7.4.1 事前学習ロードマップ:データ、目的、エンジニアリング
事前学習は、モデルが広い言語パターンを最初に学ぶ工程です。エンジニアリング視点では、データを整え、目的を決め、大規模に学習し、リスクを追跡します。
まず事前学習の三角形を見る
Section titled “まず事前学習の三角形を見る”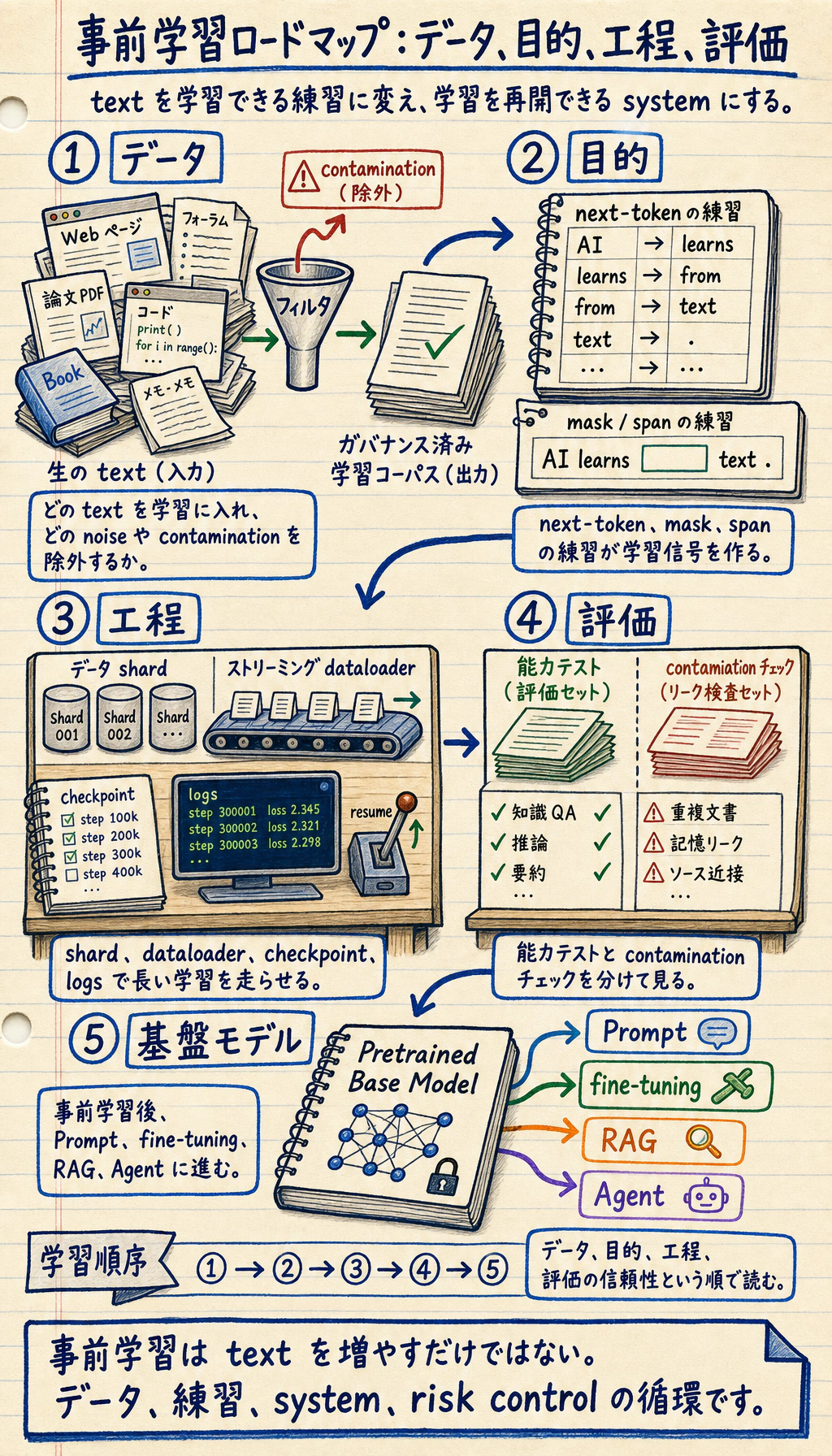
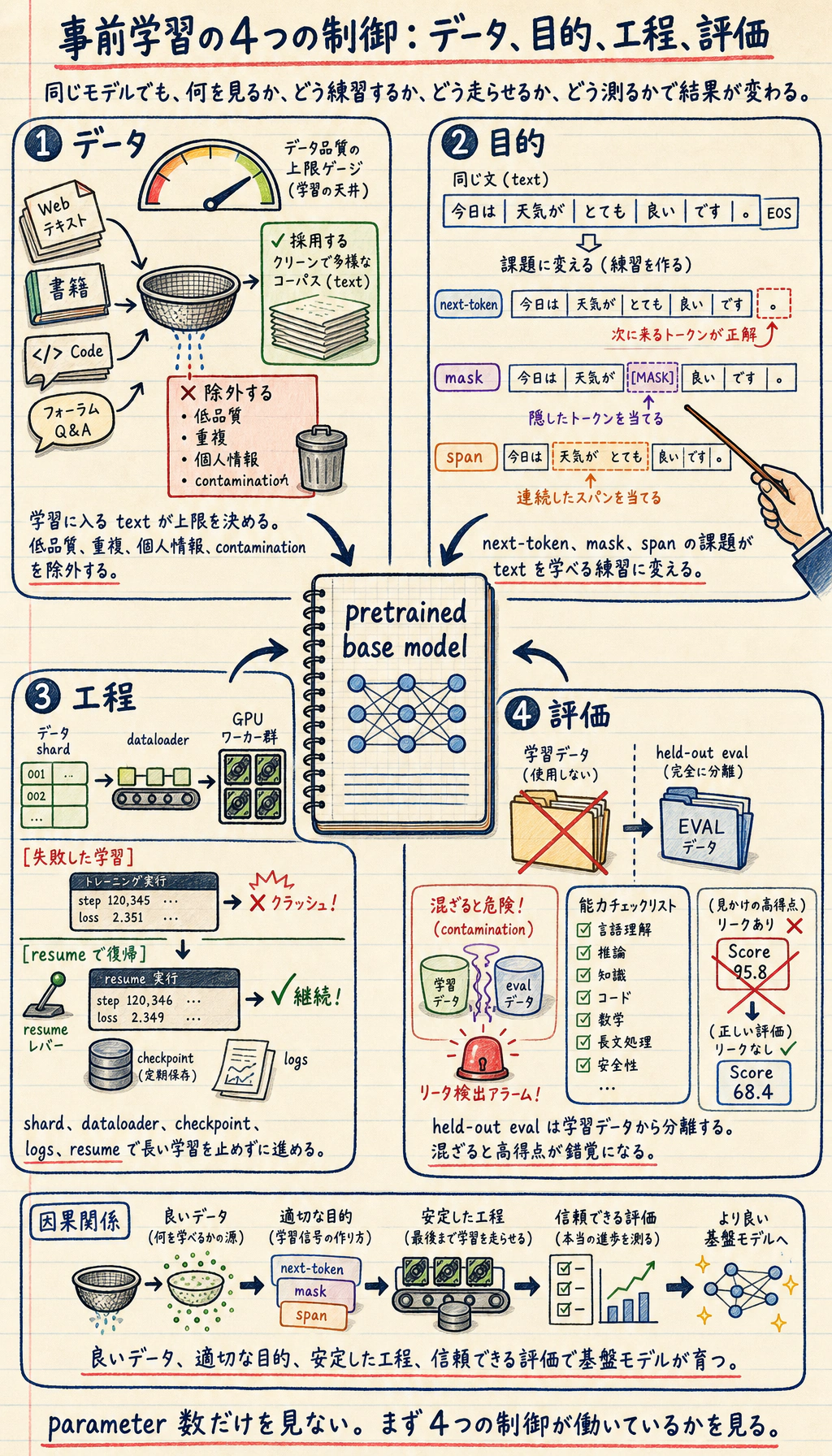
| 要素 | 最初に問うこと |
|---|---|
| データ | どのテキストを学習に入れ、何を除外するか |
| 目的 | どの予測タスクが学習信号を作るか |
| エンジニアリング | スケール、checkpoint、ログ、失敗をどう扱うか |
| 評価 | モデルに何ができ、どこで失敗するか |
next-token ペアを作る
Section titled “next-token ペアを作る”tokens = ["AI", "learns", "from", "text"]pairs = list(zip(tokens[:-1], tokens[1:]))
for source, target in pairs: print(f"{source} -> {target}")期待される出力:
AI -> learnslearns -> fromfrom -> text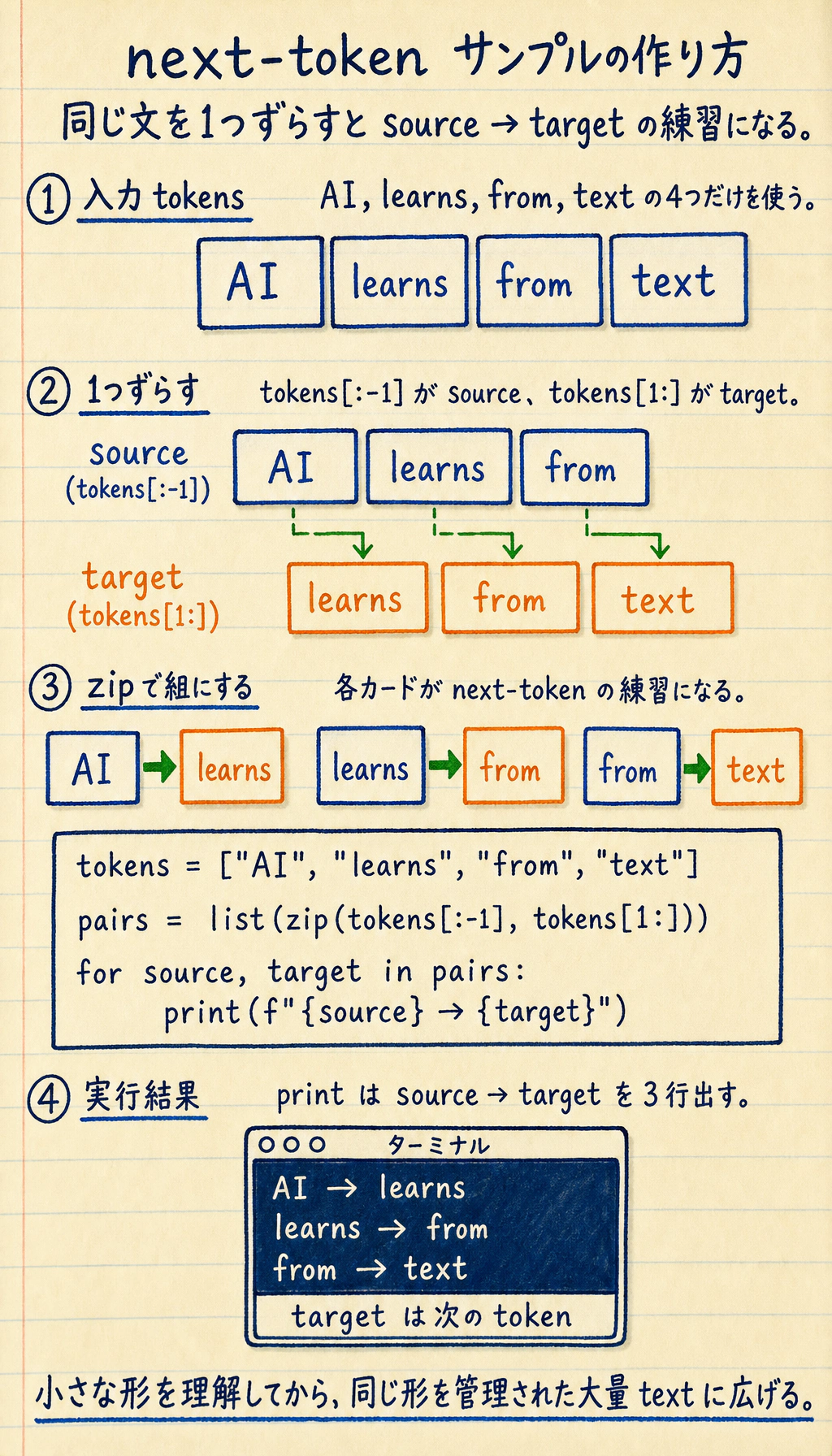
この小さな例が next-token prediction の形です。本物の事前学習では、これを巨大なテキストと厳密なデータガバナンスに広げます。
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | まず見ること |
|---|---|---|
| 1 | 7.4.2 事前学習データ | ソース、フィルタリング、重複除去、汚染 |
| 2 | 7.4.3 事前学習手法 | next-token prediction、loss、scaling |
| 3 | 7.4.4 事前学習エンジニアリング | 分散学習、checkpoint、監視 |
| 4 | 7.4.5 GPU を借りて手作り GPT-2 を学習する | プラットフォーム選択、環境構築、device: cuda で mini GPT-2 を逐次確認 |
このページを終えたら、この証拠カードを残します。
- 三角関係
- データ、目的関数、エンジニアリングのすべてが重要
- サンプル対
- 1文から作る次トークン学習ペア
- データのリスク
- 汚染、重複、または低品質な混在
- 目的メモ
- 目的が振る舞いとアーキテクチャの適合性を形作る
- エンジニアリングメモ
- シャーディング、再開、スループット、監視
- 実践ブリッジ
- 無料または低価格の GPU 計算環境で mini GPT-2 学習スクリプトを動かす
データ、目的、エンジニアリングが最終モデルへどう影響するか、contamination が評価を誤解させる理由、そして mini GPT-2 実験で CPU が smoke test、device: cuda が正式な学習証拠になる理由を説明できれば合格です。
確認の考え方と解説
- 合格レベルの答えでは、token、context、attention、prompt、生成挙動が1回の request-response path でどうつながるかを説明します。
- 証拠には、再現できる prompt または structured-output test を1つ残し、出力が通った理由または失敗した理由を書きます。
- prompt 設計、RAG、fine-tuning、alignment を切り分け、観察した問題を直す最も軽い方法を選べれば十分です。