13.3 モデルと Runtime の決定
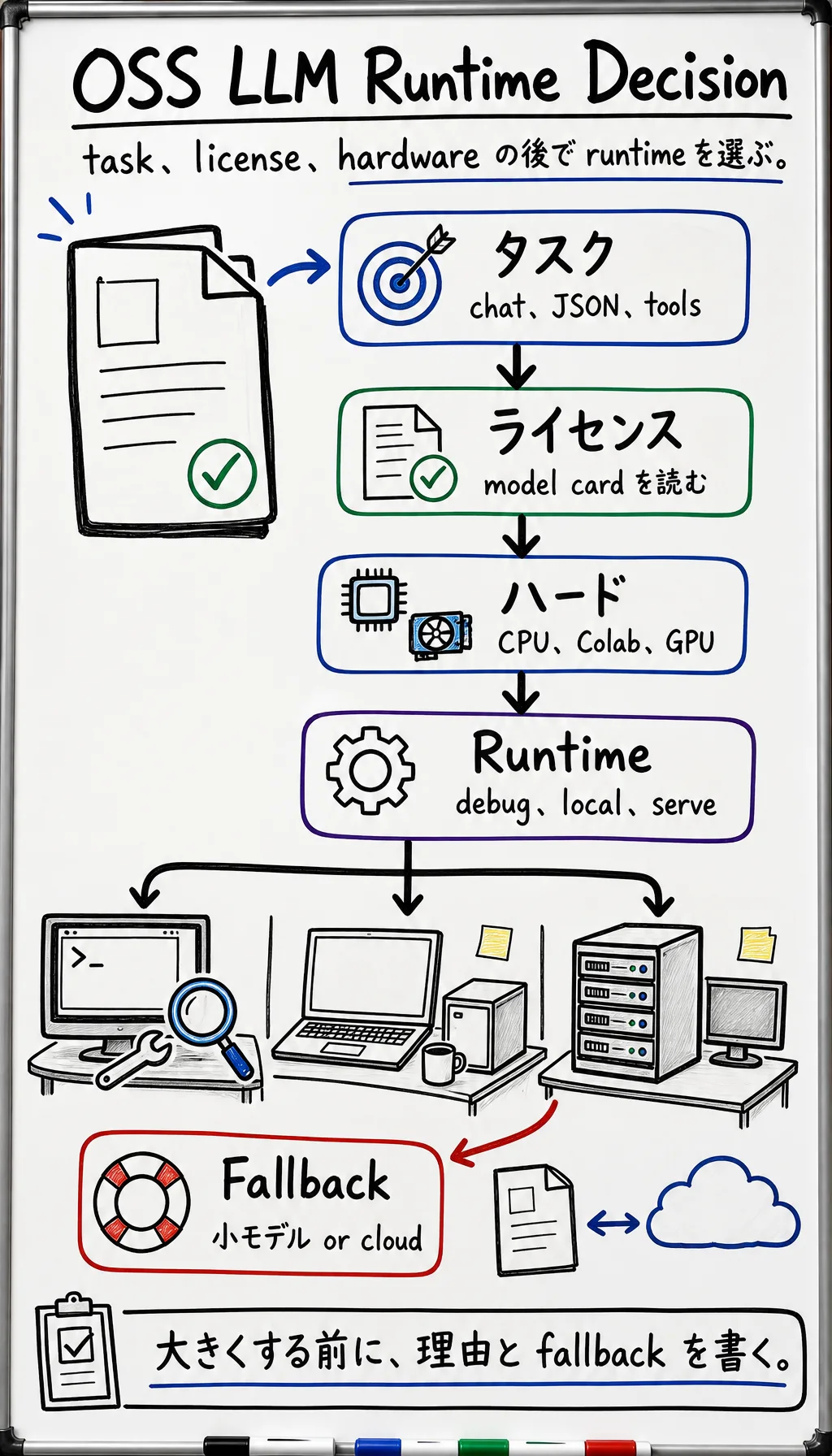
よいオープンソース LLM プロジェクトは、最初の download より前に始まります。このレッスンでは、model selection を書面の decision に変え、hardware、license、latency target、product boundary に合わない model へ時間を使いすぎないようにします。
このページで解くこと
Section titled “このページで解くこと”初学者はよく「どのモデルが一番よいか?」と聞きます。engineering question はもっと具体的です。「この project、この hardware、この license constraint、この rollback path に対して、どの model/runtime pair で十分か?」です。
まず project behavior を証明できる最小の model と最も単純な runtime を使います。quality、context length、throughput、privacy、cost の証拠が必要性を示したときだけ上に進みます。
-
タスク適合 project が chat、extraction、code、多言語、long context、tool calling、multimodal behavior のどれを必要とするか決めます。
-
ライセンス適合 model を中心に system を作る前に model card と license を読みます。commercial use、redistribution、data-use restrictions のメモを残します。
-
ハードウェア適合 download 前に VRAM/RAM と disk を見積もります。local で動かないなら、より小さな model、quantization、rented GPU、cloud API fallback を選びます。
-
Runtime 適合 学習には Transformers、local handoff には Ollama/LM Studio、quantized CPU/edge test には llama.cpp、server-style inference には vLLM/SGLang を使います。
-
証拠適合 model version、command、first output、evaluation table、stop procedure がそろうまで、decision は完了ではありません。
モデル判断表
Section titled “モデル判断表”model_runtime_decision.md を作ります。
# Model Runtime Decision
project_goal: support-operations SOP assistantmust_have: private document handling, Chinese/English answers, stable JSON outputnice_to_have: low latency, long context, OpenAI-compatible endpoint
candidate_1: Qwen2.5-0.5B-Instructlicense_note: check model card before deploymentruntime: vLLM when GPU is available, Transformers for first local testhardware_note: small enough for first experiment; still validate memoryrisk: quality may be too weak for complex SOP reasoning
candidate_2: 7B instruct modellicense_note: check commercial and redistribution termsruntime: vLLM or SGLang on rented GPUhardware_note: requires planned GPU budget and shutdown proofrisk: higher cost and slower iteration
fallback: cloud model API or RAG with current API modelwhy_now: prove the deployment loop before chasing larger modelsrejected_for_now: full fine-tuning, because eval failures are not proven yet具体的な model name は変わります。しかし decision shape は変えません。
Runtime の選択ルール
Section titled “Runtime の選択ルール”token、prompt、Python behavior を確認したいときは Transformers から始めます。 debug しやすく model API に近い一方、通常は最終的な high-throughput server ではありません。
laptop demo や非エンジニアへの handoff が目的なら Ollama または LM Studio を使います。 setup friction は下がりますが、production control は一部失います。
CPU、quantized、edge constraints が重要なら llama.cpp を使います。 小さな local experiment には強いですが、明確な API と evaluation story は必要です。
OpenAI-compatible serving と throughput が必要なら vLLM を使います。 GPU、driver、memory、security posture が明確になるまではここから始めません。
structured generation や agentic serving pattern が必要なら SGLang を使います。 強力ですが、新しさではなく project requirements で正当化します。
ルート別 Runtime カード
Section titled “ルート別 Runtime カード”このカードで 3 つの compute route を混同しないようにします。route が変わると、最初に証明できる claim も変わるため、model、runtime、evidence、upgrade signal を分けて確認します。
Local CPU
- 最初のモデル
sshleifer/tiny-gpt2または小さな quantized model。- Runtime
- コード確認には Transformers、quantized local test には llama.cpp または Ollama。
- 最初に証明すること
- environment、download、1 prompt、eval script、local API skeleton。
- Upgrade signal
- loop は再現できるが、target task に対して quality が弱い。
Free Colab
- 最初のモデル
- tiny model から始め、GPU が見えた場合だけ small instruct model へ進む。
- Runtime
- Transformers notebook。出力ファイルは local に持ち帰れる形で保存します。
- 最初に証明すること
- notebook が再実行でき、outputs が保存され、GPU は前提ではなく機会であること。
- Upgrade signal
- GPU が見え、fixed eval cases が大きな model を試す理由になる。
Rented GPU
- 最初のモデル
- 7B-class の前に small instruct model で始める。
- Runtime
- vLLM または SGLang。まず localhost または SSH tunnel の内側に置きます。
- 最初に証明すること
- VRAM、endpoint、eval table、latency note、shutdown proof。
- Upgrade signal
- fixed eval cases が通り、1 回の生成ではなく service behavior が必要になる。
3 つの route を同じ証明として比較しないでください。Local CPU は workflow、Colab は portable notebook path、rented GPU は controlled serving と cost discipline を証明します。
実行できる Decision Helper を書く
Section titled “実行できる Decision Helper を書く”choose_openllm_runtime.py を作成します。model は download しません。task、privacy、route、available memory に基づいて決定する癖を作ります。
import jsonimport osfrom pathlib import Path
profile = { "task": os.environ.get("TASK", "course assistant"), "route": os.environ.get("ROUTE", "local_cpu"), "privacy": os.environ.get("PRIVACY", "private_docs"), "available_vram_gb": float(os.environ.get("VRAM_GB", "0")), "needs_service": os.environ.get("NEEDS_SERVICE", "no") == "yes",}
def choose(profile): route = profile["route"] vram = profile["available_vram_gb"]
if route == "local_cpu": return { "model": "sshleifer/tiny-gpt2 or a small quantized model", "runtime": "Transformers for code inspection; llama.cpp/Ollama for quantized local tests", "claim": "proves the workflow, not model quality", }
if route == "free_colab": return { "model": "tiny model first; small instruct model only if GPU is visible", "runtime": "Transformers notebook", "claim": "proves a portable notebook run, not stable serving", }
if route == "rented_gpu" and vram >= 16: runtime = "vLLM or SGLang" if profile["needs_service"] else "Transformers first, then vLLM" return { "model": "small instruct model before trying 7B-class", "runtime": runtime, "claim": "proves controlled serving, eval, latency, and shutdown", }
return { "model": "smaller model or cloud API fallback", "runtime": "do not start GPU serving yet", "claim": "current hardware route is not ready", }
decision = {"profile": profile, "decision": choose(profile)}Path("model_runtime_decision.json").write_text(json.dumps(decision, indent=2), encoding="utf-8")print(json.dumps(decision, indent=2))route は 1 つずつ実行します。
ROUTE=local_cpu python choose_openllm_runtime.pyROUTE=free_colab python choose_openllm_runtime.pyROUTE=rented_gpu VRAM_GB=24 NEEDS_SERVICE=yes python choose_openllm_runtime.pyこの出力は final architecture ではありません。route、memory、service need、evidence claim が曖昧なまま model name を選ぶのを防ぐ guardrail です。
第 8 章または第 9 章の project を 1 つ選び、次の decision paragraph を書きます。
この project では、まず _____ を _____ で使います。理由は _____ です。まだ大きな model を使わない理由は _____ です。fixed eval set が _____ を示したときだけ切り替えます。判断の考え方と解説
よい答えは、model size と runtime を evidence に結びつけます。たとえば、小さな instruct model を Transformers または Ollama で動かし、prompt、RAG context、output schema を先に証明します。同じ eval cases で品質が十分で、project が service endpoint を本当に必要としたときだけ vLLM に進みます。prompt、RAG、schema、quantization の後に残る failure が分かる前に、LoRA や大きな GPU を選ばないでください。
- Model Decision
- 選んだ model、license note、size、context length、rejected alternatives
- Runtime Decision
- 選んだ runtime、hardware reason、fallback runtime
- Hardware Note
- local CPU/GPU または rented GPU estimate、disk、expected stop time
- Eval Gate
- model または runtime を変える根拠になる fixed cases
- Expected Output
- model_runtime_decision.md、model_runtime_decision.json、first-run command
現在の model/runtime pair がこの project に十分な理由、upgrade する条件、random model demo を uncontrolled deployment にしないための evidence を説明できれば、このレッスンは合格です。