5.6.2 プロジェクト1:住宅価格予測(回帰問題)
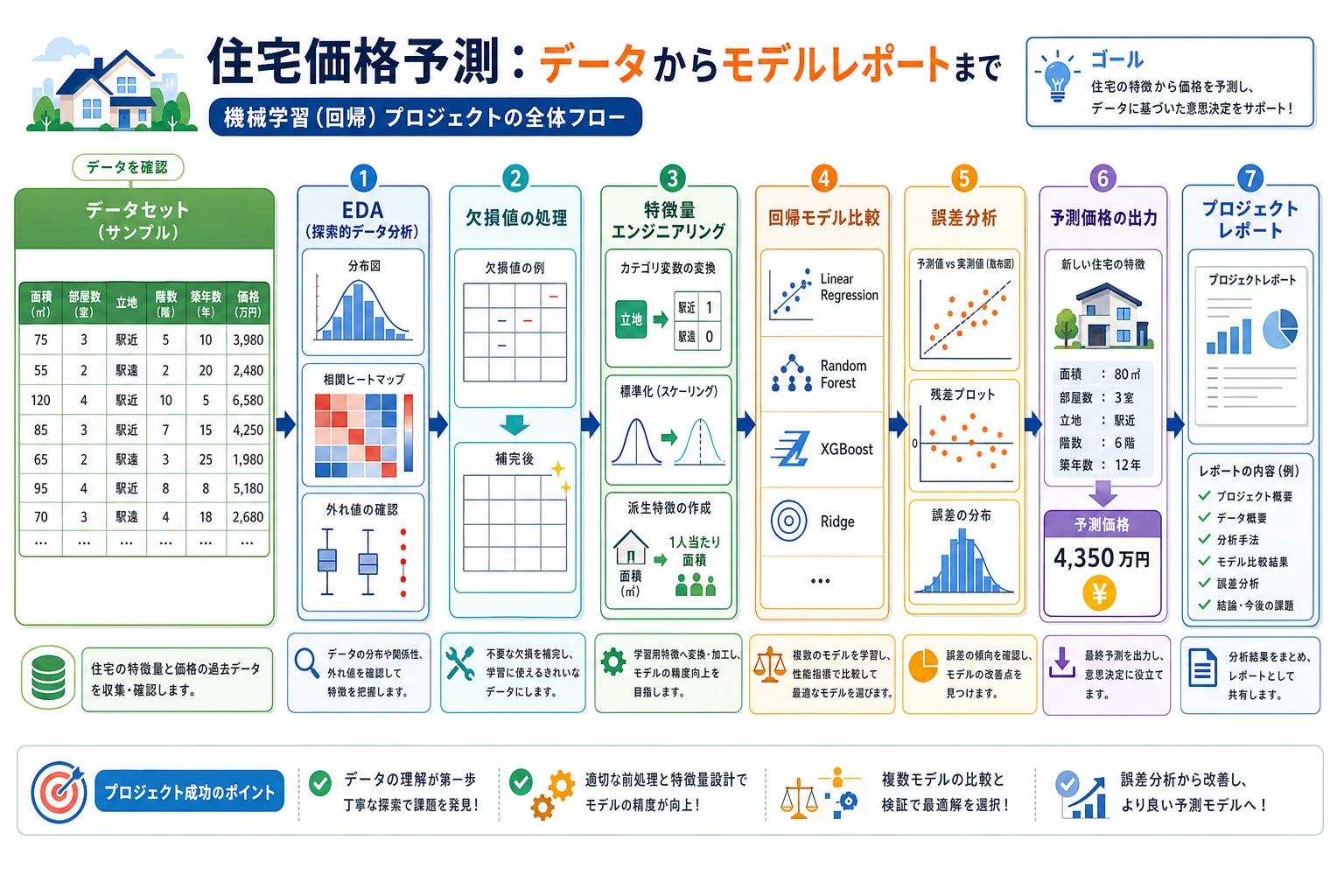
プロジェクト概要
Section titled “プロジェクト概要”| 情報 | 説明 |
|---|---|
| タスクタイプ | 回帰 |
| データセット | California Housing(sklearn 内蔵) |
| 評価指標 | RMSE、R² |
| 関連スキル | EDA、特徴量エンジニアリング、複数モデル比較、チューニング |
コードを読む前に押さえる用語
Section titled “コードを読む前に押さえる用語”- EDA(Exploratory Data Analysis、探索的データ分析):モデルを作る前に、分布、欠損値、外れ値、相関を見ることです。このプロジェクトでは、まずどんな住宅価格分布を予測するのかを理解します。
- RMSE(Root Mean Squared Error、二乗平均平方根誤差):平均的な予測誤差を、目的変数と同じ単位で表します。小さいほどよく、大きな誤差をより強く罰します。
- R²(決定係数):モデルが目的変数のばらつきをどれくらい説明できているかを表します。1 に近いほど良いですが、RMSE と一緒に見る必要があります。
- GBDT(Gradient Boosting Decision Tree、勾配ブースティング決定木):複数の小さな決定木を順番に学習し、後の木が前の木の誤りを補正していくアンサンブル手法です。
まずは全体像をつかもう
Section titled “まずは全体像をつかもう”このプロジェクトは、「回帰プロジェクトって、実際にはどう進めればいいの?」を練習するのにとても向いています。
flowchart LR A["データと目的変数の分布を見る"] --> B["まずは線形回帰の baseline"] B --> C["少しだけ特徴量エンジニアリングをする"] C --> D["木モデル / GBDT と比較する"] D --> E["チューニングする"] E --> F["残差分析と解釈"]
style A fill:#e3f2fd,stroke:#1565c0,color:#333 style F fill:#e8f5e9,stroke:#2e7d32,color:#333初心者向けの全体イメージ
Section titled “初心者向けの全体イメージ”住宅価格予測のプロジェクトは、こんなふうに考えると分かりやすいです。
- たくさんの家をまずざっくり査定してみて、あとから「どこで見積もりを外したか」を確認する
これは実際の業務にもよく似ています。
- ただ数字を出せばよいわけではない
- その数字がなぜだいたい妥当なのかを知りたい
- そして、どんな家で外しやすいのかを知る必要がある
もし最初に回帰プロジェクトをやるなら、この流れで進めるのがいちばん安定です。
このページを終えたら、この evidence card を残します。
- プロジェクト目標
- 予測、セグメンテーション、Kaggle、またはエンドツーエンドの ML ポートフォリオ対象
- パイプライン
- データ分割、前処理、モデル、評価、レポート成果物
- 結果
- metric 表、chart、予測、失敗サンプル、README の注記
- 失敗確認
- 再現不可能な実行、リーク、過学習、弱いベースライン、またはデプロイ境界の不足
- 期待される成果
- パイプライン、メトリクス、失敗レビューを含む ML プロジェクトフォルダ
この問題で本当に練習したいこと
Section titled “この問題で本当に練習したいこと”このプロジェクトで大事なのは、単に「回帰モデルを動かす」ことではありません。次の4つを練習することです。
- データ探索から役立つヒントを見つける
- まずはシンプルな baseline を作る
- 特徴量エンジニアリングとモデル比較で精度を上げる
- 誤差分析で、どこが得意でどこが苦手かを説明する
なぜ最初の完全プロジェクトに向いているのか?
Section titled “なぜ最初の完全プロジェクトに向いているのか?”理由はシンプルで、次のような良さがあるからです。
- タスクが明確で、回帰問題だとすぐ分かる
- 指標が分かりやすく、RMSE と R² を理解しやすい
- baseline を作りやすい
- その後の改善余地もはっきりしている
おすすめの進め方
Section titled “おすすめの進め方”初心者に合った進め方は、だいたい次の順番です。
- まず最小限の線形回帰 baseline を作る
- 基本的な特徴量エンジニアリングをする
- 木モデルや GBDT を試す
- 最後にチューニングをする
最初から複雑なモデルに飛びつくと、問題そのものの感覚をつかみにくくなります。
最初の版でいちばん大事なのは、高得点ではない
Section titled “最初の版でいちばん大事なのは、高得点ではない”この問題で最初の版を作るときに大切なのは、実は次の2つです。
- この問題が回帰としてちゃんと扱えることを確認する
- あとから比較できる baseline を作る
つまり、最初は「シンプルだけど完全」であることのほうが、いきなり「複雑だけど説明しにくい」よりずっと価値があります。
ステップ 1:データの読み込みと探索
Section titled “ステップ 1:データの読み込みと探索”import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.datasets import fetch_california_housing
# データを読み込むdata = fetch_california_housing()df = pd.DataFrame(data.data, columns=data.feature_names)df['MedHouseVal'] = data.target # 住宅価格の中央値(10万ドル単位)
print(f"データ形状: {df.shape}")print(df.describe())
# 目的変数の分布fig, axes = plt.subplots(1, 2, figsize=(12, 4))df['MedHouseVal'].hist(bins=50, ax=axes[0], color='steelblue', edgecolor='white')axes[0].set_title('住宅価格の分布')axes[0].set_xlabel('住宅価格の中央値(10万ドル単位)')
# 相関corr = df.corr()['MedHouseVal'].drop('MedHouseVal').sort_values()corr.plot.barh(ax=axes[1], color='coral')axes[1].set_title('各特徴量と住宅価格の相関')plt.tight_layout()plt.show()ステップ 1.1 最初に考えるべきこと
Section titled “ステップ 1.1 最初に考えるべきこと”データを最初に見るときは、ただグラフを描くだけで終わらせないようにしましょう。次の点を確認します。
- 目的変数の分布は偏っているか
- 目立つ異常値の範囲はあるか
- どの特徴量が価格と強く関係しそうか
- どの特徴量は弱いシグナルっぽいか
この確認は、その後の進め方に直結します。
- まず何を baseline にするか
- 特徴量エンジニアリングをどこから始めるか
- 誤差分析でどこを見るか
ステップ 1.2 初心者が最初に覚えておきたい判断
Section titled “ステップ 1.2 初心者が最初に覚えておきたい判断”回帰問題でよくある失敗は、次のようなものです。
- いきなりモデルを変えたくなる
でも、より安定した順番はこうです。
- まずデータを見る
- まず目的変数を理解する
- まず何を予測しているのか、その分布を知る
ステップ 2:特徴量エンジニアリング
Section titled “ステップ 2:特徴量エンジニアリング”# 新しい特徴量を作るdf['rooms_per_household'] = df['AveRooms'] / df['AveOccup']df['bedrooms_ratio'] = df['AveBedrms'] / df['AveRooms']df['population_per_household'] = df['Population'] / df['HouseAge']
# データの準備from sklearn.model_selection import train_test_split
feature_cols = [c for c in df.columns if c != 'MedHouseVal']X = df[feature_cols]y = df['MedHouseVal']X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)print(f"訓練データ: {X_train.shape}, テストデータ: {X_test.shape}")ステップ 2.1 最初の特徴量エンジニアリングで、なぜ控えめにするのか
Section titled “ステップ 2.1 最初の特徴量エンジニアリングで、なぜ控えめにするのか”回帰プロジェクトでよくあるミスの1つは、たくさん特徴量を一気に作ってしまい、結局どれが効いたのか分からなくなることです。 より安定したやり方は次の通りです。
- まずは意味のある新しい特徴量を2〜3個だけ追加する
- 追加するたびに baseline と比較する
- 大きな効果がないなら、「なんとなく高度そう」という理由で残さない
ステップ 2.2 実務に近い特徴量の考え方
Section titled “ステップ 2.2 実務に近い特徴量の考え方”住宅価格の問題では、次のような「単位あたり」や「相対的な関係」を表す特徴量を考えるのが有効です。
- 1部屋あたりの人数
- 1戸あたりの部屋数
- 築年数と場所の組み合わせ
こうした特徴量は、ただ列を増やすよりも、実際の建模の考え方に近いです。
ステップ 3:複数モデルの比較
Section titled “ステップ 3:複数モデルの比較”from sklearn.linear_model import LinearRegression, Ridgefrom sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressorfrom sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import make_pipelinefrom sklearn.metrics import mean_squared_error, r2_score
models = { '線形回帰': make_pipeline(StandardScaler(), LinearRegression()), 'Ridge': make_pipeline(StandardScaler(), Ridge(alpha=1.0)), 'ランダムフォレスト': RandomForestRegressor(n_estimators=100, random_state=42), 'GBDT': GradientBoostingRegressor(n_estimators=100, random_state=42),}
results = {}for name, model in models.items(): model.fit(X_train, y_train) y_pred = model.predict(X_test) rmse = np.sqrt(mean_squared_error(y_test, y_pred)) r2 = r2_score(y_test, y_pred) results[name] = {'RMSE': rmse, 'R²': r2} print(f"{name:10s} | RMSE: {rmse:.4f} | R²: {r2:.4f}")
# 可視化fig, ax = plt.subplots(figsize=(8, 5))names = list(results.keys())r2s = [v['R²'] for v in results.values()]bars = ax.bar(names, r2s, color=['steelblue', 'coral', 'seagreen', 'gold'], alpha=0.8)for bar, score in zip(bars, r2s): ax.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.005, f'{score:.4f}', ha='center')ax.set_ylabel('R²')ax.set_title('モデルの R² 比較')ax.grid(axis='y', alpha=0.3)plt.show()ステップ 3.1 モデル比較で本当に見るべきこと
Section titled “ステップ 3.1 モデル比較で本当に見るべきこと”「どの R² が一番高いか」だけを見ないようにしましょう。もっと安定した比較は、次の3点を同時に見ることです。
RMSEがどれくらい下がったか- モデルの複雑さがどれくらい増えたか
- 説明しやすさがどれくらい下がったか
最初の回帰プロジェクトで本当に価値があるのは、単なる「最高スコアのモデル」ではなく、
- なぜ baseline より良くなったのか
- どこが良くなったのか
を説明できることです。
ステップ 3.2 初心者がそのまま使いやすい比較表
Section titled “ステップ 3.2 初心者がそのまま使いやすい比較表”| モデル | 良い点 | 最初の重点 |
|---|---|---|
| 線形回帰 | 最も説明しやすい | baseline が安定しているか |
| Ridge | 少し安定しやすい | 正則化が効いているか |
| ランダムフォレスト | 非線形を扱いやすい | 特徴量重要度と過学習リスク |
| GBDT | 高い性能が出やすい | RMSE が明確に下がるか |
この表は、「モデル名」を「なぜ試すのか」に戻して考えるのに役立ちます。
ステップ 4:モデルチューニング
Section titled “ステップ 4:モデルチューニング”from sklearn.model_selection import RandomizedSearchCVfrom scipy.stats import randint, uniform
param_dist = { 'n_estimators': randint(100, 500), 'max_depth': randint(5, 20), 'learning_rate': uniform(0.01, 0.2), 'subsample': uniform(0.7, 0.3),}
rs = RandomizedSearchCV( GradientBoostingRegressor(random_state=42), param_dist, n_iter=30, cv=5, scoring='neg_root_mean_squared_error', random_state=42, n_jobs=-1)rs.fit(X_train, y_train)
y_pred_best = rs.predict(X_test)print(f"チューニング後の RMSE: {np.sqrt(mean_squared_error(y_test, y_pred_best)):.4f}")print(f"チューニング後の R²: {r2_score(y_test, y_pred_best):.4f}")print(f"最適パラメータ: {rs.best_params_}")ステップ 5:結果の分析
Section titled “ステップ 5:結果の分析”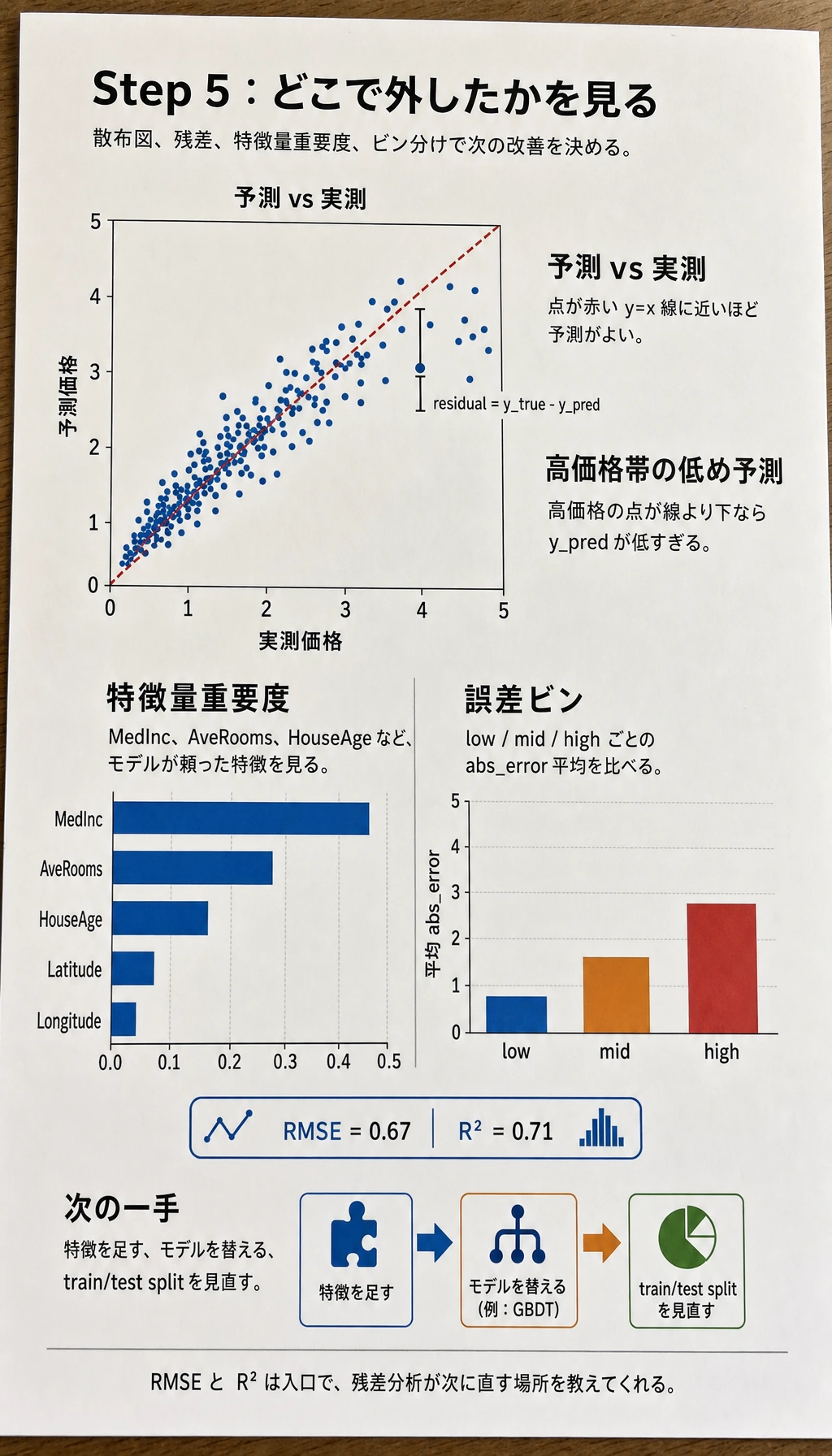
この図は、予測値と実測値を比べ、残差の偏りを確認してからモデルや特徴量を変えるためのチェックリストです。
# 予測値 vs 実測値fig, axes = plt.subplots(1, 2, figsize=(12, 5))
axes[0].scatter(y_test, y_pred_best, s=5, alpha=0.3)axes[0].plot([0, 5], [0, 5], 'r--')axes[0].set_xlabel('実際の住宅価格')axes[0].set_ylabel('予測住宅価格')axes[0].set_title('予測値 vs 実測値')
# 特徴量重要度importance = rs.best_estimator_.feature_importances_sorted_idx = np.argsort(importance)axes[1].barh(range(len(sorted_idx)), importance[sorted_idx], color='coral')axes[1].set_yticks(range(len(sorted_idx)))axes[1].set_yticklabels(np.array(feature_cols)[sorted_idx])axes[1].set_title('特徴量重要度')
plt.tight_layout()plt.show()ステップ 5.1 残差分析は、最終スコア以上に「できる人かどうか」が出る
Section titled “ステップ 5.1 残差分析は、最終スコア以上に「できる人かどうか」が出る”ここまで来ると、多くの人は RMSE と R² だけ見て終わりがちです。
でも、プロジェクトの質を大きく左右するのは残差分析です。
- どの価格帯で誤差が大きいか
- 高価格帯を系統的に低く見積もっていないか
- どの地域や特徴の組み合わせで外しやすいか
この分析によって、次に何をすべきかが見えてきます。
- 特徴量を追加する
- モデルを変える
- データの分け方を見直す
ステップ 5.2 最小の「誤差のビン分け」例
Section titled “ステップ 5.2 最小の「誤差のビン分け」例”errors = pd.DataFrame({ "y_true": [1.0, 2.5, 4.2, 3.8], "y_pred": [1.2, 2.0, 3.1, 4.5],})errors["abs_error"] = (errors["y_true"] - errors["y_pred"]).abs()errors["bucket"] = pd.cut(errors["y_true"], bins=[0, 2, 4, 6], labels=["low", "mid", "high"])
print(errors.groupby("bucket", observed=False)["abs_error"].mean())期待される出力:
bucketlow 0.2mid 0.6high 1.1Name: abs_error, dtype: float64この例は初学者にとても役立ちます。大事なのは次の習慣を作ることです。
- 誤差は全体平均だけで見ない
- どの種類のサンプルで外れやすいかも見る
この小さな例では、high 価格帯の平均誤差が最も大きくなります。これは、すべての住宅価格モデルが高価格帯で失敗するという意味ではありません。Step 5 の使い方、つまり散布図で見えた現象を「次にどの bucket を調べるか」という改善質問へ変える練習です。
初心者向けの最小振り返り表
Section titled “初心者向けの最小振り返り表”そのまま次のような表を作ると分かりやすいです。
| 版 | 何を変えたか | 自分の判断 |
|---|---|---|
| baseline | 線形回帰 | まず下限を作る |
| v2 | 特徴量を2-3個追加 | 特徴量エンジニアリングの効果を見る |
| v3 | 木モデル / GBDT に変更 | 非線形モデルが合うか確認する |
RMSE と R² は notebook や実験ログに残します。レポートでは、比較できる実数がそろってから指標列を追加すれば十分です。
この表があると、ただコードを動かしただけの状態から、「きちんと改善を重ねたプロジェクト」に変わります。
初心者がそのまま使いやすいチェックリスト
Section titled “初心者がそのまま使いやすいチェックリスト”住宅価格予測プロジェクトの最初の作業として、次のチェックリストが安定しています。
- baseline がちゃんと作れているか
- 特徴量エンジニアリングに明確な意味があるか
- モデル比較で1つのスコアだけを見ていないか
- 残差分析で次に直すべき点が見えているか
この4つができていれば、 もう単なる「回帰スクリプトを実行した」レベルではなく、ちゃんと一度モデルを作り切ったと言えます。
さらにこのプロジェクトを発展させるなら、何を足すべきか
Section titled “さらにこのプロジェクトを発展させるなら、何を足すべきか”優先して足すとよいのは、次のような内容です。
- 残差分布の分析
- 地域別・価格帯別の誤差比較
- baseline から最良モデルまでの改善の流れの整理
こうすると、単なる予測コードではなく、「モデリングと振り返りをした作品」になります。
プロジェクト提出時に補っておくとよいもの
Section titled “プロジェクト提出時に補っておくとよいもの”- 「実測値 vs 予測値」の図
- 誤差の原因に関する説明
- baseline と改善版の比較表
- 「もし続けるなら何を優先して改善するか」のまとめ
ポートフォリオとして見せるなら、何を見せるべきか
Section titled “ポートフォリオとして見せるなら、何を見せるべきか”このテーマをポートフォリオページにするなら、たくさんのモデル名を並べるより、次の点が大切です。
- baseline は何だったか
- どの改善がいちばん効いたか
- 改善前後で
RMSE / R²がどう変わったか - 残差分析で何が分かったか
- 次にどう改善する予定か
プロジェクトチェックリスト
Section titled “プロジェクトチェックリスト”- EDA を完了した:分布、相関、欠損値
- 特徴量エンジニアリング:少なくとも 2 個の新特徴量を作成
- 少なくとも 3 種類のモデルを比較
- 最良モデルをハイパーパラメータ調整
- 残差分析と特徴量重要度分析
プロジェクト参考とレビュー観点
- EDA は図を描くだけでは完了しません。分布、欠損値、相関、怪しい外れ値を記録し、それがモデリングにどう影響するかを書きます。
- 新しい特徴量には、面積比や品質の集約のような住宅価格としての意味が必要です。未来情報や目的変数から作った特徴量は leakage として除外します。
- 複数モデルの比較では、同じ split または同じ交差検証を使います。単純な baseline を残して初めて、改善の効果を正直に判断できます。
- ハイパーパラメータ調整は baseline が動いてから行います。検証データまたは交差検証で調整し、テストセットは最後の確認だけに使います。
- 残差分析では、どこで外しやすいかを説明します。たとえば高価格帯や特定地域で誤差が大きいなら、次の実験はそこから考えます。
バージョンの進め方
Section titled “バージョンの進め方”| バージョン | 目的 | 提出の重点 |
|---|---|---|
| 基礎版 | 最小の一連の流れを通す | 入力できる、処理できる、出力できる、そしてサンプルを1つ残す |
| 標準版 | 見せられるプロジェクトにする | 設定、ログ、エラー処理、README、スクリーンショットを追加する |
| チャレンジ版 | ポートフォリオ品質に近づける | 評価、比較実験、失敗サンプル分析、次の改善方針を追加する |
まずは基礎版を完成させるのがおすすめです。最初から何でも盛り込もうとしないでください。バージョンを1つ上げるたびに、「何を追加したか、どう検証したか、まだ何が課題か」を README に書きましょう。