7.3.4 主流な大規模モデルアーキテクチャのバリエーション
- エンコーダーのみ、デコーダーのみ、エンコーダー-デコーダーの基本的な違いを理解する
- アーキテクチャの選択と、学習目標・タスクの関係を理解する
- 実行可能な例を通して、さまざまな mask の背後にある情報の流れを見る
- 「このタスクにはどの構造が向いているか」の最初の判断軸を作る
一、なぜ同じ Transformer なのに、こんなに多くの分岐があるのか?
Section titled “一、なぜ同じ Transformer なのに、こんなに多くの分岐があるのか?”タスクが違えば、情報の流れに関する制約も違うから
Section titled “タスクが違えば、情報の流れに関する制約も違うから”NLP のタスクは、本質的な要求がそれぞれ違います。
- テキスト分類は「文全体を理解する」ことを重視する
- 自由生成は「過去の文脈だけを使って続きを書く」ことを重視する
- 翻訳や要約は「まず入力をエンコードして、それから出力を生成する」ことを重視する
そのため、土台の部品がどれも Transformer block だとしても、
最終的には違う構造に育っていきます。
わかりやすい例え
Section titled “わかりやすい例え”3つの代表的なアーキテクチャは、3つの読み方だと考えるとわかりやすいです。
- エンコーダーのみ:文章全体を先に通読してから判断する
- デコーダーのみ:書きながら前の文だけを見る。後ろは見ない
- エンコーダー-デコーダー:まず原文をしっかり読んでから、要約や翻訳を書く
このイメージがつかめると、
あとの違いも理解しやすくなります。
二、3つの代表的な構造は、それぞれ何をしているのか?
Section titled “二、3つの代表的な構造は、それぞれ何をしているのか?”エンコーダーのみ:理解に向いていて、自由な続きを書くのは得意ではない
Section titled “エンコーダーのみ:理解に向いていて、自由な続きを書くのは得意ではない”Encoder-only の代表例は次の通りです。
- BERT
特徴は次のとおりです。
- 各位置が左右両方の文脈を見られる
- より完全な意味表現を作りやすい
- 分類、照合、抽出などの理解タスクに向いている
ただし、自由生成には自然には向きません。
学習時に「過去だけを見る」という厳密な制約が入っていないからです。
デコーダーのみ:生成に最も素直なルート
Section titled “デコーダーのみ:生成に最も素直なルート”Decoder-only の代表例は次の通りです。
- GPT
- LLaMA
- Qwen
重要な制約は次の通りです。
- 現在の token は、それより前の token だけを見られる
これは生成タスクと完全に一致します。生成するときも、私たちは一歩ずつ先へ書いていくからです。
長所は次のとおりです。
- 学習目標が統一されている
- 生成の流れが自然
- 大規模な自己回帰モデリングに向いている
エンコーダー-デコーダー:入力と出力の役割を分ける
Section titled “エンコーダー-デコーダー:入力と出力の役割を分ける”Encoder-Decoder の代表例は次の通りです。
- T5
- BART
考え方はこうです。
- エンコーダーが入力を理解する
- デコーダーがその表現をもとに出力を生成する
この構造は特に次のタスクに向いています。
- 翻訳
- 要約
- 言い換え
- 質問応答生成
これらのタスクは本質的に、
- 何かを入力として受け取り
- 別のものを出力する
という形だからです。
MoE:情報の流れを変えるのではなく、「誰が計算するか」を変える
Section titled “MoE:情報の流れを変えるのではなく、「誰が計算するか」を変える”モデルがどんどん大きくなると、
もう一つの重要な分岐が出てきます。
- Mixture of Experts
ここでのポイントは、self-attention の基本ルールを変えることではありません。
代わりに、
毎回すべての大きな FFN を通すのではなく、token ごとに一部の expert ネットワークだけを動かす
という点です。
この仕組みの主な目的は次のとおりです。
- パラメータ規模を大きくしながら、毎回の前向き計算量は抑える
つまり MoE は、「スケールアップのためのバリエーション」と考えるとわかりやすいです。

初学者が飛ばさないほうがよい MoE 用語
Section titled “初学者が飛ばさないほうがよい MoE 用語”| 用語 | やさしい意味 | なぜ重要か |
|---|---|---|
| ルーター | token が使う expert を決めるモジュール | token ごとの計算経路を決める |
| Top-k | スコアが高い k 個の expert だけを選ぶこと | token ごとに動かす expert 数を制御する |
| 負荷分散 | 一部の expert に token が集中しすぎないようにすること | 偏ると一部が過負荷になり、他の expert が使われにくい |
| Expert FFN | expert プール内の前向きネットワーク | MoE は dense FFN 部分を置き換えたり拡張したりすることが多い |
| 活性化計算量 | 1つの token が実際に使うパラメータと計算 | 総パラメータ数とは別の概念 |
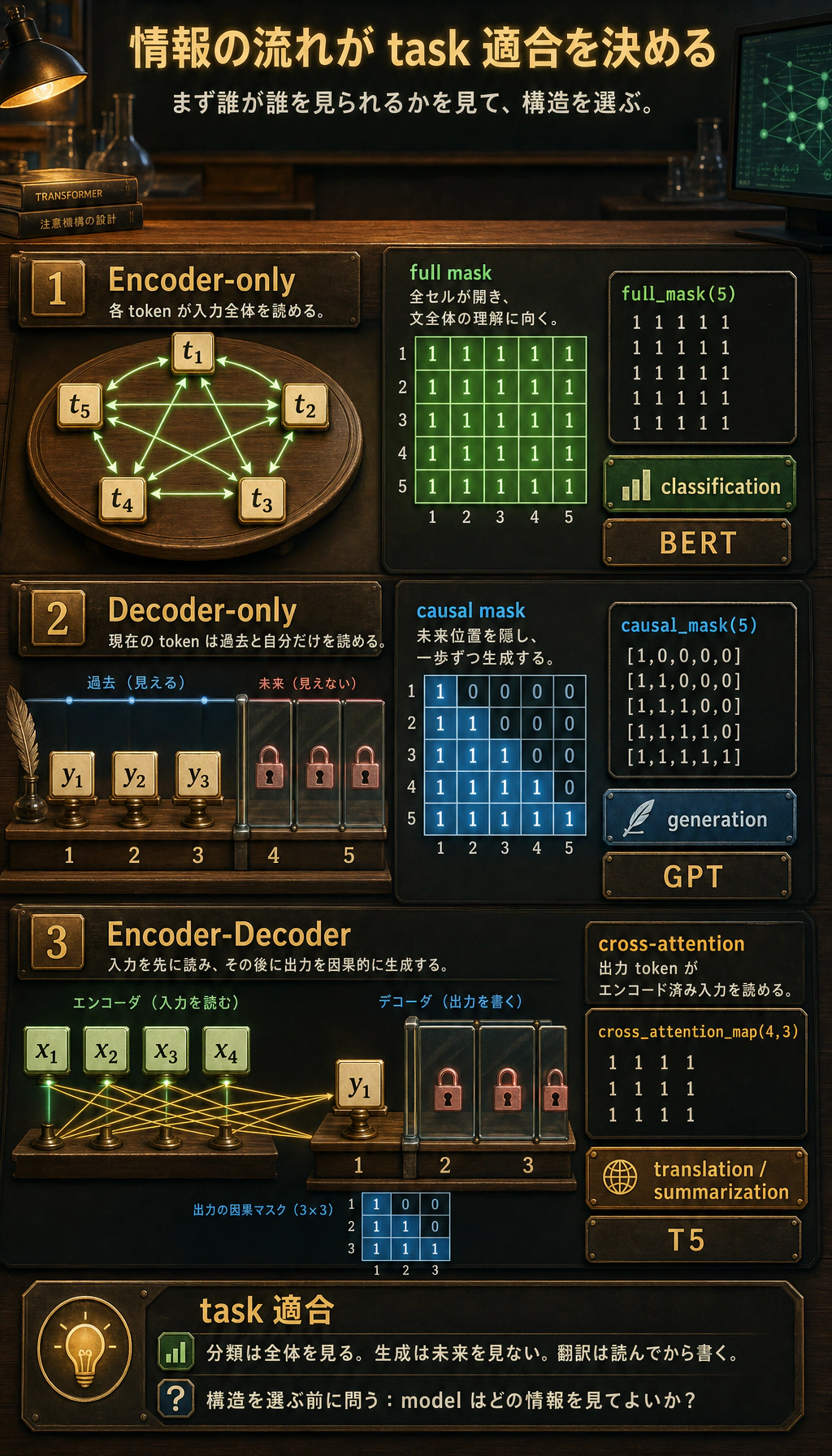
三、まずは本当に意味のある構造差の例を動かしてみよう
Section titled “三、まずは本当に意味のある構造差の例を動かしてみよう”次のコードはモデルを学習するものではありません。
ただし、3つの代表的なアーキテクチャの最も大事な違いを、そのまま表示してくれます。
- どの位置がどの位置を見られるのか
これは、単に辞書を出力するよりも、構造そのものに近い理解になります。
def full_mask(length): return [[1 for _ in range(length)] for _ in range(length)]
def causal_mask(length): return [[1 if j <= i else 0 for j in range(length)] for i in range(length)]
def cross_attention_map(src_length, tgt_length): return [[1 for _ in range(src_length)] for _ in range(tgt_length)]
def pretty_print(title, matrix): print(title) for row in matrix: print(" ".join(str(x) for x in row)) print()
length = 5pretty_print("encoder-only self-attention", full_mask(length))pretty_print("decoder-only self-attention", causal_mask(length))pretty_print("encoder-decoder cross-attention", cross_attention_map(4, 3))期待される出力:
encoder-only self-attention1 1 1 1 11 1 1 1 11 1 1 1 11 1 1 1 11 1 1 1 1
decoder-only self-attention1 0 0 0 01 1 0 0 01 1 1 0 01 1 1 1 01 1 1 1 1
encoder-decoder cross-attention1 1 1 11 1 1 11 1 1 1このコードは何を教えているのか?
Section titled “このコードは何を教えているのか?”ここで教えているのは、最も基本的な3点です。
- エンコーダーのみは双方向に見られる
- デコーダーのみは因果的に見る
- エンコーダー-デコーダーのデコーダーは、入力系列も追加で見られる
つまり、
多くのアーキテクチャの違いは最終的に次の点へたどり着きます。
- 情報の流れの制限が違う
なぜ mask がそんなに重要なのか?
Section titled “なぜ mask がそんなに重要なのか?”mask は、学習中にモデルが何を知ってよいかを決めるからです。
もし decoder に causal mask がなければ、
学習時に未来の token を見てしまいます。
でも実際の生成時には未来は見えません。これでは、学習と推論が一致しません。
なぜこれでタスク適性が決まるのか?
Section titled “なぜこれでタスク適性が決まるのか?”タスクそのものが、情報の流れの違いに対応しているからです。
- 分類:入力全体を見てもよい
- 生成:未来は見られない
- 翻訳:出力側は未来を見られないが、入力側は全体を見られる
構造が合っているかどうかは、本質的には情報の流れの制約がタスクに合っているかどうかです。
四、3つのルートを代表的なタスクにつなげて考える
Section titled “四、3つのルートを代表的なタスクにつなげて考える”テキスト理解タスクでエンコーダーのみがよく使われるのはなぜ?
Section titled “テキスト理解タスクでエンコーダーのみがよく使われるのはなぜ?”この種のタスクでは、次の点が重要だからです。
- 文全体の意味
- token 同士の双方向の関係
- ある位置が前後の文脈をまとめて理解すること
たとえば次のようなタスクです。
- 感情分類
- 意味類似度判定
- 固有表現抽出
これらは「全文を読んでから判断する」イメージに近いです。
なぜ今の大規模モデルは、ほぼデコーダーのみが主流なのか?
Section titled “なぜ今の大規模モデルは、ほぼデコーダーのみが主流なのか?”目的が次のようなものになると、
- 汎用対話
- 自由生成
- コード補完
- 長文の続きを書く
decoder-only 構造が最も扱いやすいからです。
さらに次の利点もあります。
- 事前学習の目標が統一しやすい
- 推論の流れが明確
- 超大規模化しても高い性能が出やすい
その結果、LLM 時代の主流ルートになりました。
エンコーダー-デコーダーが消えていないのはなぜ?
Section titled “エンコーダー-デコーダーが消えていないのはなぜ?”今でもとても向いているタスクがあるからです。
- 翻訳
- 要約
- 文の言い換え
- 入力と出力の差がはっきりした生成タスク
タスクが本質的に「入力を与えて、別の出力を作る」形なら、
encoder-decoder は今でも強いです。
MoE はどんな場面に向いているのか?
Section titled “MoE はどんな場面に向いているのか?”次のような目標を持つときです。
- もっと大きなパラメータ規模にしたい
- でも毎回すべてのパラメータを計算したくない
このとき MoE が注目されます。
ただし、次のような新しい実装上の課題も出てきます。
- ルーティングが安定するか
- 負荷が均等に分かれるか
- 分散学習がより複雑にならないか
五、構造の違いは「どれが強いか」ではなく、「どれが合っているか」
Section titled “五、構造の違いは「どれが強いか」ではなく、「どれが合っているか」”永遠に最強の万能構造は存在しない
Section titled “永遠に最強の万能構造は存在しない”初心者がよく次のように考えます。
- BERT、GPT、T5 のどれが一番強いの?
でも、より適切な問いは次のようなものです。
- タスクは何か?
- 学習目標は何か?
- 推論の仕方は何か?
構造はランキングではありません。
タスクとの相性の問題です。
「性能差」の多くは、構造だけでなく学習規模とデータから来る
Section titled “「性能差」の多くは、構造だけでなく学習規模とデータから来る”たとえば GPT 系が強いのは、decoder-only だからだけではありません。
次の要因も大きいです。
- データ量が多い
- パラメータ数が大きい
- 工学的な成熟度が高い
なので、構造だけを唯一の原因のように考えないことが大切です。
構造と目的関数はセットで考える
Section titled “構造と目的関数はセットで考える”一般的には、次のような組み合わせをよく見ます。
- エンコーダーのみ + masked language modeling
- デコーダーのみ + causal language modeling
- エンコーダー-デコーダー + seq2seq / denoising
つまり、
アーキテクチャと学習目標は、たいてい一体の設計です。適当にバラバラに組み合わせるものではありません。
六、よくある誤解
Section titled “六、よくある誤解”誤解1:BERT は「古いモデル」だから、学ぶ必要はない
Section titled “誤解1:BERT は「古いモデル」だから、学ぶ必要はない”違います。
今でも、理解タスクや表現学習の重要な基準モデルです。
誤解2:デコーダーのみは何でもできるから、必ず最適解
Section titled “誤解2:デコーダーのみは何でもできるから、必ず最適解”たしかに汎用性は高いです。
ただし、入力と出力がはっきり分かれたタスクでは、
encoder-decoder のほうが自然なこともあります。
誤解3:MoE は「ただのもっと大きい普通のモデル」
Section titled “誤解3:MoE は「ただのもっと大きい普通のモデル」”完全には正しくありません。
MoE の本質的な変化は次の点です。
- パラメータ規模と、実際に動く計算量を切り分けている
これにより、学習とデプロイの複雑さが変わります。
このページを終えたら、この証拠カードを残します。
- エンコーダ専用
- 双方向の理解タスク
- デコーダ専用
- 因果生成とチャットモデル
- エンコーダ・デコーダ
- 1 つの系列を読み、別の系列を生成する
- 選択ルール
- アーキテクチャはタスクと提供パターンに従う
- 誤読防止
- 派生名は単純な品質順位ではない
この節で最も大事なのは、名前を覚えることではありません。
構造の地図を頭に作ることです。
エンコーダーのみは「読んで理解する」、デコーダーのみは「時間順に生成する」、エンコーダー-デコーダーは「先に読んでから書く」、MoE は「大規模化するときに計算の通り道を変える」構造です。
アーキテクチャ、タスク、情報の流れの 3 つを結びつけられれば、
これから新しいモデル名を見ても、「流行っているらしい」だけで終わらなくなります。
- 自分の言葉で説明してください:なぜ causal mask はデコーダーのみの核心的な制約なのですか?
- 翻訳または要約のタスクを 1 つ考え、なぜそれが自然にエンコーダー-デコーダーに向いているのか説明してください。
- テキスト分類をするなら、エンコーダーのみとデコーダーのみのどちらをより優先して考えますか?その理由は何ですか?
- もし超大規模モデルの拡張を続けたいが、1 回ごとの計算予算が限られているなら、なぜ MoE が魅力的になるのでしょうか?
解法と解説
- Causal mask は、各 token が未来を見ずに過去だけから予測するよう制限します。この制約があるからこそ、Transformer block は自己回帰生成器として使えます。
- 翻訳や要約には「入力列」と「出力列」が自然にあります。Encoder が入力全体を読み、Decoder がその表現を参照しながら出力を一歩ずつ生成します。
- 典型的な分類なら、Encoder-only を最初に考えることが多いです。入力全体を双方向に読んで、分類用の表現を作りやすいからです。Decoder-only も分類できますが、生成や統一された LLM インターフェースが重要なときに選ばれやすいです。
- MoE は各 token に対して一部の expert だけを有効化します。総パラメータ容量を増やしつつ、毎回すべての expert の計算コストを払わずに済む点が魅力です。