9.8.2 Agent 評価方法
- Agent 評価と通常の LLM 評価の違いを理解する
- タスク成功率、ツール呼び出し、プロセス品質の指標を設計できるようになる
- 評価用のリプレイサンプルを構築する方法を知る
- 評価結果を次の Prompt、ツール、フロー改善に活かせるようになる
なぜ Agent の評価はより複雑なのか
Section titled “なぜ Agent の評価はより複雑なのか”普通の QA システムは主に答えが正しいかを見るだけですが、Agent は答えを得るまでに何をしたかも見なければなりません。最終的には正解でも、途中で使うべきでないツールを呼んだり、確認を飛ばしたり、コストが高すぎたりすれば、よいシステムとは言えません。
flowchart LR A[ユーザーのタスク] --> B[計画] B --> C[ツール呼び出し] C --> D[状態更新] D --> E[最終結果] B --> F[プロセス品質] C --> G[安全性と権限] E --> H[タスク成功]4層の評価フレームワーク
Section titled “4層の評価フレームワーク”| レベル | 重要な問い | 指標の例 |
|---|---|---|
| 結果層 | ユーザーの目標は達成できたか | タスク成功率、人的評価、完了度 |
| プロセス層 | 実行経路は妥当か | ステップ数、再試行回数、ループ率、計画品質 |
| ツール層 | ツールは正しく使えたか | ツール選択精度、パラメータエラー率、ツール失敗率 |
| 安全層 | 権限逸脱や暴走はないか | 高リスク確認率、拒否精度、ロールバック適用率 |
実際のプロジェクトでは、最初から全部の指標を完璧にしようとしないでください。まずはタスク成功率、ツール失敗率、人的介入率、平均コストから始めるだけでも、多くの問題を見つけられます。

評価タスクセットを作る
Section titled “評価タスクセットを作る”Agent の評価セットは、理想的な例を少し並べるのではなく、実際のタスクから作るべきです。各サンプルには、ユーザー要求、期待結果、許可されたツール、禁止動作、成功基準、リスクレベルを含めるのがおすすめです。
{ "task_id": "rag_review_001", "user_request": "RAG の復習を手伝って", "allowed_tools": ["search_docs", "write_plan"], "forbidden_actions": ["delete_file", "send_message"], "success_criteria": ["RAG の基礎をカバーしている", "評価方法を含む", "コース文書を引用している"], "risk_level": "low"}人的評価シート
Section titled “人的評価シート”初期段階で最も実用的なのは人的評価です。1〜5 点で、タスク完了度、プロセスの妥当性、ツール使用、安全境界、表現のわかりやすさを評価できます。
| 観点 | 1 点 | 5 点 |
|---|---|---|
| タスク完了 | 目標から外れている | 目標を完全に満たしている |
| ツール使用 | 選択ミスまたは使い忘れ | ツール選択もパラメータも妥当 |
| プロセス制御 | ループ、冗長、説明不能 | 手順が明確で追跡できる |
| 安全境界 | 権限逸脱または未確認 | 高リスク操作に確認と縮退がある |
| コスト効率 | 明らかに無駄が多い | ステップ数と token が妥当 |
リプレイできる評価記録
Section titled “リプレイできる評価記録”Agent システムでは、点数だけがあって実行軌跡がないと、改善が難しくなります。よりよい評価記録では、最終スコアと実行プロセスの両方を残します。
{ "task_id": "rag_review_001", "run_id": "prompt_v3_model_a_2026_05_04", "task_success": true, "human_score": 4, "steps": 5, "tool_calls": [ {"tool": "search_docs", "ok": true, "reason": "RAG の章が見つかった"}, {"tool": "write_plan", "ok": true, "reason": "1週間の計画を生成した"} ], "safety_events": [], "cost_usd": 0.08, "main_issue": "出典は示したが、章リンクがまだ十分に具体的ではない"}この構造を保存する理由はシンプルです。
task_successはユーザー目標が達成されたかを示すstepsは Agent が効率的だったかを示すtool_callsはツールの経路が正しかったかを示すsafety_eventsは危険な行動があったかを示すmain_issueは次に何を改善すべきかを示す
まずは、とても小さな集計スクリプトから始められます。
runs = [ { "task_id": "rag_review_001", "task_success": True, "human_score": 4, "steps": 5, "tool_calls": [ {"tool": "search_docs", "ok": True}, {"tool": "write_plan", "ok": True}, ], "cost_usd": 0.08, }, { "task_id": "rag_review_002", "task_success": False, "human_score": 2, "steps": 9, "tool_calls": [ {"tool": "search_docs", "ok": False}, {"tool": "search_docs", "ok": False}, ], "cost_usd": 0.19, },]
total = len(runs)success_rate = sum(run["task_success"] for run in runs) / totalaverage_score = sum(run["human_score"] for run in runs) / totalaverage_steps = sum(run["steps"] for run in runs) / totaltool_calls = [call for run in runs for call in run["tool_calls"]]tool_failure_rate = sum(not call["ok"] for call in tool_calls) / len(tool_calls)
print(f"success_rate: {success_rate:.0%}")print(f"average_score: {average_score:.1f}/5")print(f"average_steps: {average_steps:.1f}")print(f"tool_failure_rate: {tool_failure_rate:.0%}")実行結果の例:
success_rate: 50%average_score: 3.0/5average_steps: 7.0tool_failure_rate: 50%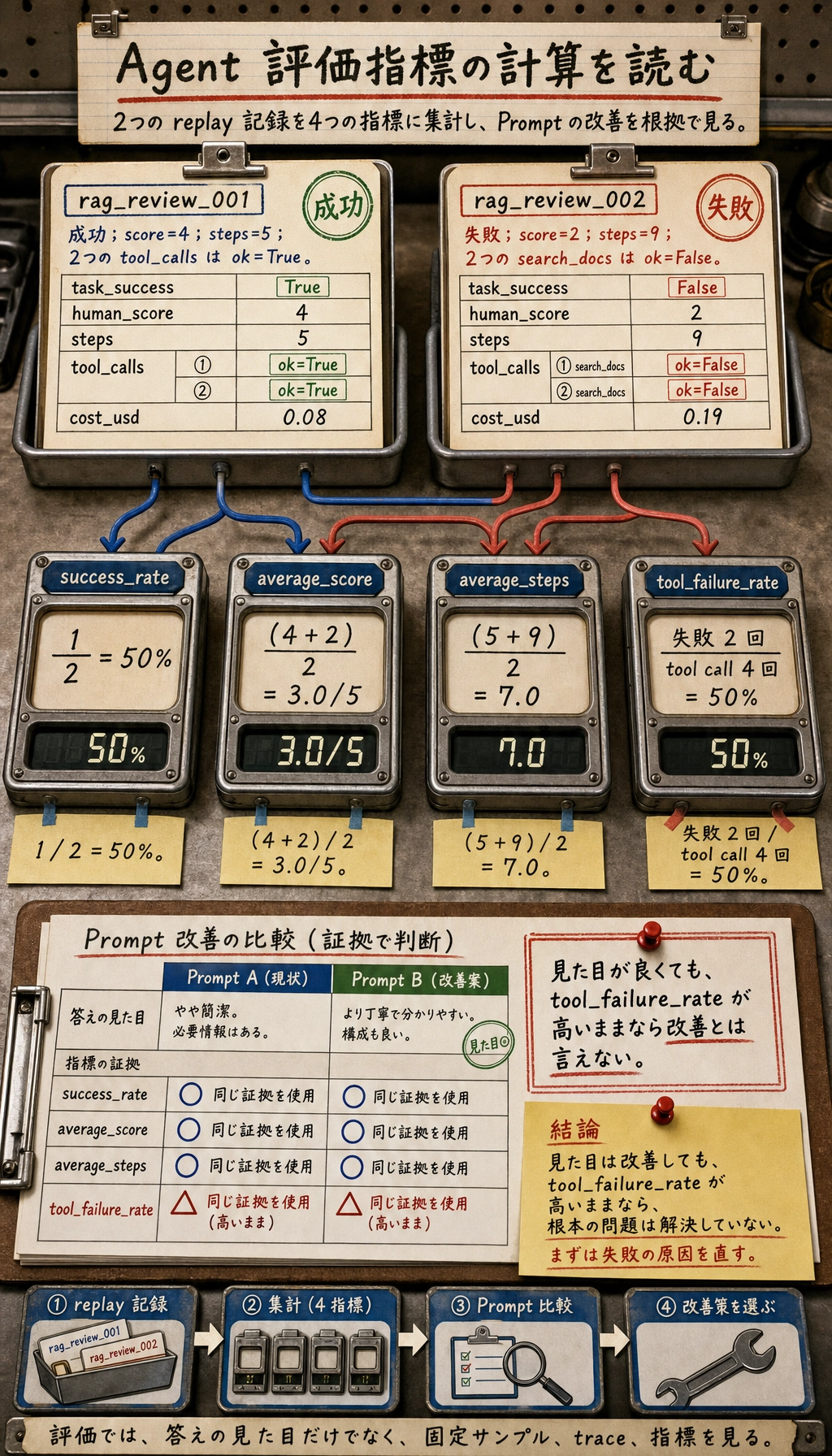
これだけでも、実務上かなり重要な問いに答えられます。
新しい Prompt は本当に Agent を改善したのか、それとも回答の見た目をよくしただけなのか?
評価結果を使ってシステムを改善する
Section titled “評価結果を使ってシステムを改善する”評価の目的は点数をつけることではなく、改善につなげることです。ツール選択ミスが多いなら、まずツール説明とルーティング戦略を見直します。計画がよく不完全になるなら、まず Planning Prompt や状態表現を改善します。コストが高すぎるなら、ループ呼び出しやコンテキストが長すぎないか確認します。安全上の問題が多いなら、権限、確認、拒否の戦略を追加します。
期待される結果:固定評価セット、スコアカード、trace、失敗理由をそろえ、Prompt や tool 設計の変更が実際に改善だったかを説明できる状態です。
このページを終えたら、この証拠カードを残します。
- 評価ケース
- 固定タスクと期待される安全な挙動
- スコアカード
- タスク成功、ツールの正確さ、trace の品質、安全性
- ガードレール
- ポリシー、権限、検証、または人の確認
- 失敗確認
- 危険なツール使用、プロンプトインジェクション、隠れた状態、または観測されていない操作
- 次の行動
- ケース、ガードレール、ログ、ロールバック、または拒否パスを追加する
よくある誤解
Section titled “よくある誤解”1つ目の誤解は、成功例だけを測ることです。2つ目の誤解は、最終回答だけを見て実行軌跡を見ないことです。3つ目の誤解は、固定された評価セットがなく、毎回なんとなく判断してしまうことです。4つ目の誤解は、モデル評価とシステム評価を混同し、ツール、状態、権限、コストを見落とすことです。
- 「学習計画 Agent」のために 10 件の評価タスクを設計する。
- 各タスクに allowed_tools、forbidden_actions、success_criteria を書く。
- 1〜5 点の採点表で Agent の出力を 1 回評価する。
- 評価結果をもとに、3 つのシステム改善案を書く。
この節を学び終えたら、最小限の Agent 評価セットを設計でき、結果層・プロセス層・ツール層・安全層の指標を区別でき、さらに評価で見つけた課題を Prompt、ツール、フロー、権限設計の改善につなげられるようになっているはずです。
解法と解説
- 有用な 10 件の評価 task には、通常の計画、曖昧な goal、不足した前提、実現不能な schedule、tool 使用が必要な case、unsafe request、少なくとも 1 つの「Agent が確認質問すべき」case を入れます。
- 各 task の
allowed_toolsには使ってよい tool、forbidden_actionsにはしてはいけない行動、success_criteriaには別の人でも一貫して採点できる観測可能な条件を書きます。 - 1-5 の rubric を使うときは、final answer と trace を分けて採点します。見た目がよい plan でも tool use が間違っていれば高得点にしません。
- 改善案は観測された failure に対応させます。goal が曖昧なら prompt、tool 選択ミスなら tool description や routing、不安全な行動なら permission や confirmation を直します。