6.6.2 GAN 基礎 [任意]
- generator と discriminator の役割を説明できる。
- 1D データで最小の PyTorch GAN を動かせる。
loss_d、loss_g、fake_mean、fake_stdを訓練信号として読める。- mode collapse と D/G の不均衡を見つけられる。
- GAN が役立つ場面と、diffusion など他の生成手法を優先すべき場面を区別できる。
まずゲームを見る
Section titled “まずゲームを見る”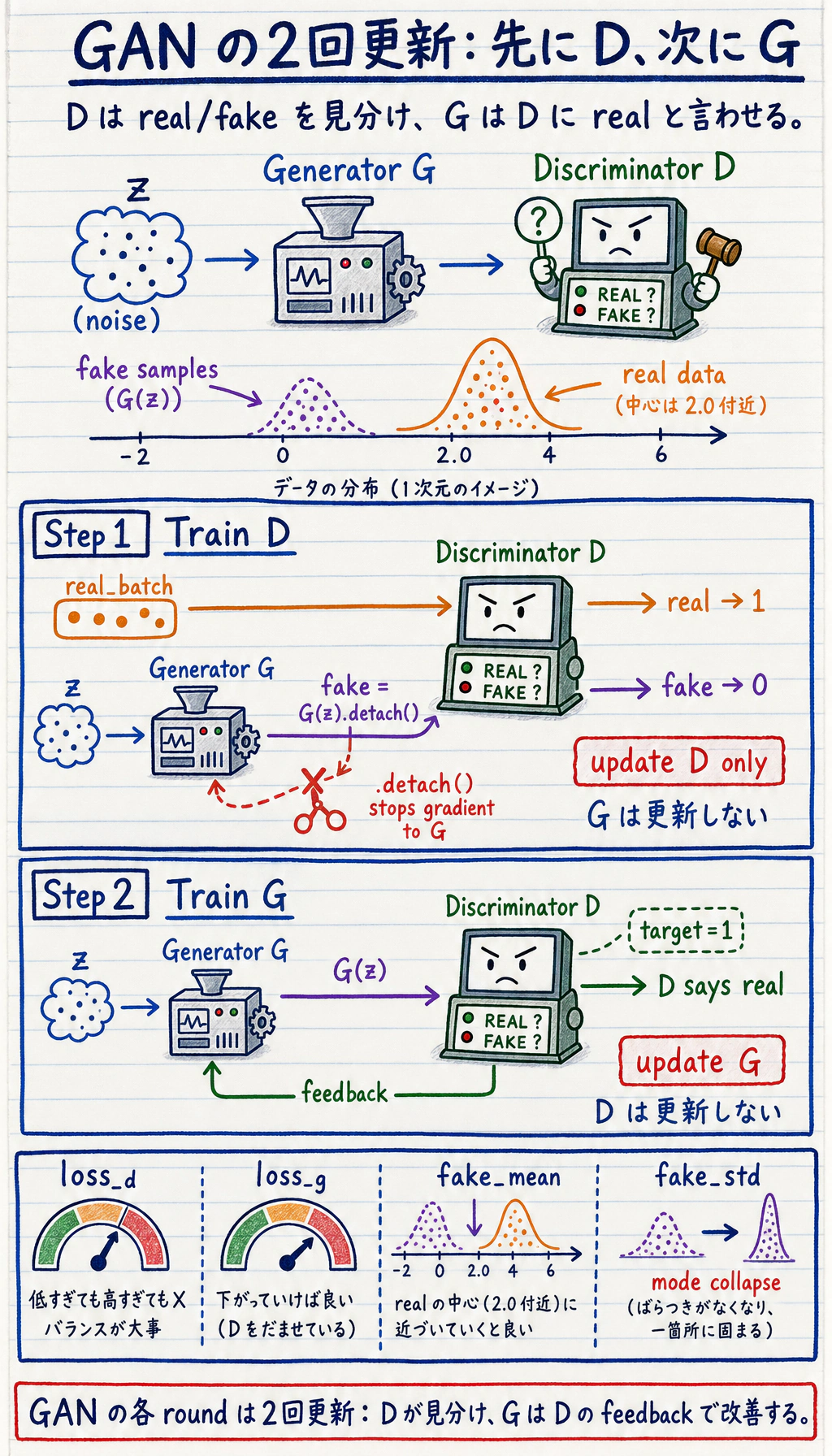
| 部品 | 入力 | 出力 | 目標 |
|---|---|---|---|
Generator G | ランダムノイズ z | fake sample | fake を本物らしくする |
Discriminator D | real または fake sample | real/fake score | 本物と偽物を分ける |
| Training loop | G と D の更新 | 変化し続けるゲーム | 両者を学習させ続ける |
GAN は通常の分類のように、固定されたラベル目標だけで学習するわけではありません。discriminator は「だましにくさ」を変え、generator は fake sample の姿を変えます。
GAN の 1 step は 2 回の更新として読みます。
1. D を訓練する:real -> real, G(z).detach() -> fake2. G を訓練する:G(z) が D に real と言わせるdiscriminator 側の step にある .detach() は重要です。D を更新するときに、generator まで誤って変わるのを防ぎます。
実験:小さな 1D GAN を訓練する
Section titled “実験:小さな 1D GAN を訓練する”この例は画像を生成しません。中心が 2.0 付近の 1D 分布で、訓練の仕組みを学ぶためのものです。
tiny_gan_1d.py を作成します。
import torchfrom torch import nn
torch.manual_seed(7)
def real_batch(n): return torch.randn(n, 1) * 0.2 + 2.0
G = nn.Sequential(nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 1))D = nn.Sequential(nn.Linear(1, 16), nn.ReLU(), nn.Linear(16, 1))
loss_fn = nn.BCEWithLogitsLoss()opt_g = torch.optim.Adam(G.parameters(), lr=0.01)opt_d = torch.optim.Adam(D.parameters(), lr=0.01)
for step in range(1, 301): real = real_batch(64) z = torch.randn(64, 2) fake = G(z).detach()
d_real = D(real) d_fake = D(fake) loss_d = loss_fn(d_real, torch.ones_like(d_real)) + loss_fn( d_fake, torch.zeros_like(d_fake) )
opt_d.zero_grad() loss_d.backward() opt_d.step()
z = torch.randn(64, 2) fake = G(z) d_fake = D(fake) loss_g = loss_fn(d_fake, torch.ones_like(d_fake))
opt_g.zero_grad() loss_g.backward() opt_g.step()
if step in [1, 100, 200, 300]: with torch.no_grad(): sample = G(torch.randn(256, 2)) print( f"step={step:03d} " f"loss_d={loss_d.item():.3f} " f"loss_g={loss_g.item():.3f} " f"fake_mean={sample.mean().item():.3f} " f"fake_std={sample.std().item():.3f}" )実行します。
python tiny_gan_1d.py期待される出力:
step=001 loss_d=1.579 loss_g=0.844 fake_mean=0.025 fake_std=0.117step=100 loss_d=1.287 loss_g=0.654 fake_mean=1.093 fake_std=0.204step=200 loss_d=1.460 loss_g=0.835 fake_mean=2.988 fake_std=0.291step=300 loss_d=1.307 loss_g=0.630 fake_mean=1.384 fake_std=0.056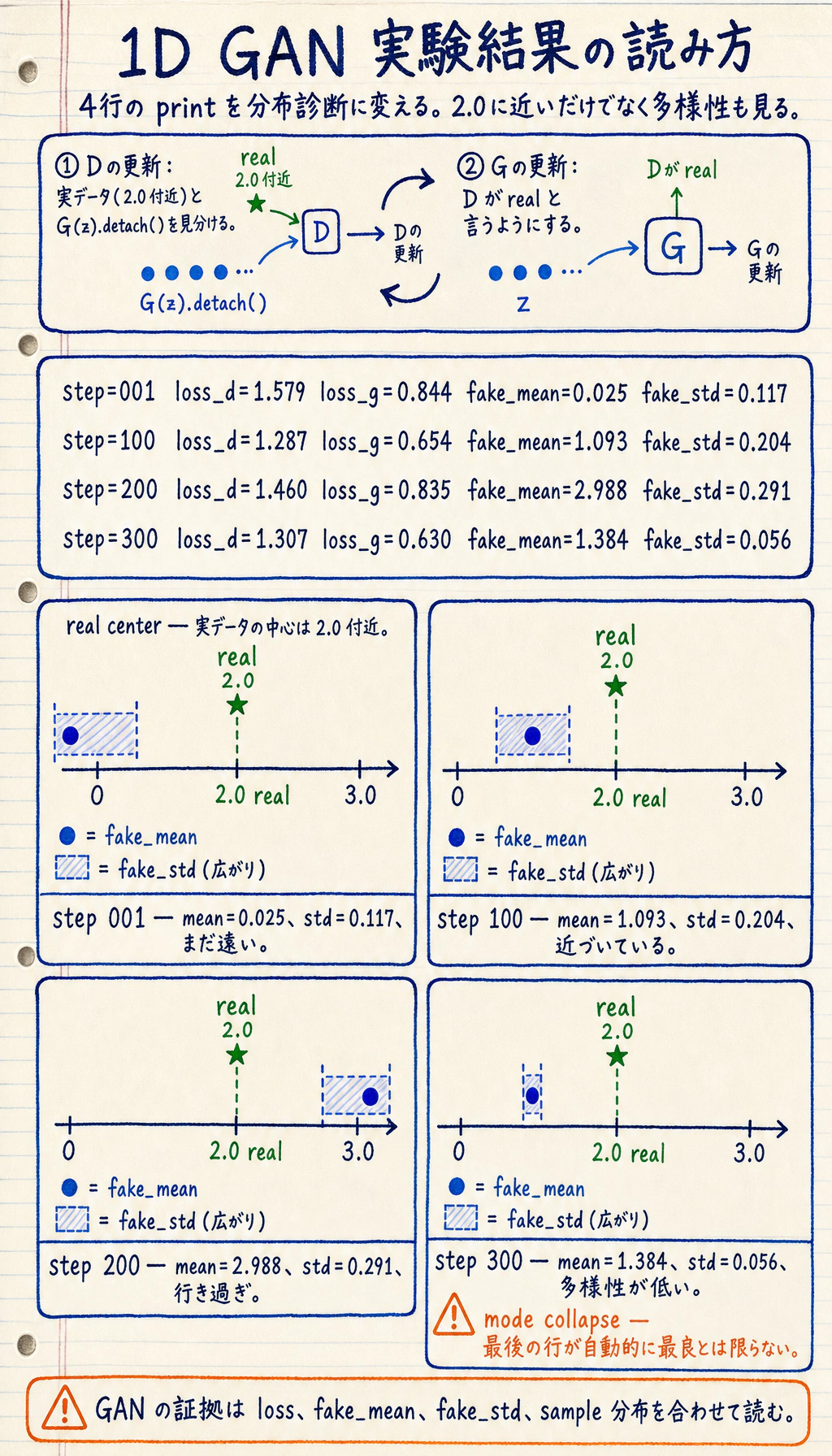
最後の行が一番良い、とは読まないでください。これは診断用の実験です。
- real sample は
2.0付近にあります。 fake_meanは動きます。GとDが追いかけ合うからです。fake_stdがとても小さい場合、多様性不足に注意します。- GAN の loss は、sample の確認なしでは解釈しにくいです。
GAN 実行では loss だけでなく、生成分布のメモを残します。
- 実数中心
- 2.0 付近
- ステップ001
- fake_mean=0.025, fake_std=0.117
- ステップ300
- fake_mean=1.384, fake_std=0.056
- 診断
- 最後の行が自動的に最善とは限らない
- 収束シグナル
- fake_std が非常に小さくなる
- レビュー規則
- loss だけでなく、サンプルや分布を比較する
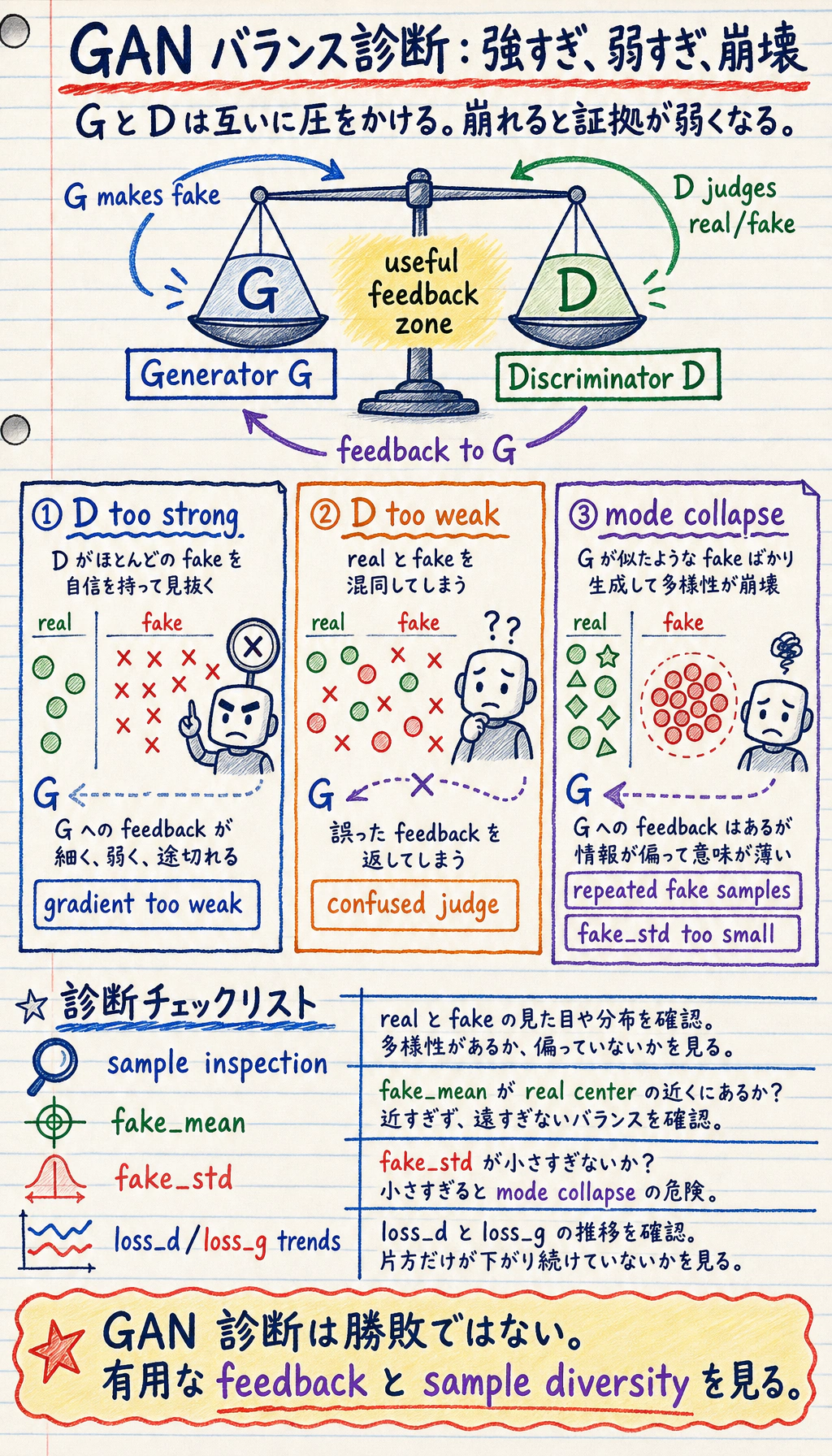
Mode Collapse とは
Section titled “Mode Collapse とは”Mode collapse は、generator が discriminator をだませる狭いパターンを見つけ、その似た sample ばかりを作る状態です。
画像では、ほぼ同じ向きの顔が何度も出るように見えるかもしれません。1D 実験では、とても小さい fake_std が単純な collapse 信号になります。
本物らしく見えるが多様性がない -> mode collapse を疑うGAN 訓練が難しい理由
Section titled “GAN 訓練が難しい理由”| 問題 | 症状 | 最初の対応 |
|---|---|---|
| Discriminator が強すぎる | G が有用な feedback を受けにくい | D の更新回数や容量を下げる |
| Generator が弱すぎる | fake sample が良くならない | 学習率、構造、正規化を調整する |
| Mode collapse | sample が繰り返しになる | 多様性を監視し、loss や正則化を改善する |
| Loss が紛らわしい | loss は変わるが sample が悪化する | sample grid を保存して比較する |
| 評価が曖昧 | “良さそう”が主観的 | 視覚確認、多様性、タスク指標を組み合わせる |
GAN を学ぶ価値
Section titled “GAN を学ぶ価値”GAN は今でも学ぶ価値があります。adversarial learning、distribution matching、失敗診断をとてもはっきり見せてくれるからです。
現代の画像生成プロジェクトでは、diffusion model の方が安定し、制御しやすいことが多いです。それでも GAN は次の理解に役立ちます。
- 訓練後の高速 sampling。
- adversarial realism signal。
- 生成 sample の多様性。
- 不安定な multi-objective training の具体例。
よくある間違い
Section titled “よくある間違い”| 間違い | 直し方 |
|---|---|
loss_g と loss_d だけで判断する | 生成 sample と多様性も確認する |
D の step で G も更新してしまう | G(z).detach() を使う |
D が早すぎる段階で完璧になる | 容量、更新比率、学習率を調整する |
| 繰り返し出力を無視する | 多様性と mode collapse を追跡する |
| すべての生成タスクで GAN をデフォルトにする | VAE、diffusion、autoregressive method と比較する |
- real data の中心を
2.0から-1.0に変えてください。fake_meanは動きますか。 lrを0.01から0.001に下げてください。訓練は滑らかになりますか、それとも遅くなりますか。- hidden size を
16から64に増やしてください。ゲームは安定しますか。 - 25 step ごとに
fake_stdを表示し、collapse らしい点を記録してください。 - GAN の出力品質を 1 つの loss だけで判断できない理由を説明してください。
参考実装と解説
- 学習がうまく進むなら、
fake_meanは新しい real data の中心に近づきます。動かない場合は generator と discriminator のバランスを疑います。 - 小さい学習率は滑らかになりやすい一方で遅くなります。短い step 数ではまだ分布に届かないことがあります。
- hidden size を増やすと容量は増えますが、GAN の安定性が自動的に上がるわけではありません。学習率や discriminator の強さも効きます。
fake_stdが長く 0 に近い場合は、似た出力ばかり生成する collapse の兆候です。- GAN の loss は対戦相手の強さにも左右されます。サンプル、平均、分散、多様性を合わせて見ないと品質判断はできません。
- GAN 訓練は変化し続ける 2 人ゲームです。
Gは sample を作り、Dは real/fake を判定します。- 不安定さは単なるコードミスではなく、訓練設定そのものに含まれます。
- Mode collapse は「本物らしいが多様性がない」状態です。
- 本番で別の生成モデルを選ぶ場合でも、GAN は理解する価値があります。