5.6.1 機械学習プロジェクトロードマップ:baseline、証拠、改善
この小章は第5章の出口です。データ問題を、評価でき、説明でき、ポートフォリオに見せられるモデリングフローへ変えられることを確認します。
まずプロジェクトループを見る
Section titled “まずプロジェクトループを見る”
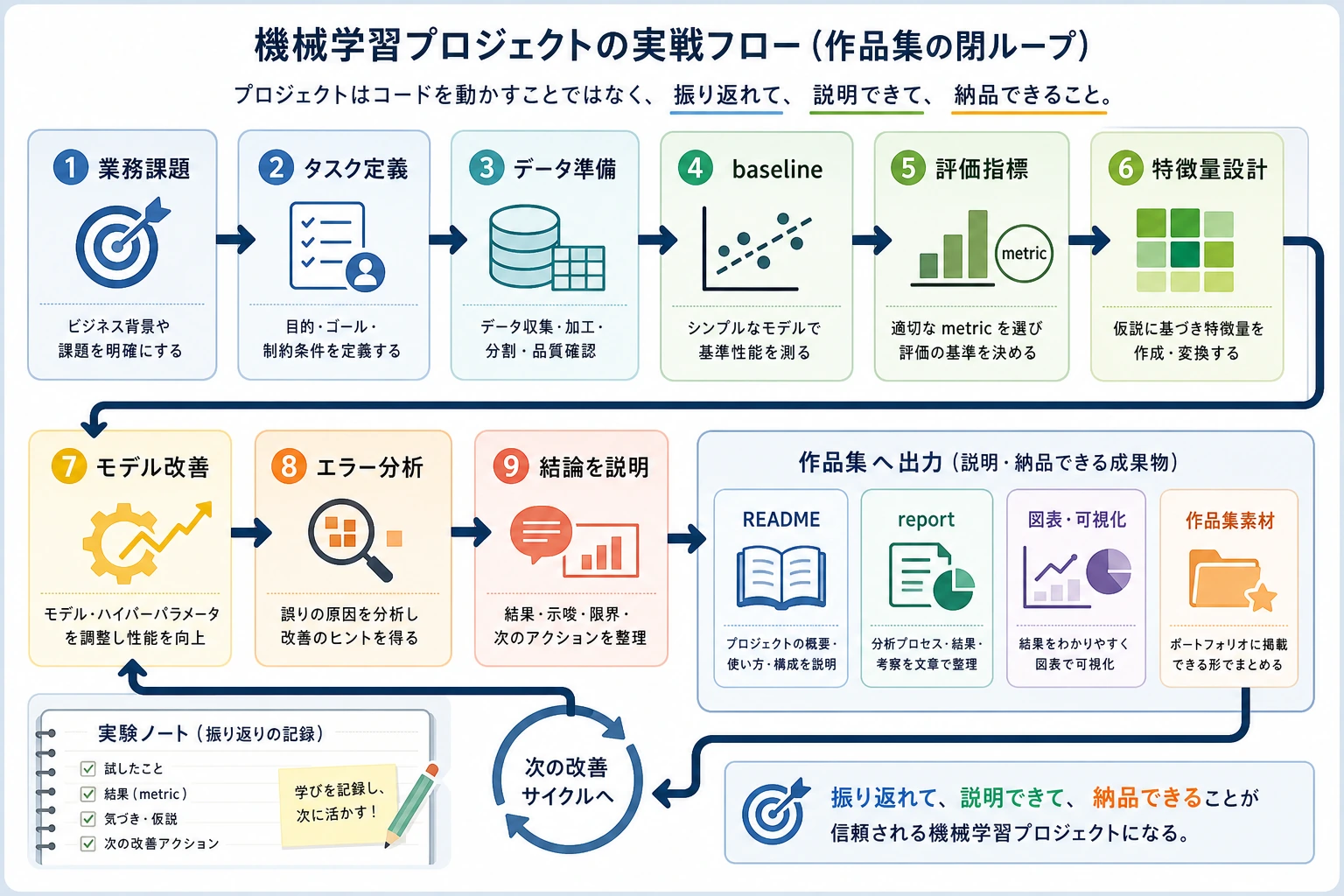
このプロジェクトループを覚えます。
問題データbaseline指標改善失敗例レポート
いきなり複雑なモデルに進まないでください。ベースライン、指標、失敗分析がないプロジェクトは、ただのデモ実行になりがちです。
実験ログを1つ残す
Section titled “実験ログを1つ残す”ml_project_log_first_loop.py を作ります。これはモデルではなく、すべてのモデルプロジェクトに必要な習慣です。
experiments = [ {"version": "v1_baseline", "metric": 0.72, "change": "default model"}, {"version": "v2_features", "metric": 0.78, "change": "add ratio features"}, {"version": "v3_tuned", "metric": 0.80, "change": "tune max_depth"},]
best = max(experiments, key=lambda row: row["metric"])
print("best_version:", best["version"])print("best_metric:", best["metric"])print("next_step: inspect failure cases before adding more models")出力:
best_version: v3_tunedbest_metric: 0.8next_step: inspect failure cases before adding more modelsここでの変化は、「モデルを動かした」から「バージョンを比較し、次の一手を説明できる」へ移ることです。
このページを終えたら、この evidence card を残します。
- プロジェクト目標
- 予測、セグメンテーション、Kaggle、またはエンドツーエンドの ML ポートフォリオ対象
- パイプライン
- データ分割、前処理、モデル、評価、レポート成果物
- 結果
- metric 表、chart、予測、失敗サンプル、README の注記
- 失敗確認
- 再現不可能な実行、リーク、過学習、弱いベースライン、またはデプロイ境界の不足
- 期待される成果
- パイプライン、メトリクス、失敗レビューを含む ML プロジェクトフォルダ
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | 提出するもの |
|---|---|---|
| 1 | 5.6.2 住宅価格予測 | 回帰 baseline と改善 |
| 2 | 5.6.3 顧客離脱予測 | 分類指標としきい値の考え方 |
| 3 | 5.6.4 ユーザーセグメンテーション | クラスタ解釈と業務ラベル |
| 4 | 5.6.5 Kaggle 実践 | 実際の提出フロー |
| 5 | 5.6.6 ML 実践ワークショップ | 完全な証拠パックの練習 |
ワークショップを最後に置くのは、前のプロジェクト習慣を再現可能な証拠パックにまとめるためです。
プロジェクト成果物基準
Section titled “プロジェクト成果物基準”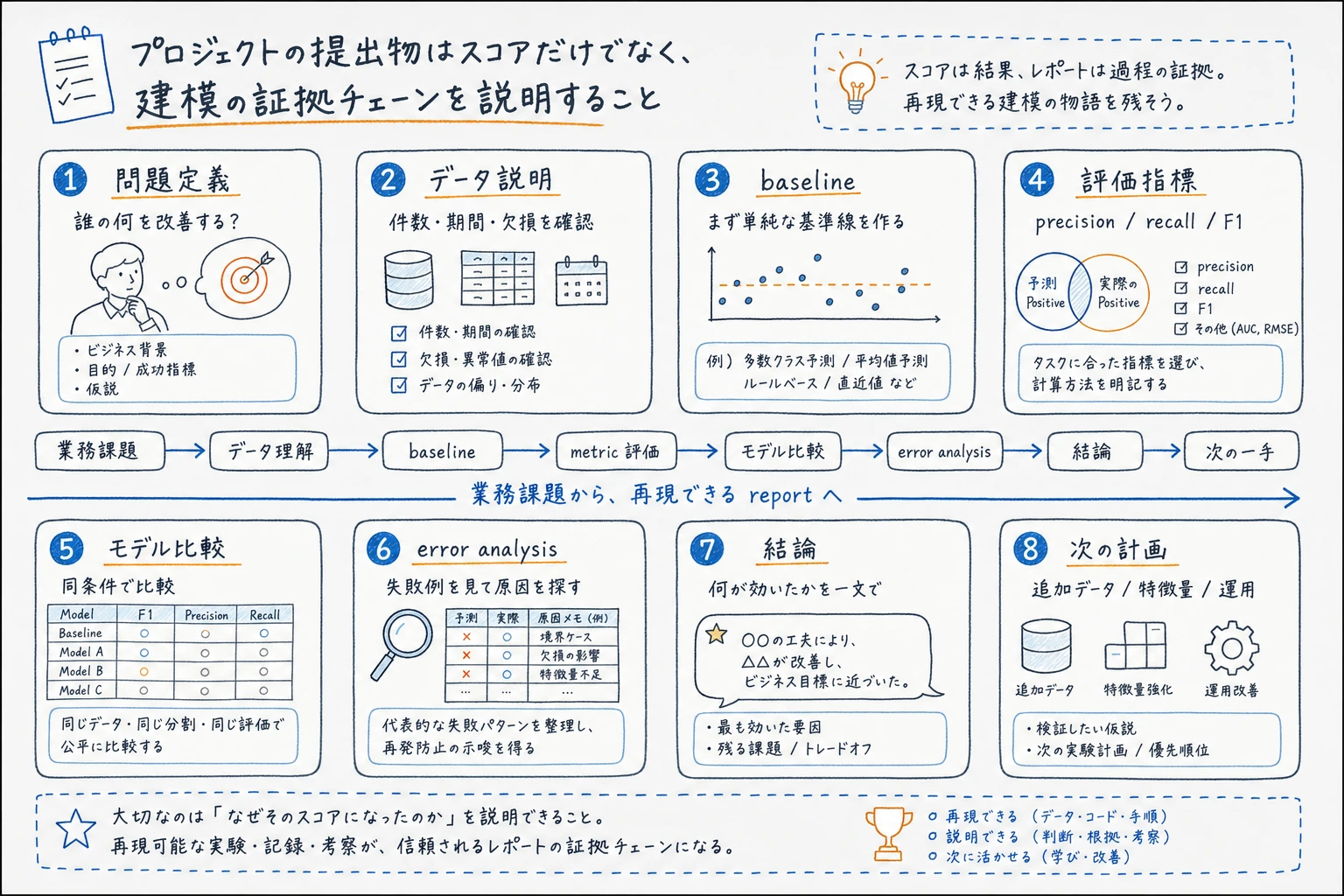
少なくとも1つのプロジェクトで、README.md、実行コマンド、指標表、実験ログ、失敗例1つ、グラフ1つ、次の改善案を残します。
タスクをどう定義したか、どの baseline を使ったか、どの指標を信頼したか、何が改善したか、どこで失敗したか、次に何をするかを説明できれば合格です。
確認の考え方と解説
- 完全な答えでは、モデル名より先にタスク種類、目的変数、成功指標を定義します。
- baseline は、固定 split、最小限の前処理、1 つのモデル、1 つの指標表からなる、最も単純で再現可能な版です。
- 改善は同じ split または同じ検証方法で比べたときだけ信頼できます。split とモデルを同時に変えると、何が効いたか説明しにくくなります。
- 失敗分析では、モデルが弱いサンプル種類やセグメントを少なくとも 1 つ挙げ、それを次の制御された実験に変えます。
- 合格するプロジェクトフォルダには、実行コマンド、README、実験ログ、指標表、グラフ、失敗例、次の改善案が含まれます。