10.3.1 Object Detection ロードマップ:Class plus Box
Object detection は classification に location を加えます。どの object があり、image のどこにあるかを答えます。
まず box workflow を見る
Section titled “まず box workflow を見る”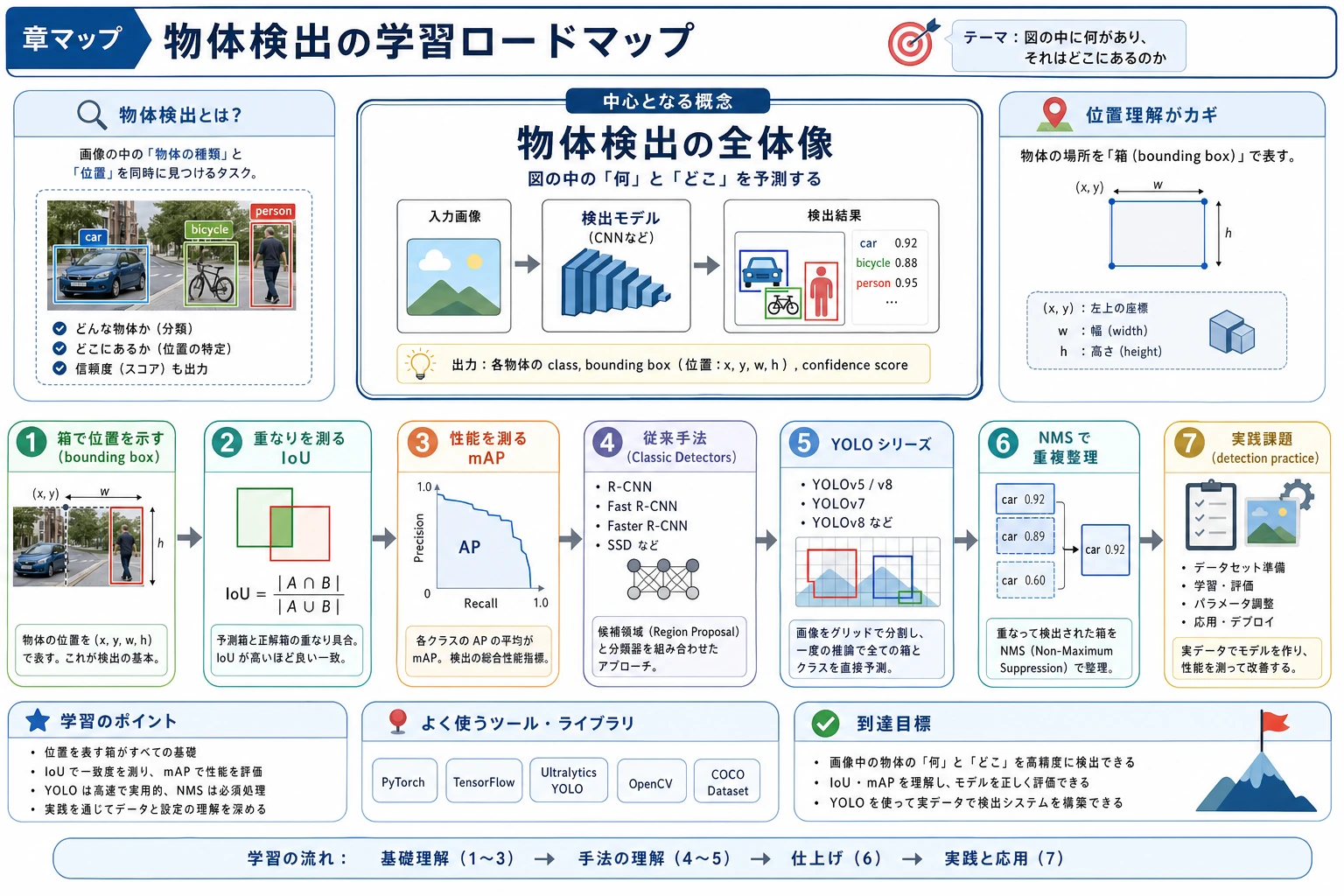

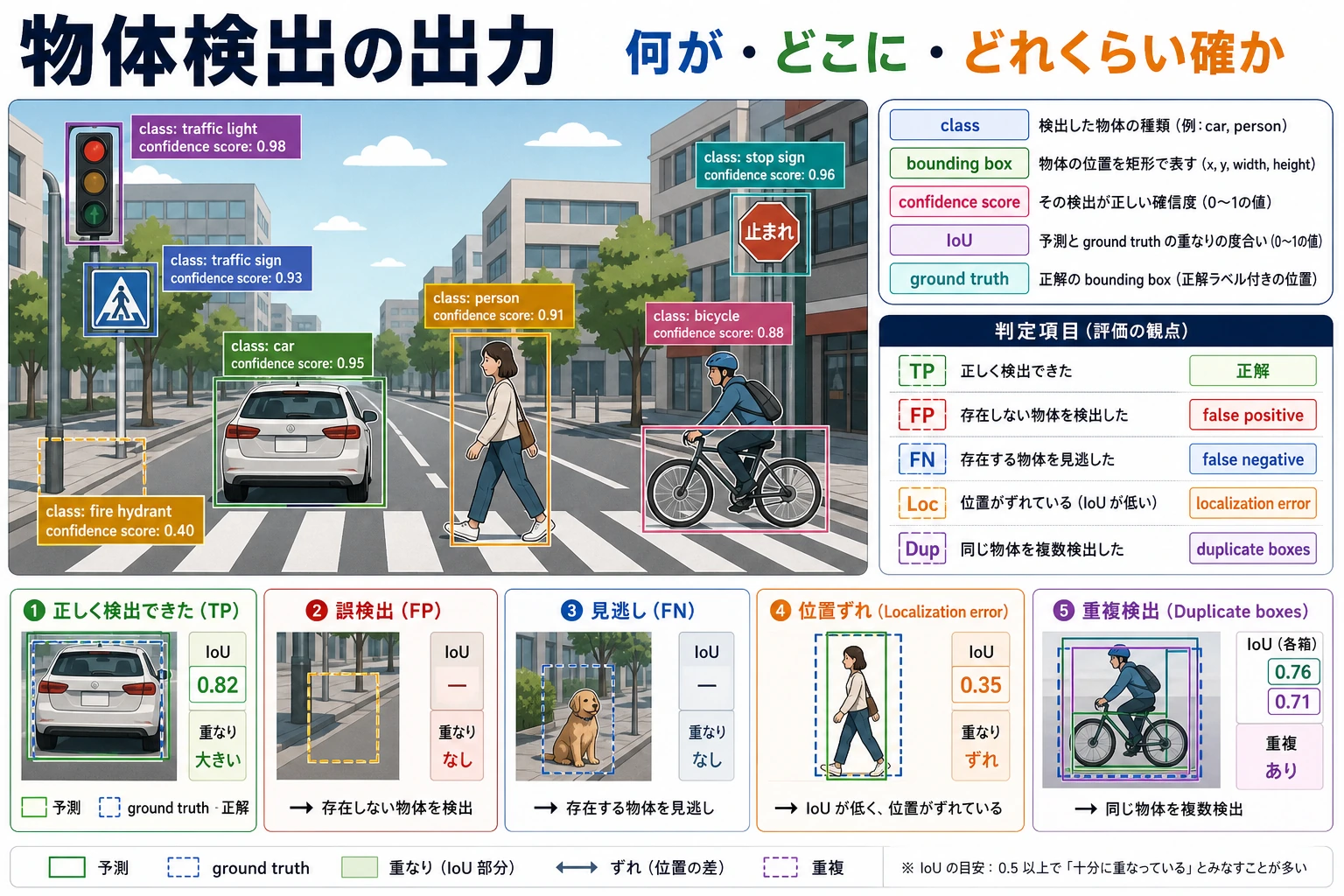
重要概念は bounding box、class、confidence、IoU、threshold、false positive、false negative、mAP です。
IoU check を動かす
Section titled “IoU check を動かす”IoU は predicted box と ground-truth box の重なりを測ります。
truth = (10, 10, 50, 50)pred = (20, 20, 60, 60)
def area(box): x1, y1, x2, y2 = box return max(0, x2 - x1) * max(0, y2 - y1)
ix1 = max(truth[0], pred[0])iy1 = max(truth[1], pred[1])ix2 = min(truth[2], pred[2])iy2 = min(truth[3], pred[3])intersection = area((ix1, iy1, ix2, iy2))union = area(truth) + area(pred) - intersection
print("iou:", round(intersection / union, 3))出力:
iou: 0.391Detection debug は boxes と metrics の表示から始めます。きれいな screenshot 1 枚だけで detection quality を判断しないでください。
この順番で学ぶ
Section titled “この順番で学ぶ”| 手順 | 読む内容 | 実践アウトプット |
|---|---|---|
| 1 | Detection overview | box、class、confidence、IoU、mAP を説明する |
| 2 | Classic detectors | two-stage と one-stage の考え方を比較する |
| 3 | YOLO | grid prediction、threshold、NMS、speed trade-off を理解する |
| 4 | Detection practice | false positives、missed detections、threshold changes を記録する |
boxes、confidence、IoU、少なくとも 1 つの false-positive または false-negative case で detection result を説明できれば、この章は合格です。
確認の考え方と解説
- 合格レベルの答えでは、task を class label、bounding box、mask、OCR text、embedding、video event など正しい視覚出力に対応づけます。
- 証拠には、rendered visual artifact と、metric または定性的な error note を含めます。
- class confusion、missed object、bad mask、lighting shift、domain shift、annotation quality など、失敗モードを1つ説明できればよいです。
このページを終えたら、この evidence card を残します。
- 入力画像
- 正解または期待される対象を含む検出サンプル
- 予測
- バウンディングボックス、ラベル、信頼度スコア、IoU、しきい値設定
- 指標
- precision/recall、mAP、false positives、false negatives
- 失敗確認
- 小さな物体、重なり、NMS、ラベル品質の低さ、または信頼度閾値
- 期待される成果
- 注釈付き画像と、検出メトリクスまたはエラーバケット