8.3.8 ドキュメント解析と知識抽出
- PDF / Word / PPT をなぜ単なるプレーンテキストだけでは扱えないのかを理解する
- スキャン版 PDF や画像ページでなぜ OCR が必要になるのかを理解する
- 文書を「本文 + 階層 + メタデータ + 根拠ロール」のような構造に分ける方法を学ぶ
- 最小構成の文書解析と知識抽出の流れを理解する
まず全体像をつかもう
Section titled “まず全体像をつかもう”文書解析は、「ファイル -> 構造 -> 知識ブロック」として理解すると分かりやすいです。
flowchart LR A["PDF / DOCX / PPTX"] --> B["テキスト抽出"] B --> C["構造の復元"] C --> D["メタデータ補完"] D --> E["分割と知識抽出"]この節で本当に解決したいのは次のことです。
- なぜナレッジベースプロジェクトは「ファイル内容を抜き出して終わり」ではないのか
- なぜ見出しの階層、ページ番号、セクション、根拠ロールが後の検索品質に影響するのか
なぜ文書解析は思ったより難しいのか?
Section titled “なぜ文書解析は思ったより難しいのか?”理由は、ファイル形式ごとの問題がまったく違うからです。
PDFは「見た目のレイアウト結果」だけを持つことがあり、段落順が自然に安定しているとは限らないDOCXは構造が比較的はっきりしていますが、スタイルや見出し階層が統一されていないことがあるPPTXは断片的な要点が多く、連続した文章のようには扱えない- スキャン版 PDF では、そもそも本文テキストを直接取り出せないことがある
つまり、実用的なナレッジベースでは、まず次のことを確認する必要があります。
- テキストは抽出できたか?
- 順番は正しいか?
- 見出し、ページ番号、章は残っているか?
- どれがポリシー、ケース、チェックリスト、定義、本文、注釈なのか?
初心者向けの分かりやすい比喩
Section titled “初心者向けの分かりやすい比喩”文書解析は、こう考えるとイメージしやすいです。
- 大量の資料を、見返しやすいカードボックスに整理する作業
もし紙を全部そのまま箱からばらまくと、
あとで見つけることはできますが、かなり混乱します。
より安定した方法は、最初に次のように整理することです。
- テーマ
- 章
- 見出し
- 根拠ロール
- 出典
こうしておけば、後でシステムが「このテーマのポリシーとケース根拠を探して」と聞かれたときに、ちゃんと探しやすくなります。
ファイルタイプごとのよくある問題
Section titled “ファイルタイプごとのよくある問題”| ファイルタイプ | よくある問題 |
|---|---|
| 順序が崩れる、ヘッダー・フッターが本文に混ざる、2カラムレイアウトが乱れる | |
| Word | 見出し階層が統一されていない、表と本文が混ざる |
| PPT | 1ページあたりの情報は少ないが断片的で、「ページ」の概念を残す必要がある |
| スキャン版 PDF / 画像ページ | OCR が必要で、誤字や順序ミスが起きやすい |
この表は初心者にとても大事です。
なぜなら、次のことを思い出させてくれるからです。
- 文書処理は「1つのパーサーですべて解決」ではない
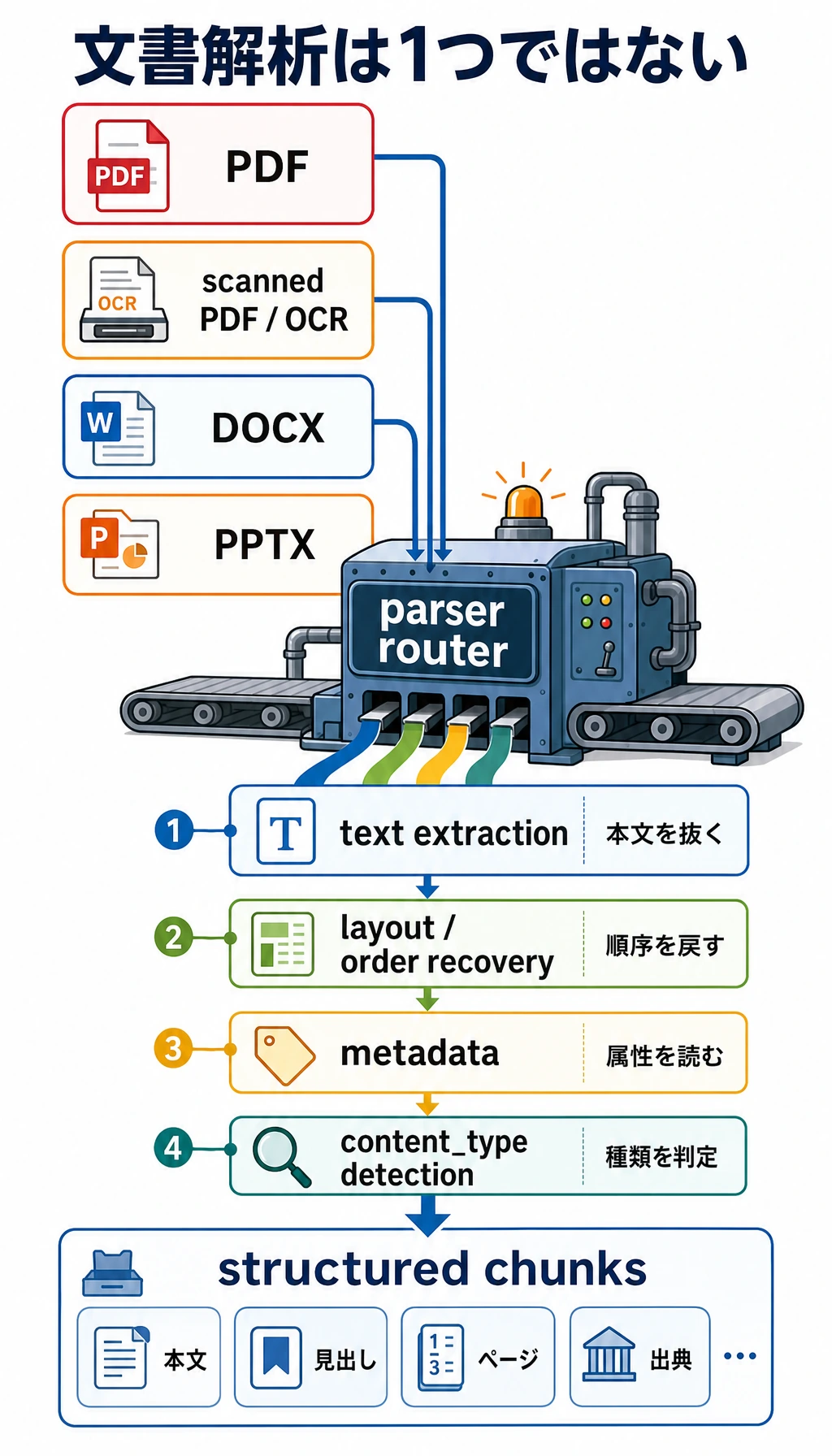
最小構成の文書解析ワークフローの例
Section titled “最小構成の文書解析ワークフローの例”以下の例は、実際のサードパーティライブラリに依存しません。
ただし、「文書タイプごとに解析ルートを分ける」という考え方を先に分かりやすく示します。
from pathlib import Path
def route_parser(filename): suffix = Path(filename).suffix.lower() if suffix == ".pdf": return "pdf_text_or_ocr" if suffix == ".docx": return "word_parser" if suffix == ".pptx": return "ppt_parser" return "unsupported"
files = [ "refund_policy.pdf", "handled_cases.docx", "escalation_checklist.pptx",]
for file in files: print(file, "->", route_parser(file))想定出力:
refund_policy.pdf -> pdf_text_or_ocrhandled_cases.docx -> word_parserescalation_checklist.pptx -> ppt_parserこの例でいちばん大事なのは、
- まず「ルーティング」があると意識すること
つまり、ファイルがシステムに入ったら、いきなり1つの関数に全部入れるのではなく、
まず次を判断します。
- これはどのファイルか
- どの解析パスを通すべきか
実際のシステムに近い知識ブロックはどう見えるか?
Section titled “実際のシステムに近い知識ブロックはどう見えるか?”本当にナレッジベースに入れるべきものは、ただの
- 生テキスト
ではなく、次のような形です。
chunks = [ { "doc_id": "word_001", "source_type": "docx", "section_title": "返金エスカレーションケースの振り返り", "page_or_slide": 3, "content": "配送失敗とアカウント確認の結果、顧客リクエストを返金エスカレーションにした。", "content_type": "case", }, { "doc_id": "ppt_002", "source_type": "pptx", "section_title": "一次サポートチェックリスト", "page_or_slide": 8, "content": "注文状態、返金期間、過去の連絡、承認担当者を確認する。", "content_type": "checklist", },]
for chunk in chunks: print(chunk)想定出力:
{'doc_id': 'word_001', 'source_type': 'docx', 'section_title': '返金エスカレーションケースの振り返り', 'page_or_slide': 3, 'content': '配送失敗とアカウント確認の結果、顧客リクエストを返金エスカレーションにした。', 'content_type': 'case'}{'doc_id': 'ppt_002', 'source_type': 'pptx', 'section_title': '一次サポートチェックリスト', 'page_or_slide': 8, 'content': '注文状態、返金期間、過去の連絡、承認担当者を確認する。', 'content_type': 'checklist'}この例は初心者に特に向いています。なぜなら、
- 本当に価値があるのは「文字だけを取ること」ではない
- 文字を、出典・章・ページ・内容タイプと一緒に戻すことが大事
と分かるからです。
実際のプロジェクトに近い解析結果の スキーマ
Section titled “実際のプロジェクトに近い解析結果の スキーマ”初めてこの種のシステムを作るときに抜けやすいのは、次の3つです。
- 文書レベルのメタデータ
- 章レベルの構造
- 知識ブロックレベルの内容
より安定した方法は、解析結果を次の3層に分けることです。
| 層 | 最低限残すもの |
|---|---|
| 文書層 | doc_id / ファイル名 / ソースタイプ / 作成日時 / 業務ドメイン |
| セクション層 | section_id / タイトル / セクションパス / ページ範囲 |
| 知識ブロック層 | chunk_id / テキスト / 内容タイプ / 元ページ / 根拠ロール |
こう考えると分かりやすいです。
- 文書層は文書の表紙カードのようなもの
- セクション層は目次
- 知識ブロック層は、実際に検索や生成に使うカード
以下の最小構造は、初心者がまず写して作るのに向いています。
parsed_doc = { "doc_id": "sop_pdf_001", "source_type": "pdf", "title": "返金エスカレーション SOP", "domain": "support operations", "sections": [ { "section_id": "s1", "section_title": "返金エスカレーションルール", "page_range": [1, 2], "chunks": [ { "chunk_id": "c1", "content_type": "policy", "page_or_slide": 1, "text": "標準期間を過ぎた返金には主管承認が必要。", }, { "chunk_id": "c2", "content_type": "case", "page_or_slide": 2, "text": "配送失敗とアカウント確認の結果、顧客リクエストを返金エスカレーションにした。", }, ], } ],}
print(parsed_doc["sections"][0]["chunks"][1]["text"])想定出力:
配送失敗とアカウント確認の結果、顧客リクエストを返金エスカレーションにした。この schema の意味は、「見た目をきれいにすること」ではありません。
大事なのは次の点です。
- 後で検索するときに絞り込みできる
- 後で SOP ドラフトを生成するときに、どこがポリシーでどこがケース根拠か分かる
- 後で引用元をたどるときに、どのページから来たか分かる
なぜ「内容タイプ」がとても重要なのか?
Section titled “なぜ「内容タイプ」がとても重要なのか?”あなたのプロジェクトは普通の Q&A ではなく、
次のことをしたいからです。
- テーマ別にポリシー文を探す
- 関連する処理済みケースを探す
- それを決まった形式で Word SOP ドラフトにする
このとき、システムが次の違いを分けられると、かなり安定します。
policycasechecklistdefinition
後で SOP ドラフトを生成するときに、とても扱いやすくなります。
最小の「根拠タイプ分類」例
Section titled “最小の「根拠タイプ分類」例”あなたのプロジェクトでは、1つの文がどのページにあるか分かるだけでは足りません。
できるだけ次の区別も必要です。
- これはポリシールールか
- これは処理済みケースか
- これはチェックリストや定義か
最初から複雑なモデルを使わなくても大丈夫です。
まずは最小のルール版で、全体の流れを作るのがよいです。
def guess_content_type(text): if "ポリシー" in text or "承認" in text: return "policy" if "ケース" in text or "振り返り" in text: return "case" if "チェックリスト" in text or "確認" in text: return "checklist" if "定義" in text: return "definition" return "paragraph"
samples = [ "ポリシー:標準期間を過ぎた返金には主管承認が必要。", "ケース振り返り:配送失敗とアカウント確認の結果、返金エスカレーションにした。", "チェックリスト:注文状態、返金期間、過去の連絡、承認担当者を確認する。",]
for sample in samples: print(guess_content_type(sample), "->", sample)想定出力:
policy -> ポリシー:標準期間を過ぎた返金には主管承認が必要。case -> ケース振り返り:配送失敗とアカウント確認の結果、返金エスカレーションにした。checklist -> チェックリスト:注文状態、返金期間、過去の連絡、承認担当者を確認する。この最小ルール版は完璧ではありませんが、
初心者にとってはとても大事です。
- 「根拠タイプ分類」は魔法ではない
- 本質的には、文書内容の分類をしているだけ
実践:模擬ページを知識ブロックに変換する
Section titled “実践:模擬ページを知識ブロックに変換する”ここでは、ルーティング、章の検出、メタデータ、内容タイプ判定を 1 つの小さなパイプラインにつなぎます。まだ模擬ページのテキストですが、出力の形は embedding 前に保存したい構造にかなり近いです。
def guess_content_type(text): if "ポリシー" in text or "承認" in text: return "policy" if "ケース" in text or "振り返り" in text: return "case" if "チェックリスト" in text or "確認" in text: return "checklist" if "定義" in text: return "definition" return "paragraph"
def build_chunks(doc_id, source_type, pages): chunks = [] section_title = "無題の章"
for page_no, lines in pages: for line in lines: line = line.strip() if not line: continue if line.startswith("#"): section_title = line.lstrip("#").strip() continue
chunks.append({ "chunk_id": f"{doc_id}_c{len(chunks) + 1}", "doc_id": doc_id, "source_type": source_type, "section_title": section_title, "page_or_slide": page_no, "content": line, "content_type": guess_content_type(line), })
return chunks
pages = [ (1, ["# 返金エスカレーションルール", "ポリシー:標準期間を過ぎた返金には主管承認が必要。"]), (2, ["ケース振り返り:配送失敗とアカウント確認の結果、返金エスカレーションにした。"]),]
for chunk in build_chunks("sop_doc_001", "docx", pages): print(chunk)想定出力:
{'chunk_id': 'sop_doc_001_c1', 'doc_id': 'sop_doc_001', 'source_type': 'docx', 'section_title': '返金エスカレーションルール', 'page_or_slide': 1, 'content': 'ポリシー:標準期間を過ぎた返金には主管承認が必要。', 'content_type': 'policy'}{'chunk_id': 'sop_doc_001_c2', 'doc_id': 'sop_doc_001', 'source_type': 'docx', 'section_title': '返金エスカレーションルール', 'page_or_slide': 2, 'content': 'ケース振り返り:配送失敗とアカウント確認の結果、返金エスカレーションにした。', 'content_type': 'case'}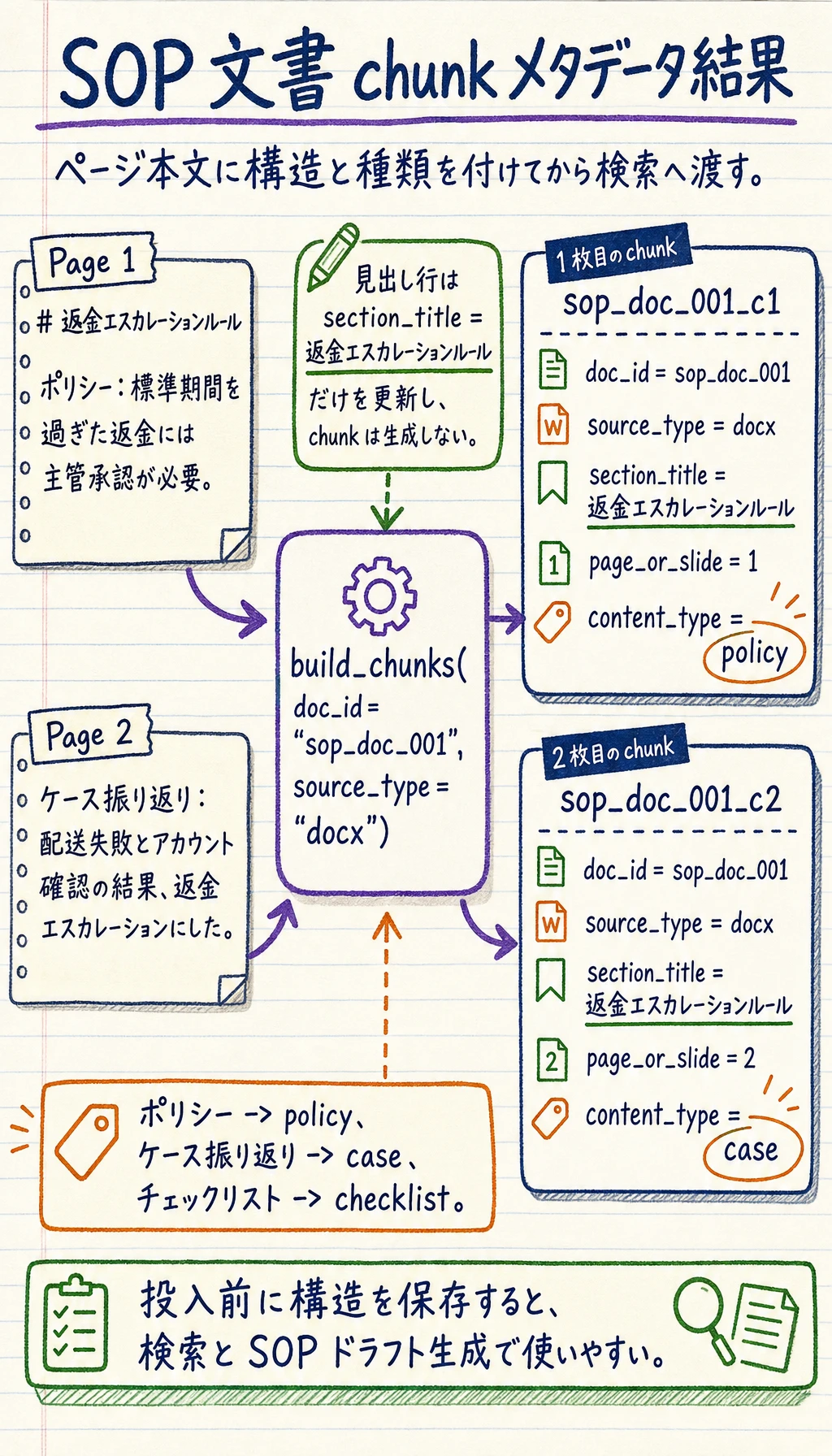
これが最小限に役立つ投入ループです。各 chunk が内容、構造、出典、ページ、タイプを持つようになると、検索と SOP ドラフト生成はかなり作りやすくなります。
操作例と確認ポイント
よい結果では、chunk は 3 個ではなく 2 個になります。見出し行は section_title を 返金エスカレーションルール に更新するだけで、ポリシー行が policy chunk、ケース行が case chunk になります。
ここで大事なのは、chunking は単なる文字列分割ではないという点です。各 chunk には、後で使えるだけのメタデータが必要です。たとえば source type、document id、ページまたはスライド番号、章タイトル、元の内容、粗い内容タイプです。どれかが欠けると検索結果は一見動いても、SOP ドラフト生成時の引用、デバッグ、フィルタリングが難しくなります。
発展として、チェックリスト: 行を含む模擬ページを 1 つ追加してみてください。期待される動きは、content_type: "checklist" を持つ 3 個目の chunk ができ、直前に新しい見出しがなければ同じ section title を引き継ぐことです。
スキャン文書でなぜ OCR が必要になるのか?
Section titled “スキャン文書でなぜ OCR が必要になるのか?”スキャン版 PDF や画像ページは、そもそも文字ファイルではなく、
- 文字が画像のように見えている
からです。
そのため、最初に必要なのは
- OCR で文字認識すること
です。
その後で、次の処理に進みます。
- 構造の復元
- 見出し階層の識別
- 根拠タイプの分類
スキャンされた SOP、チェックリスト、写真資料をたくさん扱うなら、このステップは非常に重要です。
関連する内容は以下も参照してください。
最初に作るときの、いちばん安全な範囲設定
Section titled “最初に作るときの、いちばん安全な範囲設定”初回開発で失敗しやすい理由は、技術が難しすぎるからではなく、
最初にサポート範囲を広げすぎるからです。
より安全な最小版は、たいてい次の順番です。
- まずテキスト型
DOCXのみ対応 - 次にテキスト型
PDFを対応 - 次に
PPTXを対応 - 最後にスキャン文書の OCR を追加
この順番の利点は、
- 先に構造とスキーマを安定させられる
- 最初から OCR の認識問題に足を取られない
ことです。
初心者がそのまま使える解析チェックリスト
Section titled “初心者がそのまま使える解析チェックリスト”初めてナレッジベース用の文書解析を作るとき、
いちばん安定したチェックリストは次のとおりです。
- 文字は漏れなく抽出できているか?
- 見出しと本文の順番は正しいか?
- 章の階層は保たれているか?
- ページ番号 / スライド番号は残っているか?
- 本文、ポリシー、ケース、チェックリストを区別できるか?
- スキャン文書に OCR の誤字はないか?
この6項目は、「先にベクトルデータベースを入れる」ことより優先度が高いです。
これをプロジェクトとして見せるなら、何を見せるべきか?
Section titled “これをプロジェクトとして見せるなら、何を見せるべきか?”見せる価値が高いのは、たいてい次のようなものです。
- 「PDF / Word / PPT に対応しています」という説明だけ
ではなく、次の3点です。
- 元の文書がどんな見た目だったか
- 解析後の構造化知識ブロックがどうなったか
- ポリシー、ケース、チェックリストがどのように識別されたか
- OCR や構造復元でどこが失敗しやすいか
こうすると、見る人に次のことが伝わりやすくなります。
- あなたは知識投入の流れを理解している
- 単に「ファイルを読む」だけではない
このページを終えたら、この証拠カードを残します。
- 要求
- 入力、状態、tools/context、期待される出力の契約
- 検証済み出力
- パーサー/スキーマ、または業務ルール確認の結果
- 追跡記録
- モデル呼び出し、ツール/関数呼び出し、文書解析、または対話状態
- 失敗確認
- フォーマット不正、必須フィールド不足、古い状態、または誤ったツール
- 次の行動
- prompt、schema、state、API、または parsing の改善
- 文書解析の本当の目的は、「ファイルを構造化された知識オブジェクトに変えること」
- スキーマ 設計によって、後の検索・引用・SOP ドラフト生成が安定するかどうかが決まる
- 最初は
DOCX / テキスト PDF / 根拠タイプ分類のルール版を先に動かし、その後で拡張するほうが現実的
この節で一番持ち帰ってほしいこと
Section titled “この節で一番持ち帰ってほしいこと”- 文書解析は文字を抜き出して終わりではなく、構造と出典を復元する必要がある
- 本当に価値のある知識ブロックには、見出し、ページ番号、内容タイプなどのメタデータを付けるべき
- あなたのナレッジベースが大量の PDF / Word / PPT / スキャン文書から来るなら、この工程は全体の流れの中でも特に重要な入口の1つです