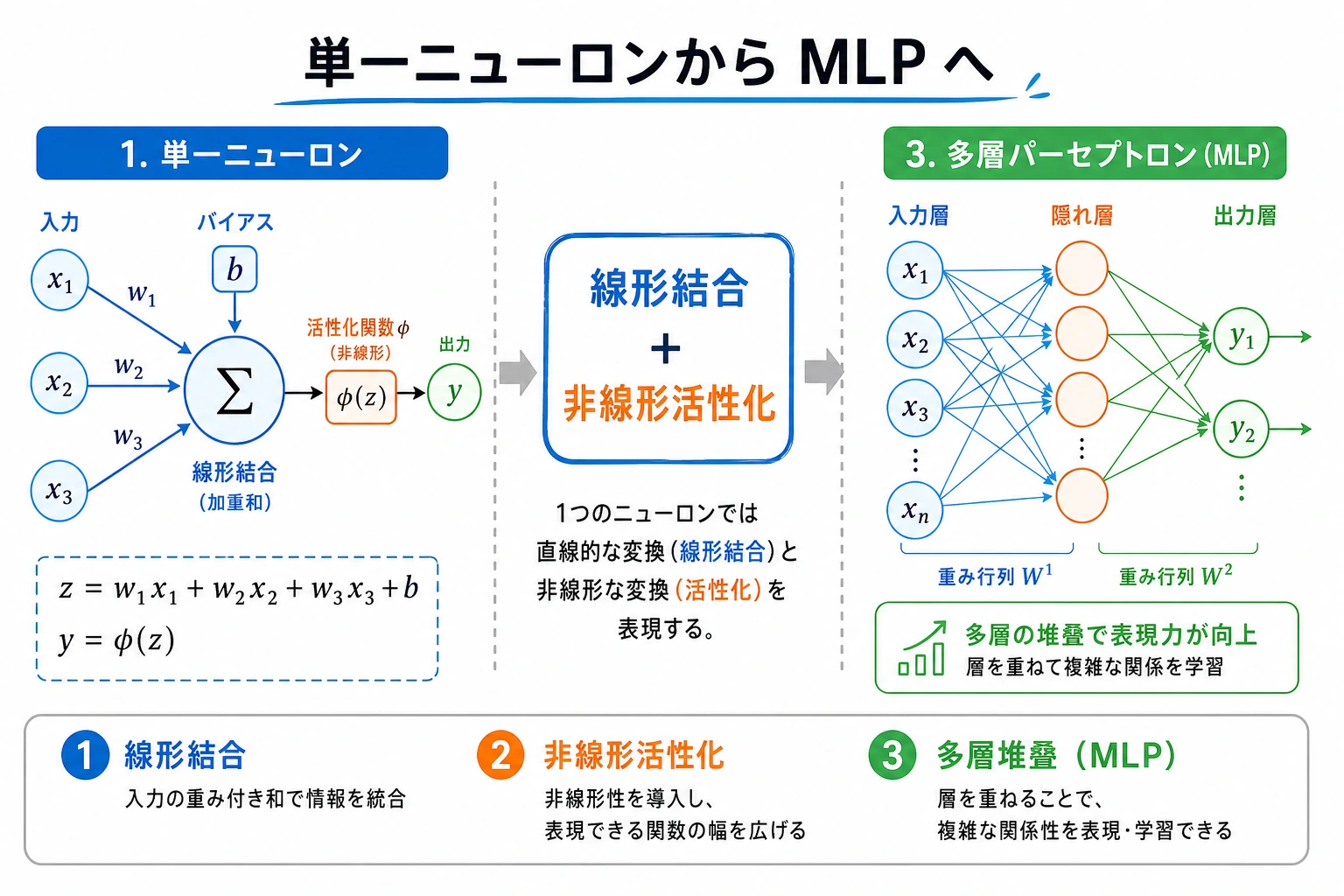
6.1.3 ニューロンから多層パーセプトロンへ
この節では、小さな PyTorch 実験を実行します。
- 人工ニューロンを手で計算する;
sigmoidとReLUを比較する;- 小さな MLP で XOR を解く;
- 1 つの線形層だけでは足りない理由を説明する。
中心となる流れは次です。
featuresweighted sum zactivation alayermultilayer network
最小限の歴史
Section titled “最小限の歴史”パーセプトロンが人々を興奮させたのは、機械がデータからルールを学べることを示したからです。その後、XOR のような単純な非線形パターンを単層パーセプトロンが解けないことが明らかになりました。
この歴史から学ぶべきことは次です。
ニューロン自体は単純。表現力を生むのは、非線形活性化を持つ層の積み重ね。
セットアップ
Section titled “セットアップ”python -m pip install -U torchコードでは安定した PyTorch API を使います:torch.Tensor、nn.Module、nn.Sequential、nn.Linear、活性化関数、loss、optimizer です。
完全な実験を実行する
Section titled “完全な実験を実行する”neuron_mlp_lab.py を作成します。
import torchimport torch.nn as nn
torch.manual_seed(42)
x = torch.tensor([[0.8, 0.3, 0.5]])w = torch.tensor([[0.2], [-0.4], [0.6]])b = torch.tensor([0.1])z = x @ w + bprint("single_neuron")print("z=", round(float(z.item()), 3))print("sigmoid=", round(float(torch.sigmoid(z).item()), 3))print("relu=", round(float(torch.relu(z).item()), 3))
xor_x = torch.tensor([[0., 0.], [0., 1.], [1., 0.], [1., 1.]])xor_y = torch.tensor([[0.], [1.], [1.], [0.]])
class TinyMLP(nn.Module): def __init__(self): super().__init__() self.net = nn.Sequential( nn.Linear(2, 4), nn.Tanh(), nn.Linear(4, 1), nn.Sigmoid(), )
def forward(self, x): return self.net(x)
model = TinyMLP()loss_fn = nn.BCELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
for step in range(2000): pred = model(xor_x) loss = loss_fn(pred, xor_y) optimizer.zero_grad() loss.backward() optimizer.step()
with torch.no_grad(): prob = model(xor_x) pred = (prob >= 0.5).float()print("xor_mlp")for row, p, y_hat in zip(xor_x.tolist(), prob.squeeze().tolist(), pred.squeeze().tolist()): print(f"x={row} prob={p:.3f} pred={int(y_hat)}")print("final_loss=", round(float(loss.item()), 4))実行します。
python neuron_mlp_lab.py期待される出力:
single_neuronz= 0.44sigmoid= 0.608relu= 0.44xor_mlpx=[0.0, 0.0] prob=0.000 pred=0x=[0.0, 1.0] prob=1.000 pred=1x=[1.0, 0.0] prob=1.000 pred=1x=[1.0, 1.0] prob=0.000 pred=0final_loss= 0.0001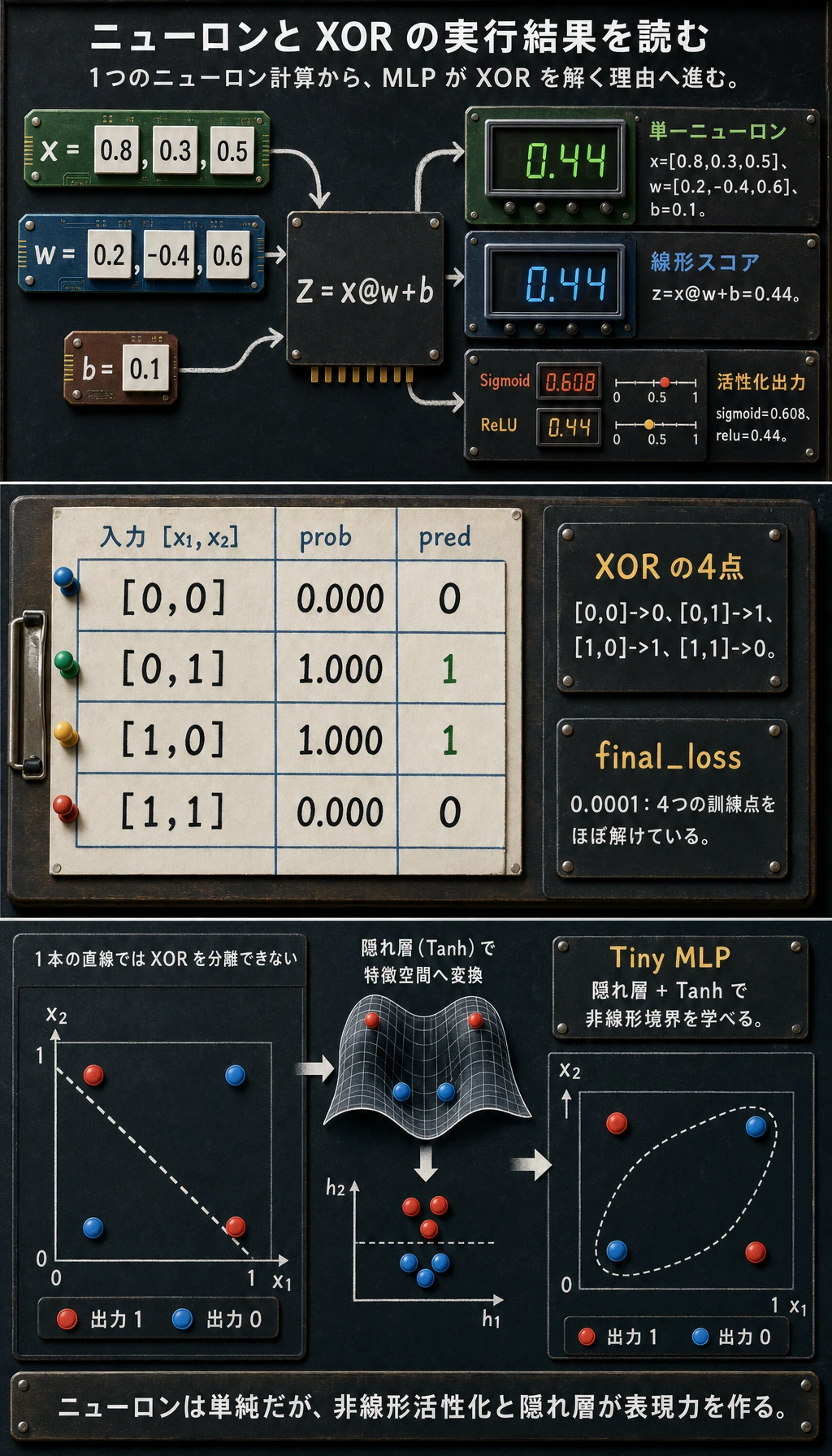
1 つのニューロンを読む
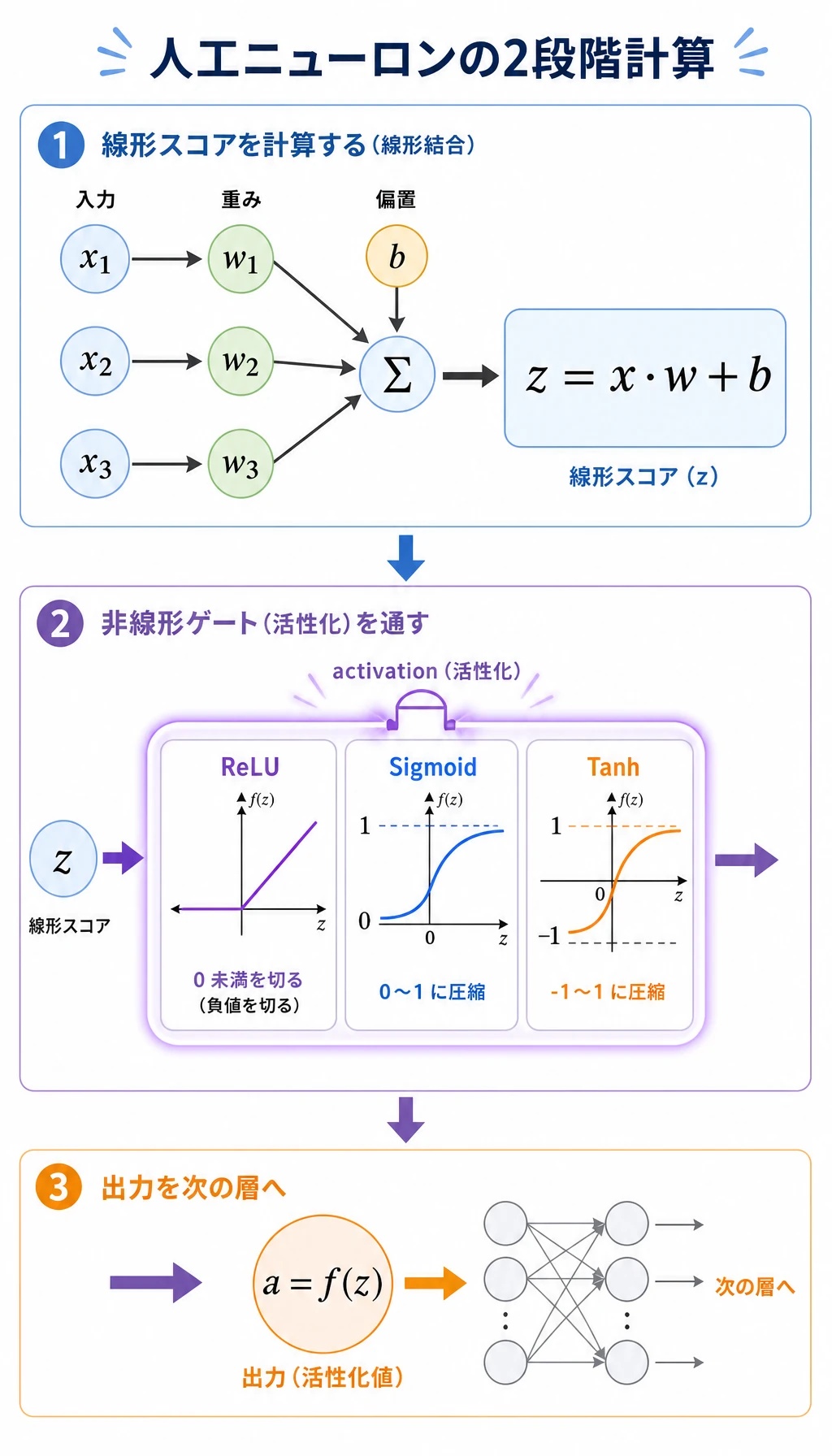
Section titled “1 つのニューロンを読む”最初の部分は次を計算しています。
z = x @ w + b出力では:
z= 0.44sigmoid= 0.608relu= 0.44重み付きスコア z はまだ線形です。活性化関数が、信号をどう次へ渡すかを変えます。
| 活性化 | すること | よく使う場面 |
|---|---|---|
Sigmoid | 0-1 に押し込む | 二値分類の確率出力 |
Tanh | -1 から 1 に押し込む | 小さなデモ、一部の系列モデル |
ReLU | 正の値を残し、負の値を 0 にする | 隠れ層の一般的な既定選択 |
活性化関数が重要な理由
Section titled “活性化関数が重要な理由”線形層だけを積み重ねても、全体としては 1 つの大きな線形層と等価です。非線形活性化があるから、層を重ねたネットワークは曲がった境界を表現できます。
そのため、この MLP は次を使います。
nn.Linear(2, 4),nn.Tanh(),nn.Linear(4, 1),nn.Sigmoid(),隠れ層の Tanh が非線形の表現力を与えます。最後の Sigmoid は、二値分類向けの確率らしい値に変換します。
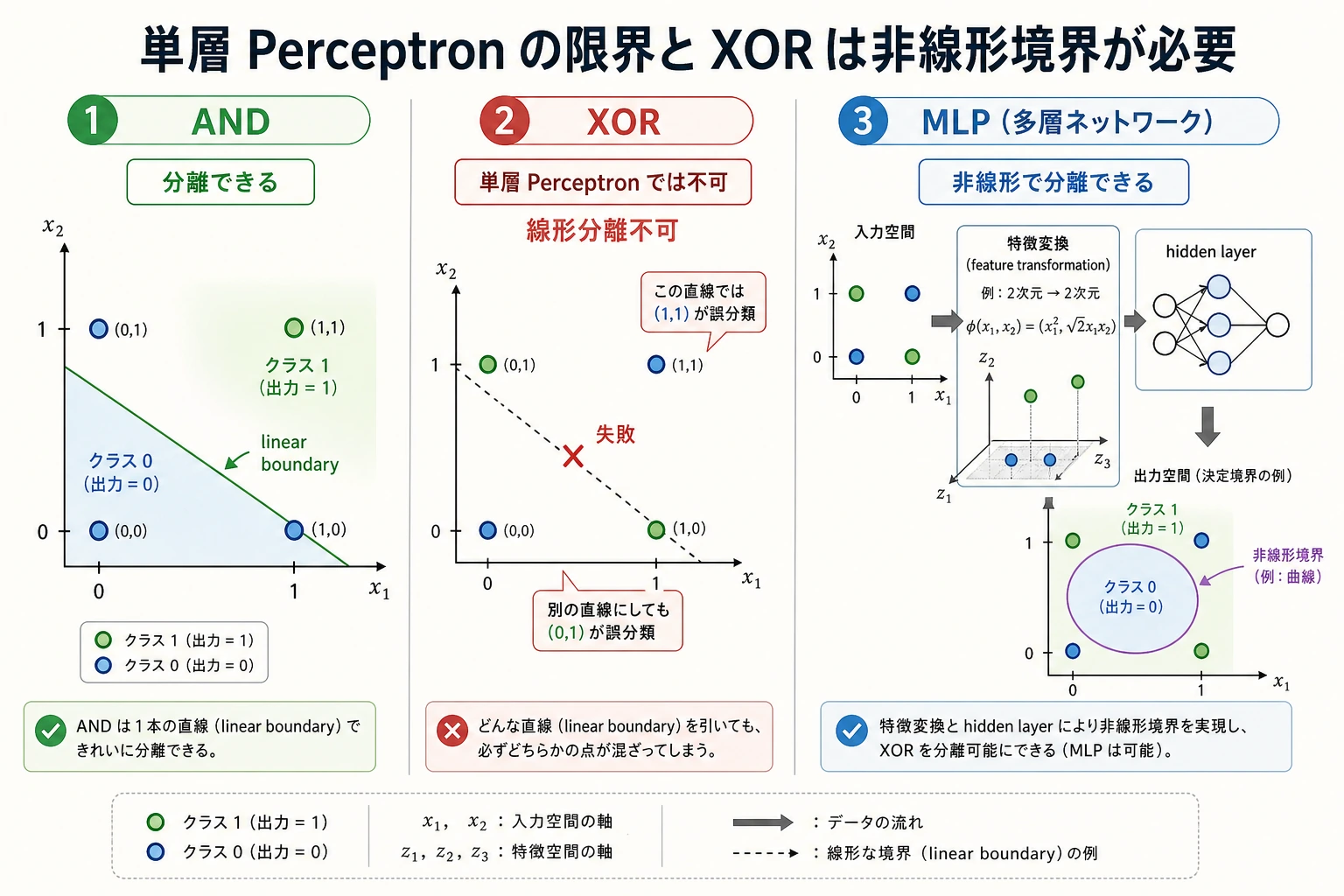
XOR が古典的なテストである理由
Section titled “XOR が古典的なテストである理由”XOR は 4 行だけです。
| x1 | x2 | y |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
直線 1 本では、このラベルを分けられません。だから単層パーセプトロンは失敗します。小さな MLP が成功するのは、最終判断の前に中間の隠れ特徴を作れるからです。
次の小さな結果カードを残します。
- 単一ニューロン
- z = x @ w + b、活性化がシグナルを変える
- xor結果
- 小さな MLP で [0, 1, 1, 0] を復元
- 中核理由
- 非線形な隠れ層が中間特徴を作る
- 失敗プローブ
- 隠れ活性を取り除いて final_loss を比較する
重要なのは、toy model が 4 行を覚えたことではありません。非線形性によって、層を重ねたモデルが表現できる形が変わることです。
よくあるトラブル
Section titled “よくあるトラブル”| 症状 | よくある原因 | 修正 |
|---|---|---|
| loss が下がらない | 学習率が高すぎる/低すぎる、loss の組み合わせが違う | LR を下げ、出力活性化と loss の組み合わせを確認する |
| 確率がすべて 0.5 付近 | モデルが学習していない | 長く訓練し、勾配を見て、hidden size を変える |
| output shape エラー | target shape と prediction が違う | この二値例では target を [batch, 1] にする |
nan が出る | 学習が不安定 | 学習率を下げ、入力を確認する |
| 訓練データは解けるが実データで弱い | 訓練データを記憶している | train/validation split と正則化を使う |
- 隠れユニットを
4から2に変えてください。XOR は安定して学習できますか? nn.Tanh()をnn.ReLU()に置き換えてください。結果は変わりますか?- 200 step ごとに loss を表示し、学習曲線を見てください。
- 隠れ層の活性化関数を外し、なぜ弱くなるか説明してください。
- 隠れ層をもう 1 つ追加し、final loss を比較してください。
参考実装と解説
- 隠れユニットを 2 にすると表現力が下がり、XOR の学習は不安定になりやすいです。複数回実行して seed による差も確認してください。
- ReLU でも学習できることがありますが、小さな XOR では初期値や学習率の影響を受けやすく、Tanh より曲線が荒れる場合があります。
- 200 step ごとの loss は、学習が進んでいるか、途中で止まっているかを確認するための最小ログです。
- 活性化関数を外すと、線形層を重ねても全体は線形変換のままです。XOR のような非線形境界を表しにくくなります。
- 隠れ層を追加すると容量は増えますが、小さなデータでは必ず改善するとは限りません。final loss と安定性を両方見ます。
合格チェック
Section titled “合格チェック”次を説明できれば、この節はクリアです。
- ニューロンは
x @ w + bを計算し、その後に活性化を適用する; - 活性化関数は非線形性を加える;
- 単層パーセプトロンは XOR を解けない;
- MLP は層を積み重ねて中間特徴を作る;
- PyTorch モデルは通常
nn.Module、loss、optimizer、backward()、step()を組み合わせる。