6.4.1 RNN ロードマップ:系列を順番に処理する
RNN は順序のあるデータに向いています。テキスト、時系列、クリック列、センサー値など、前のステップが後のステップに影響する入力です。
まず系列フローを見る
Section titled “まず系列フローを見る”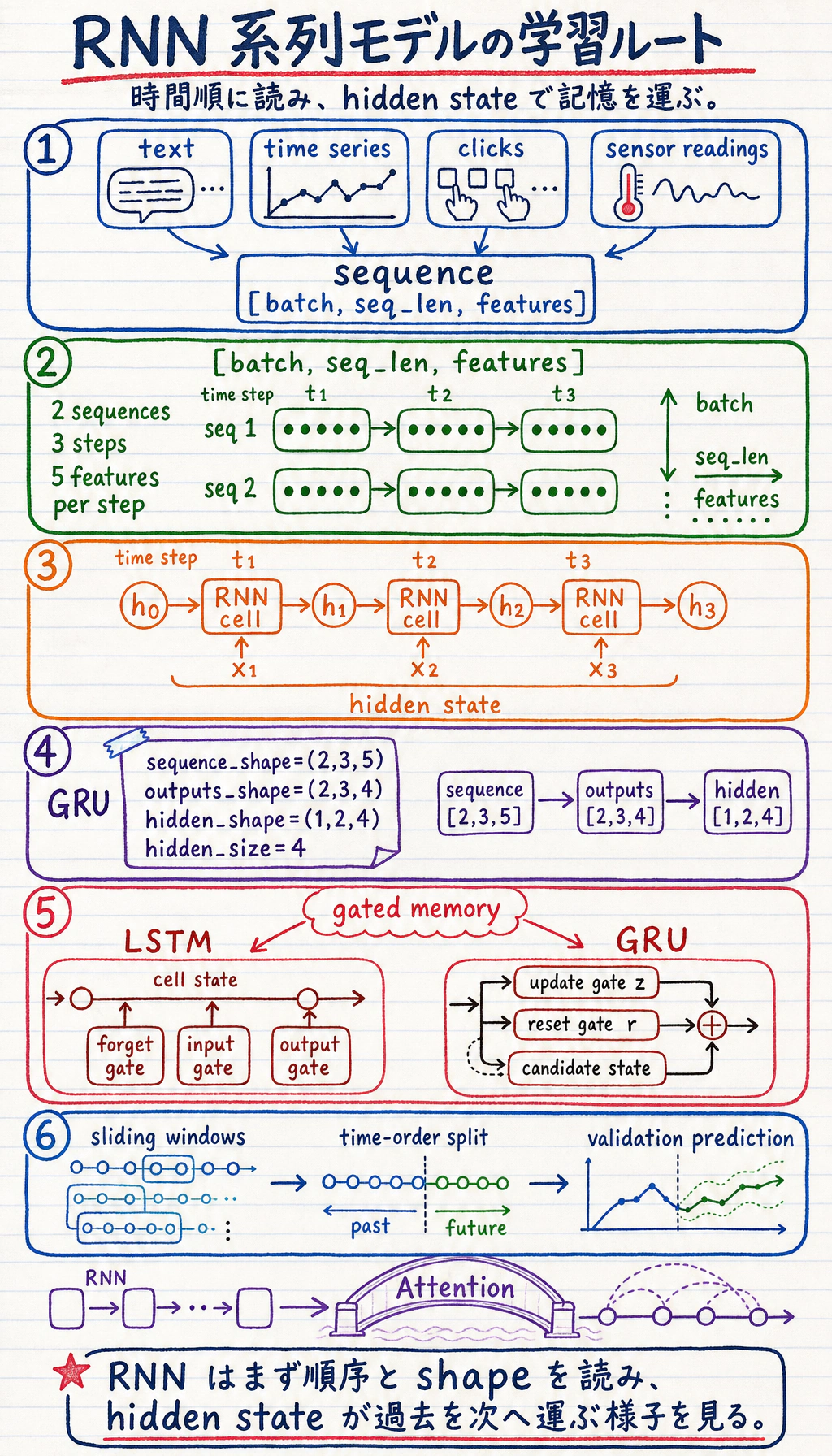
| 概念 | 最初の意味 |
|---|---|
| sequence length | 時間ステップの数 |
| input size | 各ステップの特徴数 |
| hidden state | 流れていく記憶 |
| LSTM / GRU | ゲート付き記憶制御 |
| batch first | [batch, seq_len, features] の形 |
GRU の形を一度確認する
Section titled “GRU の形を一度確認する”rnn_first_loop.py を作り、torch をインストールしてから実行します。
import torch
sequence = torch.randn(2, 3, 5)gru = torch.nn.GRU(input_size=5, hidden_size=4, batch_first=True)outputs, hidden = gru(sequence)
print("sequence_shape:", tuple(sequence.shape))print("outputs_shape:", tuple(outputs.shape))print("hidden_shape:", tuple(hidden.shape))出力:
sequence_shape: (2, 3, 5)outputs_shape: (2, 3, 4)hidden_shape: (1, 2, 4)2つの系列、各3ステップ、各ステップ5特徴と読みます。GRU はサイズ 4 の隠れ表現を返します。
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | 練習すること |
|---|---|---|
| 1 | 6.4.2 RNN 基礎 | 系列入力、隠れ状態、形 |
| 2 | 6.4.3 LSTM と GRU | ゲート、長期依存、記憶制御 |
| 3 | 6.4.4 系列モデリング実践 | スライディングウィンドウ、train/eval ループ |
この小章を学んだら、次の sequence shape メモを残します。
- 入力形状
- [batch, seq_len, features]
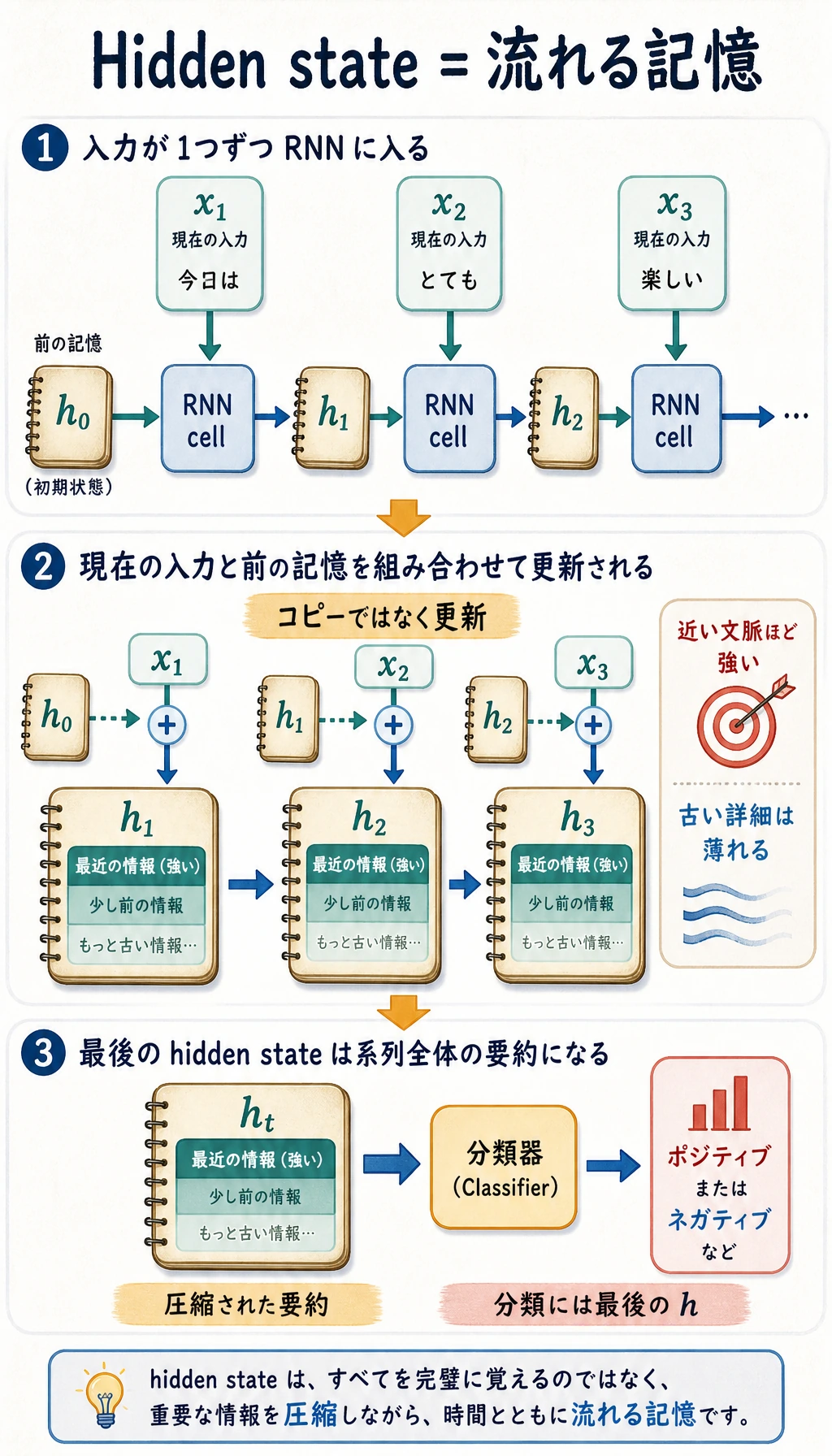
- 隠れ状態
- 正確な保存ではなく、流れる記憶
- RNN 出力
- 各時刻ステップごとに1つの表現
- 最終隠れ状態
- 圧縮された系列要約
- 長文脈の制約
- 通常のRNNが忘れる場合は、LSTM/GRU またはアテンションを使う
[batch, seq_len, features] を読め、hidden state を流れていく記憶として説明でき、LSTM/GRU が長期依存のために導入されたことを説明できれば合格です。
確認の考え方と解説
- 合格レベルの答えでは、tensor、model layer、loss、
backward()、optimizer update を1つの学習ループとしてつなげます。 - 証拠には、動く小さな実験、tensor shape の確認、説明できる loss または validation curve を含めます。
- shape mismatch、loss が下がらない、過学習、data leakage、Attention/Transformer の data flow を説明できない、といった失敗例を1つ言えればよいです。