9.6.4 LlamaIndex
- LlamaIndex の中心的な抽象概念を理解する
- なぜ知識・文書シーンに特に向いているのかを理解する
- Document -> Node -> Index -> 検索担当 -> クエリ Engine の流れを読み取れるようになる
- どんなときに LlamaIndex を優先して考えるべきか判断できるようになる
なぜ多くの LLM プロジェクトは、実はまず「知識システム」なのか?
Section titled “なぜ多くの LLM プロジェクトは、実はまず「知識システム」なのか?”すべてのシステムが対話問題を解くわけではない
Section titled “すべてのシステムが対話問題を解くわけではない”実際の LLM アプリケーションの中心は、チャットではなく次のようなものです。
- 企業ナレッジベースの QA
- 文書検索
- 研究資料の統合
- レポート作成の補助
これらのタスクに共通しているのは:
知識そのものの整理方法が、システム品質を直接左右する。
ここが LlamaIndex の一番価値があるところ
Section titled “ここが LlamaIndex の一番価値があるところ”LlamaIndex は単に「どうモデルを調整するか」を考えるのではなく、次のことを考えます。
- 文書をどうシステムに取り込むか
- 情報をどう分割するか
- 検索構造をどう作るか
- クエリをどう組み立てるか
なので、すごく実用的に言うと:
LlamaIndex は、純粋なワークフローフレームワークというより、知識システムのフレームワークに近い。
まず最重要の概念を整理しよう
Section titled “まず最重要の概念を整理しよう”ドキュメント(Document)
Section titled “ドキュメント(Document)”もっとも元になる知識単位です。 たとえば:
- 1 本の記事
- 1 つの PDF
- 1 つの Web ページの内容
ノード(Node)
Section titled “ノード(Node)”Document を分割した、より小さな単位です。 多くの知識システムでは、実際に検索に使うのは文書全体ではなく、もっと細かい粒度の node です。
インデックス(Index)
Section titled “インデックス(Index)”これらの node を、検索できる形に整理する方法です。
検索器(検索担当)
Section titled “検索器(検索担当)”ユーザーの質問に応じて、関連する node を探し出す役割です。
クエリエンジン(クエリ Engine)
Section titled “クエリエンジン(クエリ Engine)”「クエリ -> 検索 -> 結果の整理」を、より完成された 1 層としてまとめます。
まずは一言で覚えましょう。
文書は素材、ノードは切り分けた素材、インデックスは倉庫の構造、検索担当 は商品を探す係、クエリ Engine はそれをユーザーに渡す窓口です。
まずは純粋な Python でこの流れを見てみよう
Section titled “まずは純粋な Python でこの流れを見てみよう”文書 -> ノード
Section titled “文書 -> ノード”documents = [ {"id": "doc1", "text": "コース購入後 7 日以内かつ学習進捗が 20% 未満の場合は返金可能です。"}, {"id": "doc2", "text": "すべてのプロジェクトを完了し、テストに合格すると修了証が取得できます。"}]
nodes = []for doc in documents: nodes.append({ "doc_id": doc["id"], "text": doc["text"] })
print(nodes)想定出力:
[{'doc_id': 'doc1', 'text': 'コース購入後 7 日以内かつ学習進捗が 20% 未満の場合は返金可能です。'}, {'doc_id': 'doc2', 'text': 'すべてのプロジェクトを完了し、テストに合格すると修了証が取得できます。'}]この例はとてもシンプルですが、すでに大事な考え方を表しています。
元の文書は、そのまま質問応答に使うのではなく、インデックス化や検索に向いた知識単位へ先に変換することが多い。
なぜ「文書の取り込み」が知識システムの第一歩なのか?
Section titled “なぜ「文書の取り込み」が知識システムの第一歩なのか?”元の文書はたいてい汚れている
Section titled “元の文書はたいてい汚れている”実際の文書には、次のようなものが含まれがちです。
- ヘッダーやフッター
- 重複した段落
- 表のノイズ
- とても長い段落
最初にうまく処理しないと、その後の検索結果も悪くなりやすいです。
だから知識システムの最初の一歩は、たいてい「モデル調整」ではない
Section titled “だから知識システムの最初の一歩は、たいてい「モデル調整」ではない”むしろ次のような作業です。
- 文書を読む
- クリーニングする
- 分割する
- メタデータを付ける
だからこそ、LlamaIndex のようなフレームワークは ingest を特に重視します。
なぜインデックスと検索が中心になるのか?
Section titled “なぜインデックスと検索が中心になるのか?”知識アプリで一番怖いのは「文書はあるのに、システムが見つけられない」こと
Section titled “知識アプリで一番怖いのは「文書はあるのに、システムが見つけられない」こと”もし次のような状況なら:
- 文書が多い
- ノードが多い
- 質問の表現がとても柔軟
良いインデックス層と検索層がなければ、その後ろのモデルがどれだけ強くても引っ張られてしまいます。
最小の検索例
Section titled “最小の検索例”このコードをローカルで実行するなら、先に scikit-learn をインストールしてください。
from sklearn.feature_extraction.text import TfidfVectorizerfrom sklearn.metrics.pairwise import cosine_similarity
node_texts = [node["text"] for node in nodes]vectorizer = TfidfVectorizer(token_pattern=r"(?u)\b\w+\b")index_matrix = vectorizer.fit_transform(node_texts)
def retrieve(query): query_vec = vectorizer.transform([query]) scores = cosine_similarity(query_vec, index_matrix)[0] best_idx = scores.argmax() return nodes[best_idx]
print(retrieve("返金ポリシーは何ですか"))想定出力:
{'doc_id': 'doc1', 'text': 'コース購入後 7 日以内かつ学習進捗が 20% 未満の場合は返金可能です。'}このコードは、実際には何の抽象概念に対応しているのか?
Section titled “このコードは、実際には何の抽象概念に対応しているのか?”実はすでに次のものに対応しています。
- node
- index
- 検索担当
つまり、LlamaIndex の価値の多くは、この知識の流れをより体系的に整理するところにあります。
なぜ クエリ Engine を別に取り出す価値があるのか?
Section titled “なぜ クエリ Engine を別に取り出す価値があるのか?”質問応答は「一番似ている段落を返す」だけではないから
Section titled “質問応答は「一番似ている段落を返す」だけではないから”実際のシステムでは、たいてい次のことも考える必要があります。
- 何件返すか
- 要約するかどうか
- 出典を付けるか
- さらにモデルを呼び出すか
このとき「Query Engine」は、「単体の retriever」よりもシステム層の抽象概念に近くなります。
超ミニマルな クエリ Engine の例
Section titled “超ミニマルな クエリ Engine の例”def query_engine(query): node = retrieve(query) return { "answer": node["text"], "source": node["doc_id"] }
print(query_engine("返金ポリシーは何ですか"))想定出力:
{'answer': 'コース購入後 7 日以内かつ学習進捗が 20% 未満の場合は返金可能です。', 'source': 'doc1'}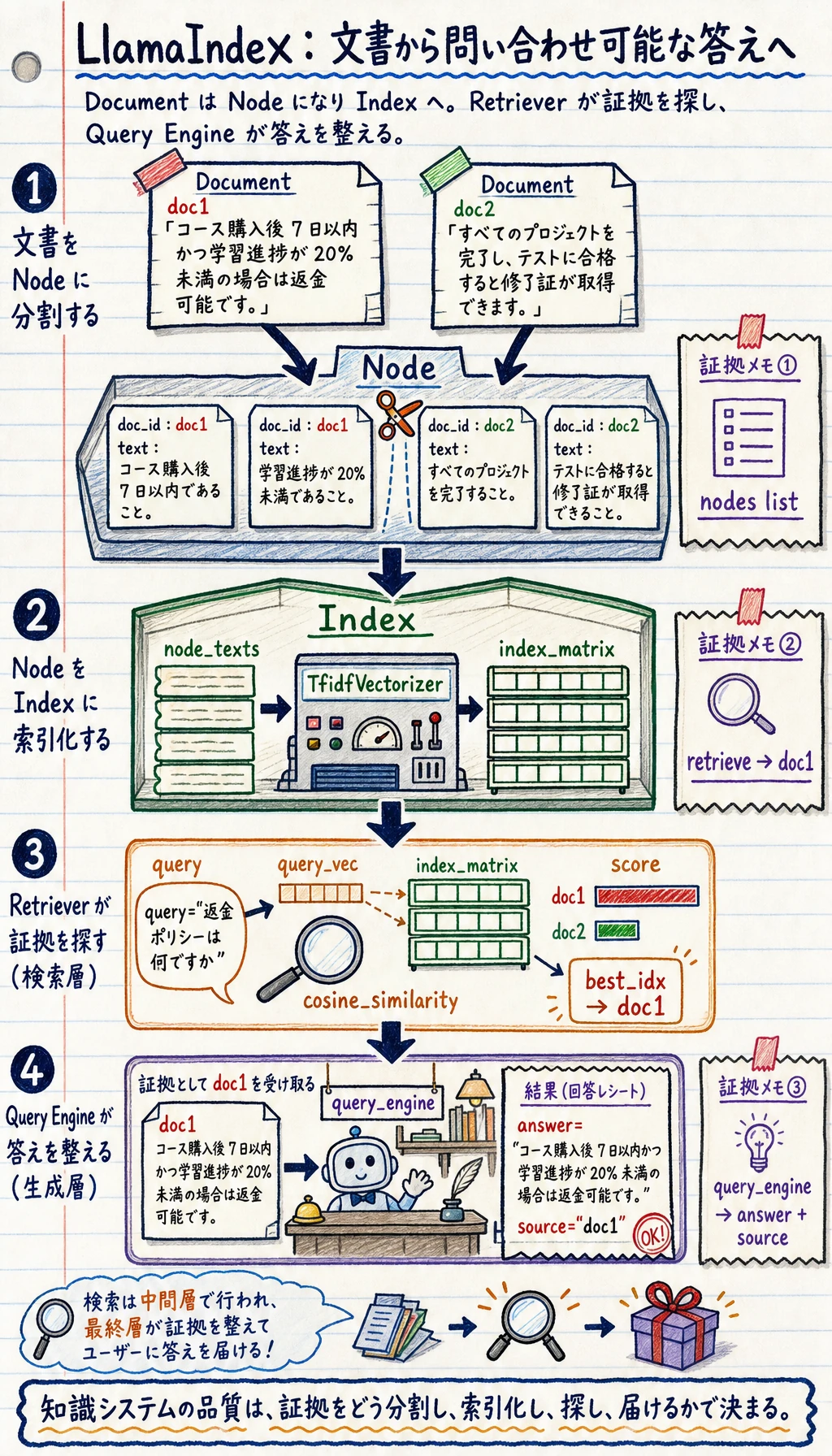
この例が教えてくれるのは:
検索は途中段階にすぎず、最終的には結果をユーザー向けの問い合わせ口としてまとめる層が必要だということです。
LlamaIndex と LangGraph の違いを一言で言うと?
Section titled “LlamaIndex と LangGraph の違いを一言で言うと?”かなり大ざっぱにまとめるなら、こう覚えられます。
- LangGraph は「タスクの状態をどう流すか」に寄る
- LlamaIndex は「知識をどう整理するか」に寄る
もちろん実際には組み合わせることもできますが、最初に注目しているポイントは確かに違います。
なので、あなたのプロジェクトの本質が次のようなものなら:
- 文書 QA
- ナレッジベースアシスタント
- RAG の本流
LlamaIndex のような抽象化のほうが、たいてい扱いやすいです。
どんなときは LlamaIndex が主役ではないのか?
Section titled “どんなときは LlamaIndex が主役ではないのか?”もしシステムがより次のような方向なら:
- マルチ Agent 協調
- 複雑なループ
- 明示的なステートマシン
その場合、LlamaIndex は「メインフレームワーク」ではなく、知識層のコンポーネントに近いかもしれません。
なので、「万能の Agent フレームワーク」と考えるのではなく、次のように捉えるのがよいです。
知識と検索の問題にとても強いフレームワーク。
初学者がよくやるミス
Section titled “初学者がよくやるミス”モデルだけ見て、文書の取り込みを見ない
Section titled “モデルだけ見て、文書の取り込みを見ない”知識システムの問題は、入口の文書処理に原因があることが多いです。
インデックスを作れば、もう QA システムは完成だと思ってしまう
Section titled “インデックスを作れば、もう QA システムは完成だと思ってしまう”インデックスは中間層であって、プロダクトのゴールではありません。
ワークフロー型フレームワークとの境界がわからない
Section titled “ワークフロー型フレームワークとの境界がわからない”その結果、本来あまり得意ではない問題まで解決してくれると期待しがちです。
このページを終えたら、この証拠カードを残します。
- 問題の形
- ワークフローグラフ、検索アプリ、役割チーム、または実験
- フレームワーク選択
- どの抽象化を追加し、何を隠すか
- 追跡記録
- state、node、tool call、message、または run id
- 失敗確認
- フレームワークの魔法が状態、再試行、または権限を隠す
- 判断
- シングルエージェントのループが明確になってからフレームワークを選ぶ
この節で一番大事なのは、LlamaIndex の API を覚えることではなく、次を理解することです。
LlamaIndex の価値は、文書知識を元のテキストから、検索可能で、引用可能で、問い合わせ可能な構造へと整理していくことにある。
LlamaIndex を「万能フレームワーク」ではなく「知識整理フレームワーク」として見ると、多くの判断がかなりわかりやすくなります。
- Document、Node、Index、検索担当、クエリ Engine がそれぞれ何に似ているか、自分の言葉で説明してみましょう。
- なぜ文書の取り込み品質が、その後の検索結果に直接影響すると言えるのか考えてみましょう。
- 自分の知識ベースデータから 3 つノードを作り直して、検索例をもう一度実行してみましょう。
- システムの主軸が知識検索ではなくマルチ Agent 協調の場合、なぜ LlamaIndex を「総合フレームワーク」にすべきとは限らないのか説明してください。
解法と解説
- Document は元資料、Node は検索可能な chunk、Index は整理された検索構造、Retriever は関連 node を選ぶ部品、Query Engine は retrieval と回答生成を組み合わせる部品です。
- ingestion 品質が重要なのは、悪い chunking、metadata 欠落、parse ノイズが後で retrieval 失敗になるからです。正しい根拠が context に届かなければ、モデルはうまく答えられません。
- 自分のデータで再実行したら、どの node が選ばれたか、なぜ選ばれたかを確認します。結果が弱い場合は chunk size、overlap、metadata、query の語彙が文書と合っているかを見ます。
- 主問題が multi-Agent collaboration なら、LlamaIndex は knowledge retrieval には有用でも、主 orchestration framework ではないかもしれません。最も強い抽象が documents と indexes から始まるためです。