12.1.1 マルチモーダルロードマップ:符号化、対応づけ、活用
マルチモーダル AI は、単に「画像をアップロードして会話する」ものではありません。役に立つシステムでは、画像、テキスト、音声、動画を構造化された観察に変え、タスクと対応づけ、検索、レビュー、制作、自動化へ流します。
まずパイプラインを見る
Section titled “まずパイプラインを見る”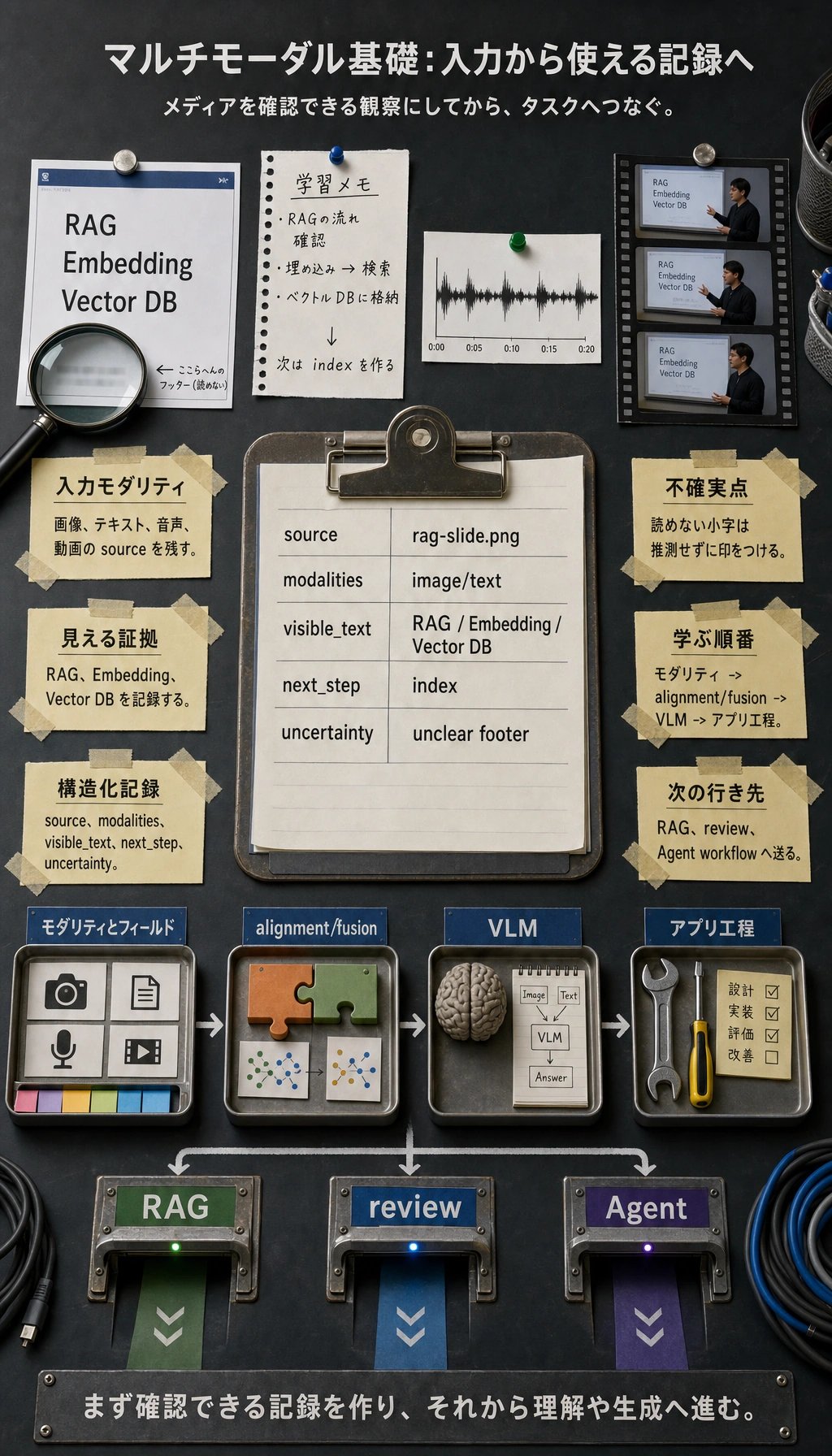


最初の習慣は、入力のモダリティ、見えている証拠、不確かな部分、構造化結果の次の行き先を確認することです。
模擬の視覚記録を動かす
Section titled “模擬の視覚記録を動かす”import json
visible_text = ["RAG", "Embedding", "Vector DB"]record = { "source": "rag-slide.png", "modalities": ["image", "text"], "visible_text": visible_text, "next_step": "send extracted text to retrieval index", "uncertainty": ["small footer text is unreadable"],}
print(json.dumps(record, indent=2))期待される出力:
{ "source": "rag-slide.png", "modalities": [ "image", "text" ], "visible_text": [ "RAG", "Embedding", "Vector DB" ], "next_step": "send extracted text to retrieval index", "uncertainty": [ "small footer text is unreadable" ]}実際の視覚モデルにつなぐ前でも、この小さな記録でプロダクト側のデータ構造を練習できます。
この順番で学ぶ
Section titled “この順番で学ぶ”| ステップ | 読む内容 | 練習の成果 |
|---|---|---|
| 1 | モダリティと表現 | 画像、テキスト、音声、動画の入力と構造化フィールドを列挙する |
| 2 | 対応づけと融合 | 画像の証拠がテキストタスクへどう接続されるか説明する |
| 3 | マルチモーダル応用 | スクリーンショットまたは文書理解の記録を作る |
1 枚の画像またはスクリーンショットを構造化テキストに変え、不確実性を記録し、その結果が RAG、レビュー、Agent ワークフローへどう入るか説明できれば、この章は通過です。
このページを終えたら、この evidence card を残します。
- ソース資産
- バージョン/出所注記付きの画像、スクリーンショット、PDF、音声、動画、またはテキスト入力
- 構造化レコード
- 表示テキスト、objects、regions、timestamp、transcript、または不確実性
- 融合結果
- 回答、検索記録、ルート決定、またはマルチモーダル特徴の比較
- 失敗確認
- 出典不足、OCR エラー、位置合わせミス、不確実性、または裏付けのない主張
- 期待される成果
- 後で引用またはレビューできる構造化レコード