9.3.6 ツールの安全性とエラー処理
- ツールのリスクが、なぜ純テキスト回答より高いのかを理解する
- 権限の段階分け、パラメータ検証、エラー返却を設計できるようにする
- リトライ、タイムアウト、冪等性、手動確認がそれぞれ何を防ぐのかを理解する
- 実行可能な例を通して、安全ガード付きのツール実行器を理解する
なぜツールの安全性は Agent の最重要ラインなのか?
Section titled “なぜツールの安全性は Agent の最重要ラインなのか?”純粋な回答のミスは、たいてい「言い間違い」
Section titled “純粋な回答のミスは、たいてい「言い間違い」”もしモデルがテキストだけを返すなら、
間違いの影響はたいてい次のようなものです。
- 情報が正確ではない
- 表現が誤解を招く
もちろんこれも重要ですが、
多くの場面ではまだ「出力の問題」にとどまります。
ツール呼び出しのミスは、「実行ミス」になる
Section titled “ツール呼び出しのミスは、「実行ミス」になる”一度ツールに実行能力があると、
リスクは次のように変わります。
- 見てはいけないデータを見てしまう
- ファイルを壊してしまう
- 外部 API を間違って呼ぶ
- 注文を二重に出す、二重に課金する
つまり、
ツールは、エラーを言語レベルから行動レベルへと拡大してしまうのです。
例えで言うと:チャットボットと研修中の作業担当者は同じリスクではない
Section titled “例えで言うと:チャットボットと研修中の作業担当者は同じリスクではない”処理の流れを説明するだけのボットと、
実際にボタンを押したり、データベースを更新したり、メールを送ったりできる担当者は、
リスクの大きさがまったく違います。
Agent がツール層に入るときも、まったく同じです。
ツールの安全性でよく使う 4 つの防御線
Section titled “ツールの安全性でよく使う 4 つの防御線”パラメータ検証
Section titled “パラメータ検証”まず確認するのは:
- パラメータはそろっているか
- 型は合っているか
- 値は正しいか
権限の段階分け
Section titled “権限の段階分け”ツールごとにリスクは異なります。
よくある分け方は次のようなものです。
read_onlywrite_limiteddestructive
たとえば:
- タイムアウト
- 最大リトライ回数
- レート制限
- 冪等 key
最低でも、次の情報は記録すべきです。
- 誰が呼び出したか
- どのツールを選んだか
- パラメータは何か
- 成功したかどうか
- 何が返ったか
まずはガード付きの最小実行器を動かしてみよう
Section titled “まずはガード付きの最小実行器を動かしてみよう”次の例では、3 種類のツールをシミュレーションします。
- 低リスクの読み取り専用ツール
- 中リスクの書き込みツール
- 高リスクの削除ツール
そして実行前に次を行います。
- ホワイトリスト確認
- パラメータ検証
- 権限確認
- タイムアウトのシミュレーション
ALLOWED_TOOLS = { "search_docs": {"risk": "read_only", "required_args": ["keyword"]}, "update_profile": {"risk": "write_limited", "required_args": ["user_id", "city"]}, "delete_file": {"risk": "destructive", "required_args": ["path"]},}
def run_tool(name, arguments, user_role): if name not in ALLOWED_TOOLS: return {"ok": False, "error": "unknown_tool"}
meta = ALLOWED_TOOLS[name]
for field in meta["required_args"]: if field not in arguments: return {"ok": False, "error": f"missing_arg:{field}"}
if meta["risk"] == "destructive" and user_role != "admin": return {"ok": False, "error": "permission_denied"}
if name == "search_docs": return {"ok": True, "data": {"result": f"{arguments['keyword']} に関連するドキュメントが見つかりました"}}
if name == "update_profile": return { "ok": True, "data": {"message": f"ユーザー {arguments['user_id']} の都市を {arguments['city']} に更新しました"}, }
if name == "delete_file": return {"ok": True, "data": {"message": f"{arguments['path']} を削除しました"}}
return {"ok": False, "error": "tool_not_implemented"}
calls = [ ("search_docs", {"keyword": "返金"}, "guest"), ("update_profile", {"user_id": 7, "city": "台北"}, "operator"), ("delete_file", {"path": "/tmp/a.txt"}, "operator"),]
for call in calls: print(call, "->", run_tool(*call))期待される出力:
('search_docs', {'keyword': '返金'}, 'guest') -> {'ok': True, 'data': {'result': '返金 に関連するドキュメントが見つかりました'}}('update_profile', {'user_id': 7, 'city': '台北'}, 'operator') -> {'ok': True, 'data': {'message': 'ユーザー 7 の都市を 台北 に更新しました'}}('delete_file', {'path': '/tmp/a.txt'}, 'operator') -> {'ok': False, 'error': 'permission_denied'}このコードが「ホワイトリストにあるかどうかだけ」を見るよりずっと強いのはなぜ?
Section titled “このコードが「ホワイトリストにあるかどうかだけ」を見るよりずっと強いのはなぜ?”それは、単なるオン・オフの判定ではなく、
ツール安全性の実際の多層構造を表しているからです。
- まずツールが存在するか確認する
- 次にパラメータがそろっているか確認する
- さらに権限が足りるか確認する
- 最後に実行する
これが、実際のツール実行器がやるべきことです。
なぜ権限を「Agent を使えるかどうか」だけで分けてはいけないのか?
Section titled “なぜ権限を「Agent を使えるかどうか」だけで分けてはいけないのか?”リスクは一律ではないからです。
- ドキュメント検索はリスクが低い
- 情報更新は中程度のリスク
- ファイル削除は高リスク
だから権限はツールのリスクと結びつける必要があります。
単純な総合スイッチだけでは不十分です。
なぜ高リスクツールには手動確認がよく必要なのか?
Section titled “なぜ高リスクツールには手動確認がよく必要なのか?”モデルがほとんどの場面で正しく選べても、
高リスクな操作は完全自動化に向いていないからです。
典型的なやり方は:
- まず実行計画を作る
- その後、ユーザーまたは管理者の確認を求める
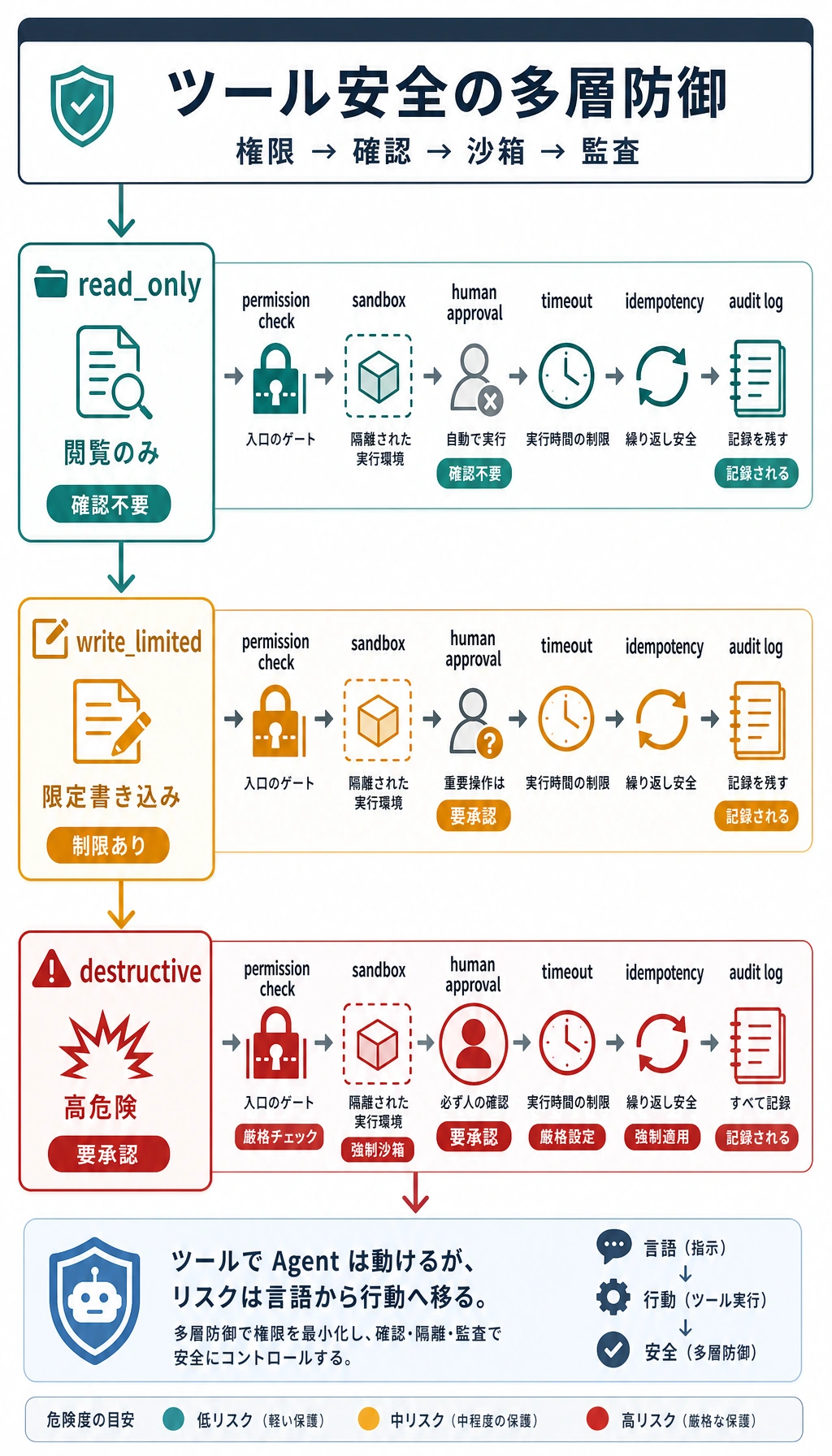
なぜエラー処理は try/except だけでは足りないのか?
Section titled “なぜエラー処理は try/except だけでは足りないのか?”失敗には種類があるから
Section titled “失敗には種類があるから”代表的な失敗は少なくとも次のとおりです。
- パラメータエラー
- 権限エラー
- ツールのタイムアウト
- 外部サービスの障害
- 結果が空
もしすべての失敗を次のようにしか返さないなら、
something went wrong
後でデバッグしたり復旧したりするのがほぼ不可能になります。
よりよい方法:エラーを構造化する
Section titled “よりよい方法:エラーを構造化する”def normalize_error(code, detail): return { "ok": False, "error": { "code": code, "detail": detail, "retryable": code in {"timeout", "temporary_unavailable"}, }, }
print(normalize_error("missing_arg", "keyword が不足しています"))print(normalize_error("timeout", "上流 API が 3 秒以内に返答しませんでした"))期待される出力:
{'ok': False, 'error': {'code': 'missing_arg', 'detail': 'keyword が不足しています', 'retryable': False}}{'ok': False, 'error': {'code': 'timeout', 'detail': '上流 API が 3 秒以内に返答しませんでした', 'retryable': True}}構造化エラーの利点は次のとおりです。
- スケジューラがリトライすべきか判断できる
- ログシステムで集計しやすい
- フロントエンドでも、よりわかりやすく表示できる
どんなエラーがリトライ向きか?
Section titled “どんなエラーがリトライ向きか?”一般に、リトライに向いているのは次のようなものです。
- timeout
- temporary unavailable
- transient network error
リトライに向いていないのは次のようなものです。
- パラメータ不足
- 権限不足
- ロジック検証の失敗
タイムアウト、リトライ、冪等性はそれぞれ何を防いでいるのか?
Section titled “タイムアウト、リトライ、冪等性はそれぞれ何を防いでいるのか?”タイムアウト:システムがずっと止まるのを防ぐ
Section titled “タイムアウト:システムがずっと止まるのを防ぐ”ツールがいつまでも返さないと、
Agent の処理全体が止まってしまいます。
だからタイムアウトは本質的に、次を守るためのものです。
- 遅延
- リソースの占有
リトライ:一時的な失敗を、そのまま最終失敗にしない
Section titled “リトライ:一時的な失敗を、そのまま最終失敗にしない”上流がたまに不安定になるだけなら、
適切なリトライで安定性をかなり上げられます。
ただしリトライは次と組み合わせる必要があります。
- それが一時的なエラーかどうか
- リトライ回数に上限があるかどうか
冪等性:同じ処理を二重に実行しないため
Section titled “冪等性:同じ処理を二重に実行しないため”たとえば:
- 二重課金
- 二重送信
- 二重でチケット作成
そのため、書き込み系のツールでは特に次を気にする必要があります。
- 同じリクエストが来たとき、重複した副作用が起きないか
監査ログはなぜ「あとで追加すればいい」ではないのか?
Section titled “監査ログはなぜ「あとで追加すればいい」ではないのか?”監査がないと、事故後に流れをたどれない
Section titled “監査がないと、事故後に流れをたどれない”少なくとも次のことに答えられる必要があります。
- 誰がどのツールを呼んだか
- そのときのパラメータは何だったか
- なぜシステムはそれを実行してよいと判断したか
- 最終結果は何だったか
最小の監査記録の例
Section titled “最小の監査記録の例”def audit_log(user_id, tool_name, arguments, result): return { "user_id": user_id, "tool_name": tool_name, "arguments": arguments, "ok": result["ok"], "error": result.get("error"), }
result = run_tool("search_docs", {"keyword": "返金"}, "guest")print(audit_log("u_001", "search_docs", {"keyword": "返金"}, result))期待される出力:
{'user_id': 'u_001', 'tool_name': 'search_docs', 'arguments': {'keyword': '返金'}, 'ok': True, 'error': None}これはシンプルですが、監査の核心はすでに入っています。
- 動作を記録する
- 文脈を記録する
- 結果を記録する
このページを終えたら、この証拠カードを残します。
- ツール契約
- 名前、説明、入力スキーマ、出力スキーマ
- 権限
- ツールが読み取りまたは変更を許可されている範囲
- 呼び出しトレース
- 引数、結果、エラー、再試行、またはフォールバック
- 失敗確認
- 間違ったツール、不適切な引数、危険な操作、または観測不足
- 安全対策
- 検証、確認、サンドボックス化、レート制限、またはロールバック
よくある誤解
Section titled “よくある誤解”誤解 1:ツールの安全性はリリース前に付け足せばいい
Section titled “誤解 1:ツールの安全性はリリース前に付け足せばいい”違います。
ツールの安全性は、設計段階から入っているべきです。
誤解 2:すべての失敗はとりあえずリトライすればいい
Section titled “誤解 2:すべての失敗はとりあえずリトライすればいい”パラメータエラーや権限エラーは、
リトライしてもリソースの無駄になるだけです。
誤解 3:読み取り操作には完全にリスクがない
Section titled “誤解 3:読み取り操作には完全にリスクがない”読み取り操作でも、次のような問題が起きることがあります。
- プライバシー
- 権限越えの問い合わせ
- 機微情報の漏えい
この節で一番大事なのは、いくつかのエラーコードを暗記することではなく、
ツール層に対する基本的な安全意識を持つことです。
Agent が行動できるようになったら、ツール実行器はバックエンドのコアサービスと同じように、権限、検証、タイムアウト、冪等性、監査をきちんと扱う必要があります。単に「モデルの後ろに関数をつないだだけ」と考えてはいけません。
この意識を早く身につけるほど、
後のコード Agent、多ツール連携、そして本番システムは安定します。
- サンプルに
send_emailツールを追加して、そのリスクレベルをどう決めるか考えてみましょう。 - なぜ「リトライ可能かどうか」はエラー構造の一部であるべきなのでしょうか?
- データベースを読むだけのツールでも、なぜ権限制御が必要になることがあるのでしょうか?
- 高リスクツールに手動確認を追加するなら、確認は呼び出し前と呼び出し後のどちらに置きますか? その理由も考えてみましょう。
参考実装と解説
send_emailは外部への副作用を生むため、通常は高リスクツールです。宛先検証、preview、confirmation、audit log が必要です。retry_allowedは重要です。読み取りの再試行と、支払い、メール送信、DB 書き込みの再試行では、副作用の重複リスクがまったく違うからです。- データベース読み取りでも、個人情報や規制対象データを露出する可能性があります。そのため read tool にも permission check、scope、filtering、logging が必要です。
- 高リスクツールでは、呼び出し前に具体的な action と input を見せて確認します。呼び出し後の確認では副作用を防げません。