10.5.3 動画分析【選択】
- 動画タスクと単一フレーム画像タスクの根本的な違いを理解する
- フレーム抽出、トラッキング、時系列モデリングがそれぞれ何を解決するのかを理解する
- 実行可能な例を通して、動画分析の最小限の直感を身につける
- 多くの動画システムが実は「画像モデル + 時間ロジック」の組み合わせである理由を理解する
一、なぜ動画は単一画像より複雑なのか?
Section titled “一、なぜ動画は単一画像より複雑なのか?”同じ対象が複数フレームにまたがって現れるから
Section titled “同じ対象が複数フレームにまたがって現れるから”1枚の画像では、今の画面にだけ答えれば十分です。 しかし動画では、さらに次を考える必要があります。
- 直前にどこにいたか
- 次にどこへ行くか
「変化」そのものが情報だから
Section titled “「変化」そのものが情報だから”多くの動画タスクでは、本当に重要なのはある1フレームがどう見えるかではなく、 むしろ次の点です。
- 動作がどう起こるか
- 軌跡がどう動くか
たとえで考える
Section titled “たとえで考える”単一画像分析は写真を見るようなものです。 動画分析は監視映像の再生を見るようなもので、自然と次の点が気になります。
- 前後関係
- 事件の流れ
二、動画分析でよく使われる処理方法
Section titled “二、動画分析でよく使われる処理方法”フレーム抽出 + 単一フレームモデル
Section titled “フレーム抽出 + 単一フレームモデル”最もシンプルな方法は次のとおりです。
- 定期的にフレームを抽出する
- 各フレームを個別に分析する
利点:
- シンプル
欠点:
- 時間情報を失いやすい
検出 + トラッキング
Section titled “検出 + トラッキング”次のような場面に向いています。
- 歩行者の軌跡
- 車両の軌跡
核となる考え方は次のとおりです。
- まず各フレームで検出する
- それから時間方向に同じ対象を関連付ける
時系列モデリング
Section titled “時系列モデリング”たとえば次のようなタスクです。
- 動作認識
- 事件認識
この種のタスクは、次の点に強く依存します。
- 複数フレームを合わせて1つのパターンを表現すること
初めて動画分析をするなら、いちばん安全な進め方
Section titled “初めて動画分析をするなら、いちばん安全な進め方”初めて動画タスクに取り組む人は、 つい「最初から時系列ネットワークを使うべきか」と考えがちです。 でも、より安全な順番はたいてい次のとおりです。
- まず単一フレームだけで十分かを確認する
- 単一フレームだけでは足りないなら、フレーム抽出 + 集約を試す
- それでも足りなければ、検出 + トラッキングを行う
- 最後に、本格的な時系列モデリングを使う
この順番はとても価値があります。 なぜなら、実際の動画システムの多くは、最初から大きなモデルを使うのではなく、 まず次の点を整理するからです。
- フレーム抽出の方針
- トラッキングのロジック
- イベントの定義
![]()
三、まずは最小限の軌跡トラッキング例を実行してみよう
Section titled “三、まずは最小限の軌跡トラッキング例を実行してみよう”frames = [ [{"id": None, "x": 10, "y": 10}], [{"id": None, "x": 12, "y": 11}], [{"id": None, "x": 15, "y": 13}],]
def assign_track_ids(frames, max_distance=5): next_id = 1 prev_objects = []
for frame in frames: for obj in frame: matched_id = None for prev in prev_objects: distance = abs(obj["x"] - prev["x"]) + abs(obj["y"] - prev["y"]) if distance <= max_distance: matched_id = prev["id"] break
if matched_id is None: matched_id = next_id next_id += 1
obj["id"] = matched_id
prev_objects = [dict(item) for item in frame]
return frames
tracked = assign_track_ids(frames)for frame in tracked: print(frame)実行結果の例:
[{'id': 1, 'x': 10, 'y': 10}][{'id': 1, 'x': 12, 'y': 11}][{'id': 1, 'x': 15, 'y': 13}]同じ対象が ID 1 のまま保たれています。隣り合うフレーム間の移動が十分小さいからです。移動量が max_distance を超えると、この単純な tracker は誤って新しい ID を割り当てる可能性があります。
この例でいちばん伝えたいことは?
Section titled “この例でいちばん伝えたいことは?”動画分析で多くのシステムが最初にやるのは、複雑な時系列ネットワークではなく、 次のことです。
- フレームをまたいで同じ対象をつなぐ
なぜこれが業務上大事なのか?
Section titled “なぜこれが業務上大事なのか?”同じ対象を別フレームで関連付けられないと、 多くのタスクはそもそも進められません。
- カウント
- 行動分析
- 侵入検知
さらに「スライディングウィンドウで動作を見る」最小例を追加しよう
Section titled “さらに「スライディングウィンドウで動作を見る」最小例を追加しよう”トラッキングは「同じ対象が本当に同じか」を解決します。 しかし多くの動画タスクでは、次のことも気になります。
- 短い時間の中で、実際に何の動作が起きたのか
次の最小例で、まず感覚をつかんでみましょう。
- 動画分析は1フレームだけを見るのではない
- 短い時間ウィンドウを見ることが多い
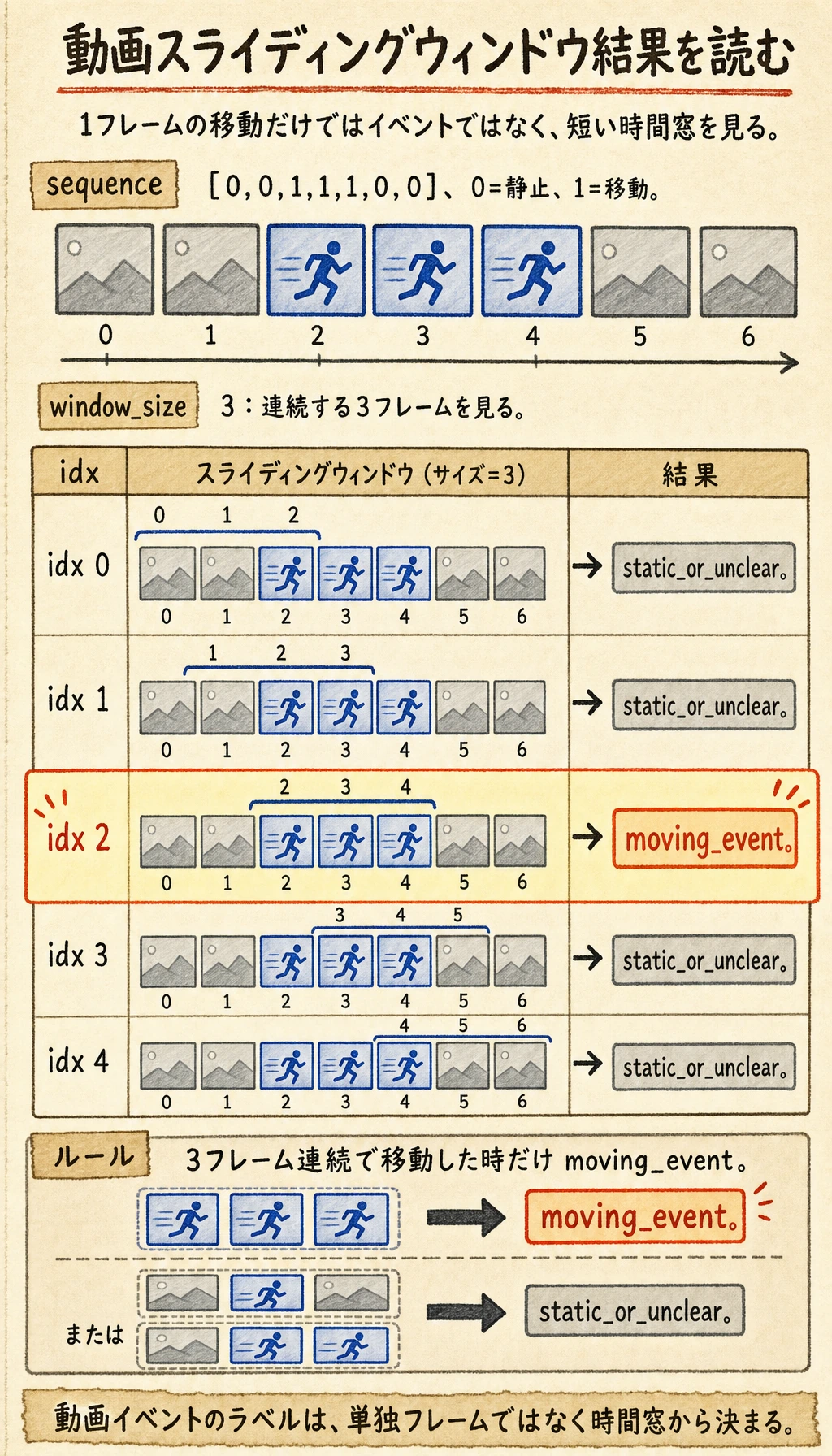
sequence = [0, 0, 1, 1, 1, 0, 0] # 0=静止, 1=移動window_size = 3
windows = []for i in range(len(sequence) - window_size + 1): window = sequence[i:i + window_size] windows.append(window)
for idx, window in enumerate(windows): motion_ratio = sum(window) / len(window) label = "moving_event" if motion_ratio >= 0.67 else "static_or_unclear" print(idx, window, label)実行結果の例:
0 [0, 0, 1] static_or_unclear1 [0, 1, 1] static_or_unclear2 [1, 1, 1] moving_event3 [1, 1, 0] static_or_unclear4 [1, 0, 0] static_or_unclear3フレームすべてが動いている window だけが moving event と判定されます。ここが、単一フレームのラベルと時系列イベントラベルの大きな違いです。
この例でいちばん大事なのは次の点です。
- 動画タスクは、自然に短い時間範囲を見ることが多い
- 1フレームの判定が正しくても、イベント全体の判定が正しいとは限らない
四、モデルを選ぶ前にイベントを定義する
Section titled “四、モデルを選ぶ前にイベントを定義する”動画プロジェクトでは、「イベント」を小さな契約として書けると、モデル選択と評価がかなり明確になります。
| 決めること | 初学者向けの定義 | より深いプロジェクト定義 |
|---|---|---|
| 何を観測するか | 各フレームが移動か静止か | フレーム状態に対象 ID、領域、信頼度、タイムスタンプを含める |
| イベントはいつ始まるか | 3フレーム連続で移動したとき | 開始ルール、終了ルール、最短継続時間、許容する中断を決める |
| システムは何を出すか | moving_event または static_or_unclear | start_time、end_time、track_id、信頼度、根拠フレーム |
| プロダクトは何を許容できるか | ときどき誤判定や遅い通知がある | 誤報コスト、見逃しコスト、最大通知遅延、レビュー手順 |
モデルはシステムの一部にすぎません。プロダクトが信頼できるかどうかは、イベントルールで決まることがよくあります。
window_sizeは、どれだけ過去を見るかを決めます。大きいほど安定しやすい一方、反応は遅くなります。strideは、ウィンドウをどれくらいの頻度で動かすかを決めます。小さいほど遅延は減りますが、計算量は増えます。thresholdは、イベント判定をどれだけ厳しくするかを決めます。高いほど誤報は減りますが、短い動作を見逃しやすくなります。- 平滑化やヒステリシスを使うと、信号が不安定なときにラベルが頻繁に切り替わる問題を減らせます。
経験者にとって大事な習慣は、イベント定義をモデルコードから分けておくことです。そうすれば、同じ検出結果を使いながら、ウィンドウサイズ、しきい値、遅延予算を何度も試せます。
五、単一フレーム精度だけでなく、時間方向の振る舞いを評価する
Section titled “五、単一フレーム精度だけでなく、時間方向の振る舞いを評価する”単一フレーム精度が答えるのは、「このフレームは正しく認識できたか」です。動画システムではさらに、「正しい対象に対して、正しい時刻にイベントを認識できたか。ラベルが不安定に揺れていないか」を見る必要があります。
| 症状 | 何を見るか | よくある修正 |
|---|---|---|
| ID が切り替わる | 遮蔽や交差の近くの track ID 時系列 | 関連付け距離を調整する、外観特徴を足す、より強い tracker を使う |
| ラベルが揺れる | イベント境界の前後のフレームラベル | 平滑化、ヒステリシス、より厳しいウィンドウルールを加える |
| 短いイベントを見逃す | フレーム抽出間隔と最短イベント時間の関係 | より密に抽出する、ウィンドウを短くする、速いトリガー経路を足す |
| 通知が遅い | 真の開始時刻と予測開始時刻の差 | stride を小さくする、バッファを減らす、軽いモデルを使う |
| 1フレームのノイズで誤検知する | ウィンドウ内の生のフレーム状態 | 1フレームの強い信号ではなく、連続した根拠を要求する |
動画プロジェクトを説明するときは、イベント precision/recall、開始時刻誤差、終了時刻誤差、ID 切り替わり回数、通知遅延など、少なくとも1つの時間方向の指標を入れましょう。これが、単なるデモと実際の動画システムを分けます。
六、つまずきやすいポイント
Section titled “六、つまずきやすいポイント”動画を独立した画像の集合として扱ってしまう
Section titled “動画を独立した画像の集合として扱ってしまう”こうすると、次の情報を失いやすくなります。
- 軌跡
- 動作
- イベントの順序
フレーム抽出が粗すぎる
Section titled “フレーム抽出が粗すぎる”フレームを取り出す間隔が広すぎると、重要な瞬間を見逃すことがあります。簡単な確認方法は、フレーム抽出間隔と、検出したい最短イベント時間を比べることです。イベントが 0.4 秒しか続かないのに 1 秒に1回しか抽出しないなら、モデルが正確でもイベントを見られない可能性があります。
単一フレームの精度だけを見て、時系列の安定性を見ない
Section titled “単一フレームの精度だけを見て、時系列の安定性を見ない”実際の動画システムでは、むしろ次の点が重要です。
- ふらつき
- トラッキング漏れ
- ID の切り替わり
- イベント開始と終了の誤差
- 通知遅延
七、動画分析をプロジェクトにするなら、何を見せるべきか
Section titled “七、動画分析をプロジェクトにするなら、何を見せるべきか”この種のテーマを作品集ページにするなら、 いちばん見せる価値が高いのはモデル名の羅列ではなく、 次の6つです。
- フレーム抽出または時系列モデリングの全体フロー図
- 明確なイベント定義表
- 1本の対象軌跡、またはイベントウィンドウの図
- 小さな時間方向の指標表
- 誤報と見逃しを含む、典型的な失敗例のセット
- 最終的に「フレーム抽出 / トラッキング / 時系列モデル」のどの方針を選んだか
こうすると、他の人に次のことが伝わりやすくなります。
- ただ画像をたくさん並べているのではなく、動画システムを作っている
- ということです
このページを終えたら、この evidence card を残します。
- シナリオ境界
- face、video、OCR、3D、medical、または別の vision シナリオ
- 入力サンプル
- ソース画像/フレーム/文書と期待される出力タイプ
- 結果成果物
- 抽出テキスト、追跡イベント、深度の手がかり、診断フラグ、またはレビュー注記
- 失敗確認
- プライバシー、照明、時間的ドリフト、レイアウト、キャリブレーション、またはドメインリスク
- 期待される成果
- 指標または人手レビューのメモを含むシナリオ固有のアーティファクト
この節でいちばん大事なのは、次の判断を持つことです。
動画分析の難しさは「フレーム数が多い」ことだけではなく、時間次元をモデルに入れ、対象やイベントがフレームをまたいでどう連続して起こるかを理解しなければならない点にある。
この節で必ず持ち帰りたいこと
Section titled “この節で必ず持ち帰りたいこと”- 動画タスクで最も重要な新しい次元は、画素ではなく時間
- 多くの動画システムは実は「単一フレームモデル + 時間ロジック」の組み合わせでできている
- 初めて動画プロジェクトを作るときは、複雑なモデルを追う前に、まずタスクの時間要件を整理するほうが価値が高い
- 例を2つの対象が同時に動くように変えて、シンプルなトラッキングロジックが混乱するか確かめてみましょう。
- なぜ多くの動画システムは「単一フレームモデル + 時間ロジック」の組み合わせだと言えるのでしょうか?
- フレーム抽出が粗すぎると、どんなリスクがありますか?
- どのような動画タスクでは、時間を明示的にモデル化する必要があり、単一フレームだけでは不十分かを考えてみましょう。
window_sizeを3から5に変えると、誤報と通知遅延はそれぞれどう変わるでしょうか?- イベントが少なくとも2つのウィンドウにまたがるときだけ発火するルールを追加してみましょう。このルールはどんなノイズを減らし、どんな短いイベントを見逃す可能性がありますか?
参考実装と解説
- 2 つの target が同時に動くと、単純な nearest-neighbor tracking は交差や重なりで identity を入れ替えることがあります。実際の tracking には、より強い appearance と motion logic が必要です。
- 多くの video system は、まず single-frame model を走らせ、その後に smoothing、tracking、duration check、event decision のための temporal logic を足します。
- frame sampling が粗すぎると、短い event を見逃し、track が切れ、alert が遅れ、motion が不連続に見えます。
- action recognition、fall detection、gesture recognition、dwell-time alert、traffic behavior analysis などは、時間を明示的にモデル化する必要があります。
window_sizeを3から5にすると、通常はノイズが平滑化され false alarm は減りますが、alert は遅くなり、短い event を見逃すことがあります。- event が 2 window 続いたときだけ発火するルールは、ちらつきノイズや 1 frame の false positive を減らします。ただし、短い転倒、突然の侵入、短い手信号など、本物の短時間 event を見逃す可能性があります。