) | intent や confidence のような、名前付きのデータ項目 | フィールド名が安定していれば、バックエンドコードが迷わず値を読める |
| 検証 | 出力が解析可能か、項目が揃っているか、型が正しいかをプログラムで確認すること | 悪い出力が次の処理を壊す前に止められる |
| 列挙(Enum) | refund_policy / certificate / other のような固定の許可値集合 | モデルが似ているが不一致なラベルを勝手に作るのを防ぐ |
三、構造化出力で最も大事な設計ポイントは何か?
Section titled “三、構造化出力で最も大事な設計ポイントは何か?”フィールドは少なく、わかりやすく
Section titled “フィールドは少なく、わかりやすく”初心者がやりがちなミスは次の通りです。
- 最初から 20 個ものフィールドを設計する
- でも各フィールドの意味が安定していない
よりよい考え方は次です。
まずは最小限のフィールドで、最も重要な結果を表す。
たとえば、意図判定なら次のような形で十分です。
{ "intent": "refund_policy", "confidence": 0.92}フィールド名は安定させる
Section titled “フィールド名は安定させる”今日の名前が:
intent
明日になって:
user_intent
さらに明後日には:
task_type
となると、プログラム側はどんどん混乱します。
だから、構造化出力の大原則のひとつは次です。
フィールド名は安定させる。
四、最小の実行可能な例:JSON 文字列をプログラムで解析する
Section titled “四、最小の実行可能な例:JSON 文字列をプログラムで解析する”まずは最小の解析を見てみましょう
Section titled “まずは最小の解析を見てみましょう”import json
text = '{"intent": "refund_policy", "confidence": 0.92}'data = json.loads(text)
print(data)print("intent =", data["intent"])print("confidence =", data["confidence"])期待される出力:
{'intent': 'refund_policy', 'confidence': 0.92}intent = refund_policyconfidence = 0.92このコードはシンプルですが、意味は大きいです
Section titled “このコードはシンプルですが、意味は大きいです”このコードが教えてくれるのは次の2点です。
- 構造化出力は「JSONっぽく見える」だけではだめで、実際に解析できる必要がある
- 解析できれば、プログラムはフィールドを安定して取り出せる
つまり、構造化出力の価値は「見た目がきれいになること」ではなく、
後続のプログラムが本当に使えること。
にあります。
五、より実際のタスクに近い小さな例:ユーザー意図判定
Section titled “五、より実際のタスクに近い小さな例:ユーザー意図判定”モデルにこの形式で出力させるとします
Section titled “モデルにこの形式で出力させるとします”{ "intent": "refund_policy", "needs_human": false, "confidence": 0.92}モデル出力をまねしてプログラムで解析する
Section titled “モデル出力をまねしてプログラムで解析する”import json
mock_model_output = """{ "intent": "refund_policy", "needs_human": false, "confidence": 0.92}"""
data = json.loads(mock_model_output)
if data["intent"] == "refund_policy" and not data["needs_human"]: print("返金ポリシーの自動処理フローに入ります")else: print("人手対応、または別のフローに回します")
print(data)期待される出力:
返金ポリシーの自動処理フローに入ります{'intent': 'refund_policy', 'needs_human': False, 'confidence': 0.92}これが、実際のワークフローにおける構造化出力の典型的な使い方です。
六、Prompt はどう書けば、構造化出力が安定しやすいのか?
Section titled “六、Prompt はどう書けば、構造化出力が安定しやすいのか?”「JSON を出してください」だけでは不十分
Section titled “「JSON を出してください」だけでは不十分”より安定しやすい書き方には、通常次の要素が含まれます。
- フィールド名を明確にする
- フィールドの型を明確にする
- 出力は JSON のみに限定する
- 余計な説明を付けないように明示する
たとえば、次のように書きます。
ユーザー入力に対して意図判定を行い、厳密に JSON だけを出力してください。
フィールド要件:- intent: string、取りうる値は refund_policy / certificate / other- needs_human: boolean- confidence: float、範囲は 0 から 1
追加の説明は一切出力せず、JSON のみを出力してください。なぜこれで安定しやすくなるのか?
Section titled “なぜこれで安定しやすくなるのか?”これは単に「お願いしている」のではなく、
モデルに出力契約を定義している。
からです。
契約が明確なほど、結果も安定しやすくなります。
七、なぜ構造化出力でも検証が必要なのか?
Section titled “七、なぜ構造化出力でも検証が必要なのか?”モデルはコンパイラではないから
Section titled “モデルはコンパイラではないから”Prompt をどれだけ丁寧に書いても、モデルは次のようなミスをすることがあります。
- フィールドが抜ける
- 型を間違える
- 説明文を余計に付ける
- JSON が閉じていない

最小の検証例
Section titled “最小の検証例”import json
def validate_output(text): try: data = json.loads(text) except Exception: return False, "invalid_json"
required = ["intent", "needs_human", "confidence"] for field in required: if field not in data: return False, f"missing_{field}"
if not isinstance(data["intent"], str): return False, "intent_type_error" if not isinstance(data["needs_human"], bool): return False, "needs_human_type_error" if not isinstance(data["confidence"], (int, float)): return False, "confidence_type_error"
return True, data
good = '{"intent":"refund_policy","needs_human":false,"confidence":0.92}'bad = '{"intent":"refund_policy","confidence":"high"}'
print(validate_output(good))print(validate_output(bad))期待される出力:
(True, {'intent': 'refund_policy', 'needs_human': False, 'confidence': 0.92})(False, 'missing_needs_human')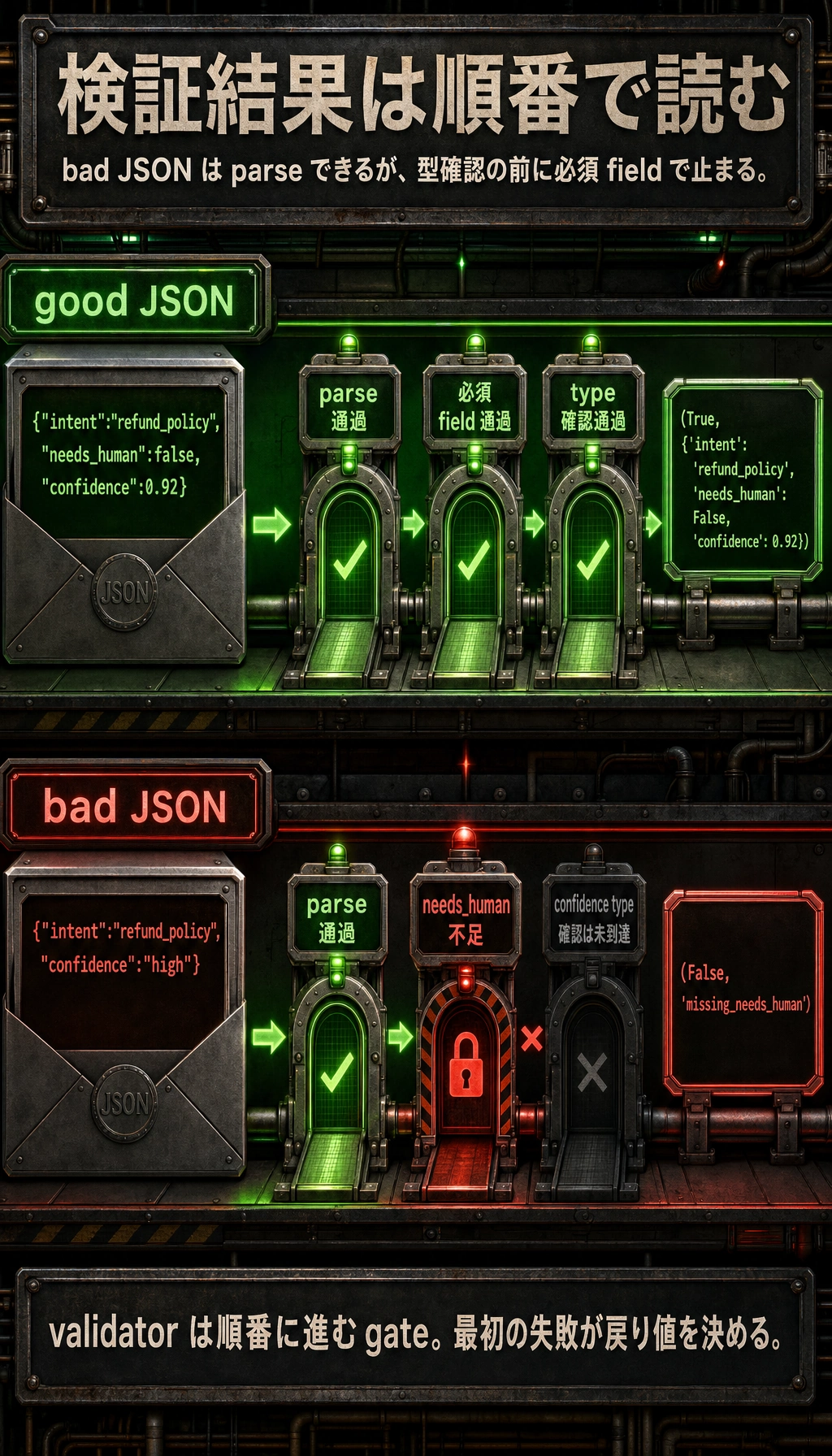
このステップはとても重要です。なぜなら、システムは次の状態から:
- 「モデルはたぶんこう出力するだろう」
次の状態へ変わるからです。
- 「プログラムが出力の合否を明確に判断できる」
八、構造化出力と 関数呼び出し の関係は?
Section titled “八、構造化出力と 関数呼び出し の関係は?”どちらも、次のことを目指しています。
自由な文章ではなく、プログラムが受け取りやすい形式でモデル出力を得る。
ざっくり言うと、次のように理解できます。
- 構造化出力:より広い概念で、「結果形式を安定させる」ことが中心
- 関数呼び出し(関数呼び出し):さらに進んで、「ツールを呼ぶ意図」を出力することが中心
たとえば:
- 構造化出力:分類結果の JSON を出す
- 関数呼び出し(関数呼び出し):
{name, arguments}を出してツールを呼ぶ
つまり、次のように考えられます。
関数呼び出し は、構造化出力の中でも実行寄りの形です。
九、固定形式の Word / PPT を生成したいなら、スキーマ はどう設計すべきか?
Section titled “九、固定形式の Word / PPT を生成したいなら、スキーマ はどう設計すべきか?”目標が次のような場合は:
- サポート triage レポートを生成する
- リリースレビュー報告書を生成する
- 固定項目の文書を生成する
構造化出力で最も大事なのは、「JSON を出して」と言うことよりも、 まず schema をしっかり設計することです。
インシデントレビュー報告書に向いた最小の schema は、次のような形になります。
{ "title": "パスワードリセット障害レビュー", "audience": "サポート運用チーム", "objective": ["根本原因を特定する", "次の対応を決める"], "sections": [ {"type": "summary", "heading": "インシデント概要", "items": ["09:10 から 09:40 まで、ユーザーが reset email を受信できなかった"]}, {"type": "evidence", "heading": "根拠", "items": ["email queue latency の最大値が 14 分に達した"]}, {"type": "action", "heading": "次の対応", "items": ["queue latency alert を追加し、status page 更新テンプレートを公開する"]} ], "source_refs": [{"doc_id": "incident_042", "page_or_slide": 3}]}初心者が特に注目すべき点は次の通りです。
- フィールドは多ければよいわけではない
- 後続のテンプレート描画や出典の追跡を動かせるだけの内容があればよい
十、実務でよくある落とし穴
Section titled “十、実務でよくある落とし穴”フィールドを増やしすぎる
Section titled “フィールドを増やしすぎる”フィールドが多いほど、モデルは間違えやすくなり、後処理も複雑になります。
フィールドの意味が安定しない
Section titled “フィールドの意味が安定しない”たとえば confidence が、あるときは 0〜1、別のときは百分率、という設計は危険です。
解析と検証をしない
Section titled “解析と検証をしない”多くのデモは動いて見えますが、実際にプログラムへつなぐと壊れます。原因はたいていここです。
出力の構造と業務フローがつながっていない
Section titled “出力の構造と業務フローがつながっていない”JSON がきれいでも、その後の処理を直接動かせなければ、構造化出力としては十分ではありません。
構造化出力の合格チェック表
Section titled “構造化出力の合格チェック表”構造化出力は「JSON に見える」だけでは成功ではありません。プログラムが安定して受け取れることが必要です。schema を設計したら、毎回この表で確認できます。
| チェック項目 | 合格の状態 | よくある問題 |
|---|---|---|
| 解析可能 | json.loads() でそのまま解析できる | 前後に説明文が混ざる、JSON が閉じていない |
| フィールドが揃っている | 必須フィールドがすべて存在する | フィールドの欠落、名前の揺れが多い |
| 型が正しい | string、boolean、number、array などの型が安定している | confidence が数字だったり「高」だったりする |
| 列挙が制御されている | 分類フィールドが許可値の範囲内に収まる | intent が似たような言葉でバラつく |
| 業務で使える | 出力がそのまま後続フローを動かせる | JSON は完全でも、バックエンドが使い方を知らない |
| 失敗を判定できる | invalid_json、missing_field、type_error を判定できる | 失敗がすべて「解析失敗」だけになる |
この表を通らない場合は、まず Prompt の文面を何度も直すより、schema と検証ロジックを見直しましょう。
なぜ Prompt のバージョン管理が重要なのか
Section titled “なぜ Prompt のバージョン管理が重要なのか”構造化出力を改善し始めたら、Prompt もコードと同じようにバージョン管理すべきです。そうしないと、どの修正で出力がよくなったのか、どの修正で新しい問題が入ったのかを答えにくくなります。
| フィールド | 例 | 役割 |
|---|---|---|
prompt_version | intent_schema_v2 | 現在の提示文バージョンを示す |
change_reason | needs_human フィールドを追加 | なぜ変更したかを説明する |
test_inputs | 20 件の固定入力 | 同じサンプルで安定性を比較する |
pass_rate | 18/20 | 構造化出力の通過率を記録する |
failure_cases | フィールド欠落 2 件 | 次回改善の根拠を残す |
簡単な記録は次のように書けます。
バージョン:intent_schema_v2変更:needs_human フィールドを追加し、confidence は 0 から 1 の数値に限定した評価:20 件のテスト入力で、18 件が解析と検証を通過失敗:2 件で confidence="高" が出力された結論:フィールドは維持しつつ、prompt で confidence の型をもっと強調するこの習慣があると、Prompt 工学は「試してみる」から「記録しながら改善する」へ変わります。
構造化出力の失敗サンプルはどう記録するか
Section titled “構造化出力の失敗サンプルはどう記録するか”失敗サンプルは、「モデルが形式どおりに出さなかった」とだけ書くのではなく、タイプ別に記録するのがおすすめです。
| 失敗タイプ | 例 | 修正方針 |
|---|---|---|
invalid_json | 右括弧が足りない | JSON のみを出すようにし、解析失敗時の再試行を追加する |
missing_field | needs_human がない | フィールド要件に必須項目を明記する |
type_error | confidence が文字列になる | 型と範囲を明確にする |
enum_error | intent が refund で、refund_policy ではない | 選択肢を明示し、勝手な分類を禁止する |
extra_text | JSON の前後に説明が付く | 余計な説明を出さないように明示する |
失敗サンプルが具体的であるほど、次の回帰テストがやりやすくなります。実務では、構造化出力の安定性は一度完璧な Prompt で決まるのではなく、schema、検証、失敗記録、回帰サンプルをまとめて整えることで高まります。
このページを終えたら、この証拠カードを残します。
- スキーマ
- 必須フィールドと許可された型
- パーサー
- 出力は解析されるもので、見た目をそのまま信頼しない
- 有効ケース
- 検証で受け入れられる 1 つの出力
- 無効ケース
- 欠落フィールドまたは誤った型が拒否される
- 修復ルール
- 再試行、フォールバック、または明確化を求める
この節で最も大事なのは、JSON の文法を覚えることではなく、次の点を理解することです。
構造化出力の本質は、モデルの回答をプログラムが安定して使える中間結果に変えること。
モデルを実際のシステムに組み込むとき、これは「回答をきれいにする」ことよりも、ずっと重要になることが多いです。
- 「授業 Q&A ルーティング」の JSON 出力形式を設計し、少なくとも
intent、confidence、needs_humanの3つのフィールドを含めてください。 - わざとフィールドが欠けた JSON を作り、検証器が止められるか確認してください。
- いつ構造化出力を使うべきで、いつは自然言語だけで十分なのかを考えてみてください。
- 自分の言葉で説明してください。なぜ構造化出力は、Prompt 工学がエンジニアリングとして成熟するための重要な一歩なのか。
解法と解説
- 例:
{"intent": "billing|course_help|technical_issue|other", "confidence": 0.0, "needs_human": false, "reason": "short explanation"}。 intent、confidence、needs_humanが required なら、missing field は validation failure になるべきです。bad output は product logic に入る前に止めます。- routing、storage、scoring、action trigger に別 program が使う場合は structured output が向いています。人が読むだけなら natural language で十分なこともあります。
- structured output は prompt response を interface contract に変えます。これにより prompt work は testable、automatable、maintainable になります。