7.5.6 実践:Prompt 評価ラボ
ここまでで、Prompt の基礎、高度なテクニック、構造化出力、Prompt 実践を学びました。次の段階では、「この Prompt はなんとなく良さそうか」ではなく、よりエンジニアリング寄りの問いに変えます。
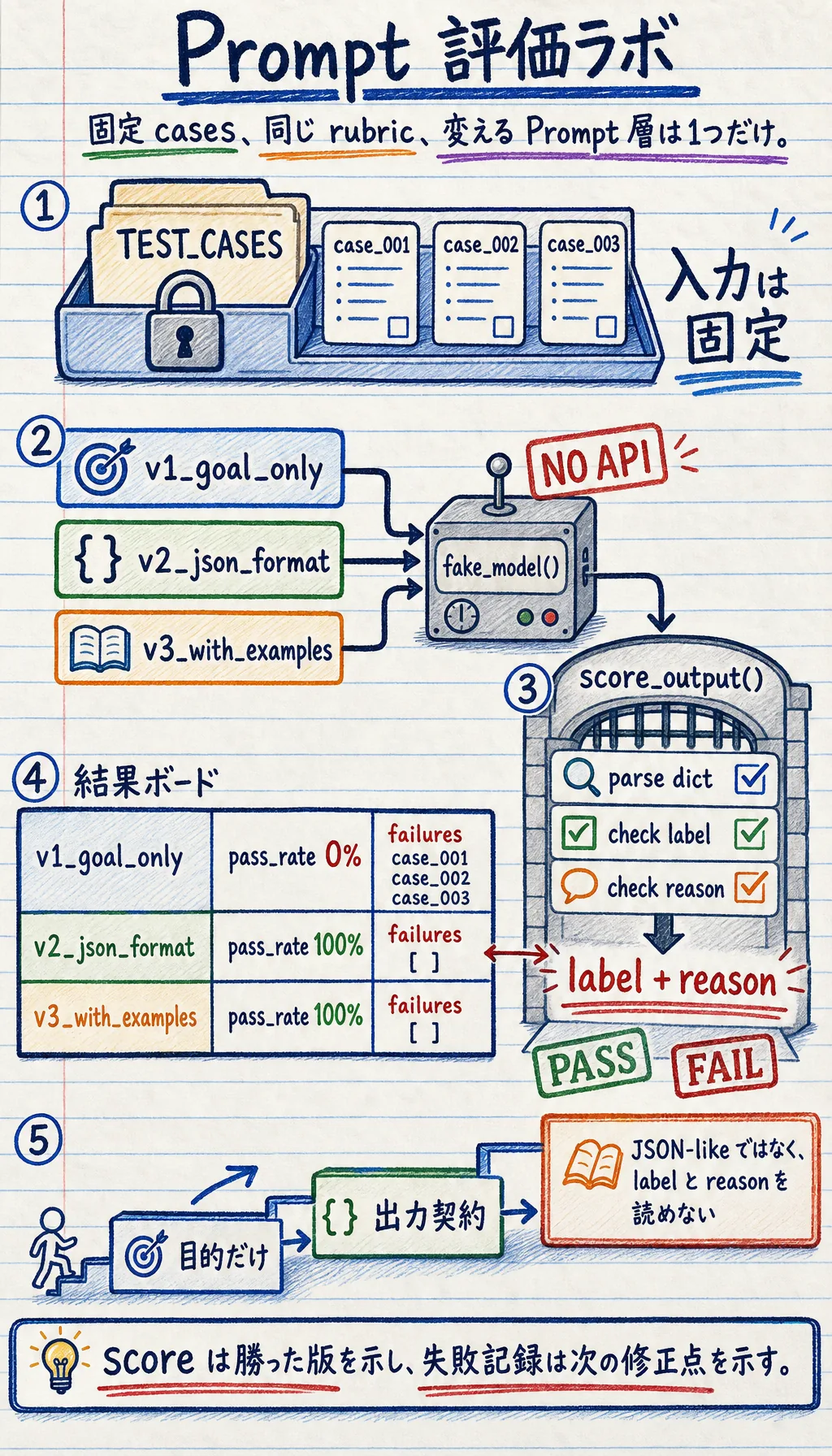
同じ固定テストケースを実行したとき、どの Prompt 版がより安定して合格し、その理由は何か?
このレッスンで補う能力
Section titled “このレッスンで補う能力”前のセクションでは、より明確な Prompt の書き方を学びました。このレッスンでは、それをどう評価するかを学びます。
基本の流れは次の通りです。
- 固定テストケースを用意する。
- 複数の Prompt 版を用意する。
- 同じテストケースをすべての版で実行する。
- 同じ rubric で出力を採点する。
- 失敗例を記録し、次の修正を決める。
これは Prompt 回帰テストの最小実践版です。
先に用語を整理する
Section titled “先に用語を整理する”| 用語 | やさしい説明 | なぜ重要か |
|---|---|---|
| テストケース | 固定入力と期待される振る舞い | たった一つの成功例で Prompt を判断しないため |
| 期待出力 | 良い回答が含むべき内容や条件 | 「良さそう」を確認可能な基準に変える |
| ルーブリック(Rubric) | 採点ルール | Prompt 版どうしを同じ基準で比較する |
| 合格率 | 合格ケース数を総ケース数で割った値 | 版を比較するための単純な指標になる |
| 回帰 | 新しい Prompt が一部を直す一方で、前に通っていたケースを壊すこと | 古いテストケースを残す理由になる |
| 失敗記録 | 何が失敗し、なぜ失敗したかの短い記録 | 失敗を次の改善方向に変える |
完全オフラインの評価ラボを動かす
Section titled “完全オフラインの評価ラボを動かす”次の例は実際のモデルを呼びません。評価ループそのものに集中できるよう、模擬モデルを使います。prompt_eval_lab.py として保存し、実行します。
python prompt_eval_lab.pyTEST_CASES = [ { "id": "case_001", "user_input": "The course is clear and the examples are practical.", "expected_label": "positive", "must_be_json": True, }, { "id": "case_002", "user_input": "The chapter jumps too fast and I feel lost.", "expected_label": "negative", "must_be_json": True, }, { "id": "case_003", "user_input": "The explanation is okay, but the code example does not run.", "expected_label": "negative", "must_be_json": True, },]
PROMPT_VERSIONS = { "v1_goal_only": "Classify the sentiment of the review.", "v2_json_format": ( "Classify the sentiment of the review. " "Return JSON with fields: label, reason." ), "v3_with_examples": ( "Classify the sentiment of the review. " "Return JSON with fields: label, reason. " "Examples: clear and practical -> positive; too fast and lost -> negative." ),}
def fake_model(prompt_version, user_input): text = user_input.lower()
if prompt_version == "v1_goal_only": if "clear" in text or "practical" in text: return "positive" return "negative"
if prompt_version == "v2_json_format": if "clear" in text or "practical" in text: return {"label": "positive", "reason": "The review praises clarity or practicality."} return {"label": "negative", "reason": "The review describes a learning problem."}
if "does not run" in text: return {"label": "negative", "reason": "Broken code blocks learning progress."} if "clear" in text or "practical" in text: return {"label": "positive", "reason": "The review praises useful teaching design."} return {"label": "negative", "reason": "The review describes confusion or frustration."}
def score_output(case, output): format_ok = isinstance(output, dict) and "label" in output and "reason" in output if not format_ok: return { "passed": False, "format_ok": False, "label_ok": False, "reason": "Output is not parseable JSON-like data.", }
label_ok = output["label"] == case["expected_label"] reason_ok = isinstance(output["reason"], str) and len(output["reason"]) >= 10 passed = format_ok and label_ok and reason_ok
return { "passed": passed, "format_ok": format_ok, "label_ok": label_ok, "reason": "ok" if passed else "Label or explanation did not meet the rubric.", }
def run_eval(): report = []
for version in PROMPT_VERSIONS: passed = 0 failures = []
for case in TEST_CASES: output = fake_model(version, case["user_input"]) score = score_output(case, output) passed += int(score["passed"]) if not score["passed"]: failures.append( { "case_id": case["id"], "output": output, "reason": score["reason"], } )
pass_rate = passed / len(TEST_CASES) report.append({"version": version, "pass_rate": pass_rate, "failures": failures})
return report
for row in run_eval(): print("-" * 60) print("version :", row["version"]) print("pass_rate:", f"{row['pass_rate']:.0%}") print("failures :", row["failures"])期待される出力:
------------------------------------------------------------version : v1_goal_onlypass_rate: 0%failures : [{'case_id': 'case_001', 'output': 'positive', 'reason': 'Output is not parseable JSON-like data.'}, {'case_id': 'case_002', 'output': 'negative', 'reason': 'Output is not parseable JSON-like data.'}, {'case_id': 'case_003', 'output': 'negative', 'reason': 'Output is not parseable JSON-like data.'}]------------------------------------------------------------version : v2_json_formatpass_rate: 100%failures : []------------------------------------------------------------version : v3_with_examplespass_rate: 100%failures : []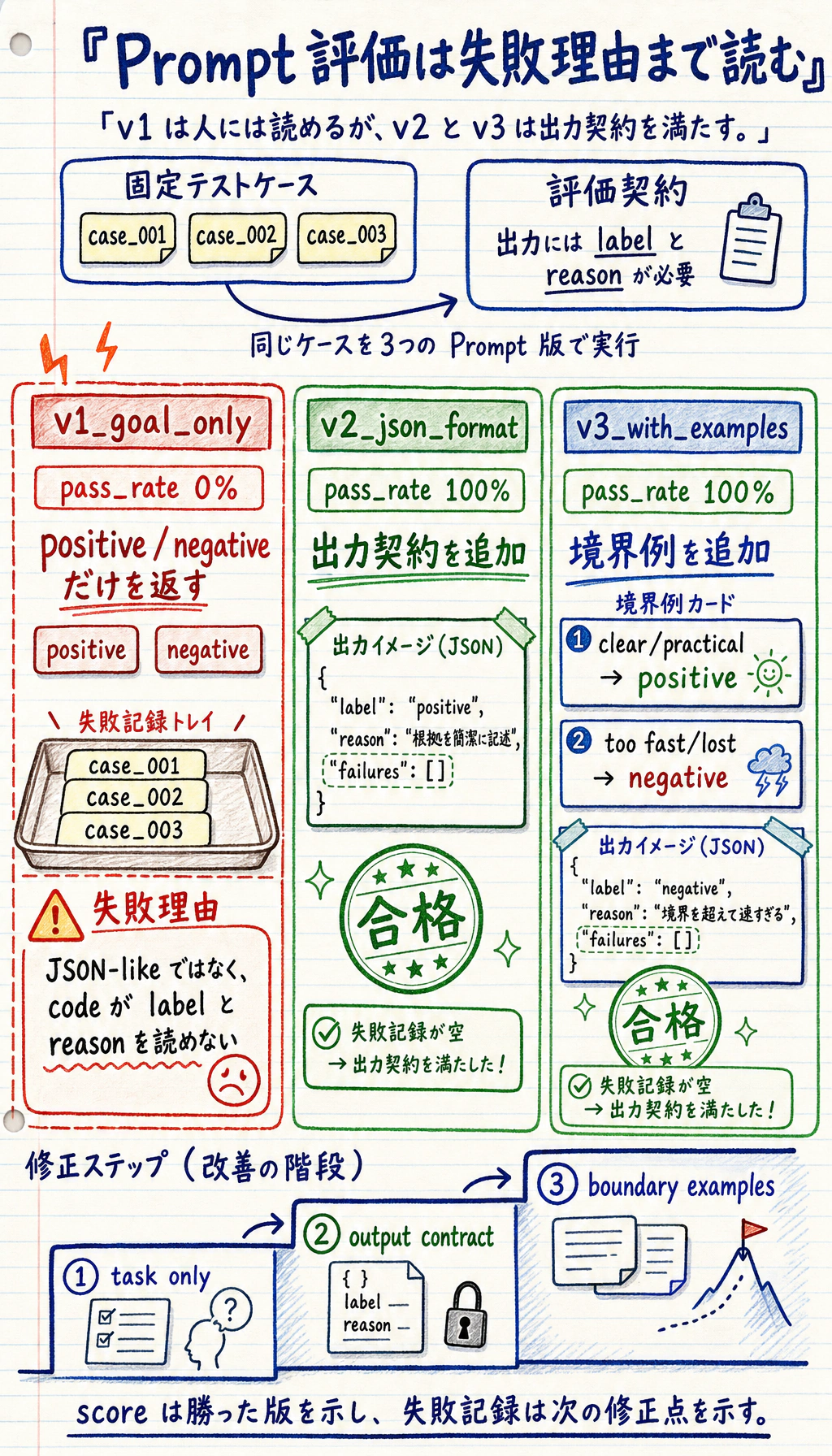
結果の読み方
Section titled “結果の読み方”v1 は分類が合っていても、プロダクト要件を満たさないことがある
Section titled “v1 は分類が合っていても、プロダクト要件を満たさないことがある”v1_goal_only はラベルを返しますが、JSON のように parse できるデータを返しません。下流プログラムが label と reason を必要とするなら、意味として分類が合っていても失敗です。
重要な教訓はこれです。
人間が読める回答と、プログラムが安定して使える回答は同じではありません。
v2 は形式の問題を直す
Section titled “v2 は形式の問題を直す”v2_json_format は出力フィールドを追加しているため、プログラムは label と reason を読めます。これは実際の Prompt デバッグと同じです。まずタスクを明確にし、次に出力契約を明確にします。
v3 は境界ケースに例を加える
Section titled “v3 は境界ケースに例を加える”v3_with_examples は境界が曖昧なタスクで役に立ちます。実プロジェクトでは、bug_report と learning_confusion、または refund_policy と after_sales のように、ラベル差が細かい場合に例が特に有効です。
スコアだけでなく失敗理由も残す
Section titled “スコアだけでなく失敗理由も残す”合格率はどの版が良いかを示しますが、失敗記録は次に何を直すべきかを教えてくれます。
プロジェクト README には、次のような小さな表を残すと便利です。
| Prompt 版 | 失敗タイプ | 証拠 | 次の修正 |
|---|---|---|---|
| v1 | 形式失敗 | 出力がプレーンテキスト | JSON フィールドを要求する |
| v2 | 境界リスク | 混合レビューを誤分類する可能性 | 境界例を 2-3 個追加する |
| v3 | 未検証 | 長文ケースがまだない | 長文とノイズ入力を追加する |
この習慣がないと、Prompt 作業は「なんとなく良くなった気がする」という霧になりがちです。
後で実モデル評価に変えるには
Section titled “後で実モデル評価に変えるには”fake_model() を実際のモデル呼び出しに置き換えるときも、その他の評価ループはできるだけ固定します。
次のものを一度に全部変えないでください。
- モデル
- プロンプト(Prompt)
- テストケース
- 採点ルール
- 出力 スキーマ
変数をまとめて変えると、結果を説明できなくなります。
このページを終えたら、この証拠カードを残します。
- 評価ケース
- 固定入力セット
- プロンプト版数
- ベースラインと改善版のプロンプト
- スコア表
- 合格率またはルーブリックスコア
- 失敗ノート
- 失敗出力1件と原因の可能性
- 次の行動
- より難しいケースを追加するか、実際のモデルにつなげる
- テストケースを 2 つ追加する。1 つは非常に短い入力、もう 1 つは長い混合レビュー入力にする。
confidenceフィールドを追加し、採点関数でも必須にする。v2_json_formatが境界ケースで失敗するようにし、失敗記録を書く。- オフラインループが理解できてから、
fake_model()を自分の LLM 呼び出しに置き換える。 - report 出力をプロジェクトメモに保存し、Prompt 評価の証拠にする。
プロジェクト参考とレビュー観点
- very short input は sparse information で prompt が安定するかを見ます。long mixed-review input は複数 sentiment/topic を分けられるかを見ます。
confidenceを追加したら、schema と scoring function の両方で必須にします。そうしないと model は重要な uncertainty signal を省略できます。- よい failure note は input、prompt version、wrong output、likely cause、next change を含みます。目的は failure を隠すことではなく、学習することです。
- 先に
fake_model()を使うと evaluation loop が deterministic になります。case、scoring、report が安定してから real LLM call を接続します。 - 保存する report には test cases、prompt versions、scores、failed examples、next experiment を含めます。それが prompt evaluation evidence です。
Prompt エンジニアリングは、より良い指示文を書くことだけではありません。より成熟した流れは次の通りです。
テスト集を固定し、一度に Prompt の一層だけ変え、同じ Rubric で出力を採点し、失敗証拠を残す。
これができると、Prompt を感覚で調整しているのではなく、小さく再現可能な Prompt 評価システムを作っていると言えます。