5.6.6 実践ワークショップ:再現可能な ML 証拠パックを作る

- 表形式の業務課題を教師あり学習タスクに変換する
- 強いモデルを試す前に
DummyClassifierの baseline を作る ColumnTransformerとPipelineを使い、前処理を学習フローの中に閉じ込める- 交差検証とホールドアウトテストセットでモデルを比較する
0.5を魔法の値として扱わず、しきい値のトレードオフを確認する- 指標、エラーサンプル、リーク確認、実験ログをプロジェクト証拠として保存する
何を作るのか
Section titled “何を作るのか”このワークショップでは、ml_workshop_run/ という小さなローカルプロジェクトを作ります。
タスクは次の通りです。
学習者が次の学習タスクを遅らせる可能性が高いかを予測する。
データセットはローカルで生成する合成データなので、ダウンロードは不要です。練習時間やクイズ点数のような数値特徴量と、学習トラックや学習モードのようなカテゴリ特徴量を含みます。目的変数は delayed で、1 は学習者の遅延リスクが高いことを意味します。
| 第 5 章の考え方 | プロジェクトでやること |
|---|---|
| タスク定義 | 「遅延リスク」を二値分類に変換する |
| ベースライン | まず DummyClassifier を学習する |
| 特徴量前処理 | 欠損値補完、数値列のスケーリング、カテゴリ列の one-hot エンコードを行う |
| Pipeline | 前処理とモデル学習を 1 つの安全な流れにする |
| 評価 | F1、recall、precision、AUC、混同行列を比較する |
| しきい値 | 確率しきい値ごとの判断の違いを見る |
| エラー分析 | 誤予測サンプルを保存する |
| 作品集の証拠 | README、指標、エラーサンプル、リーク確認を保存する |
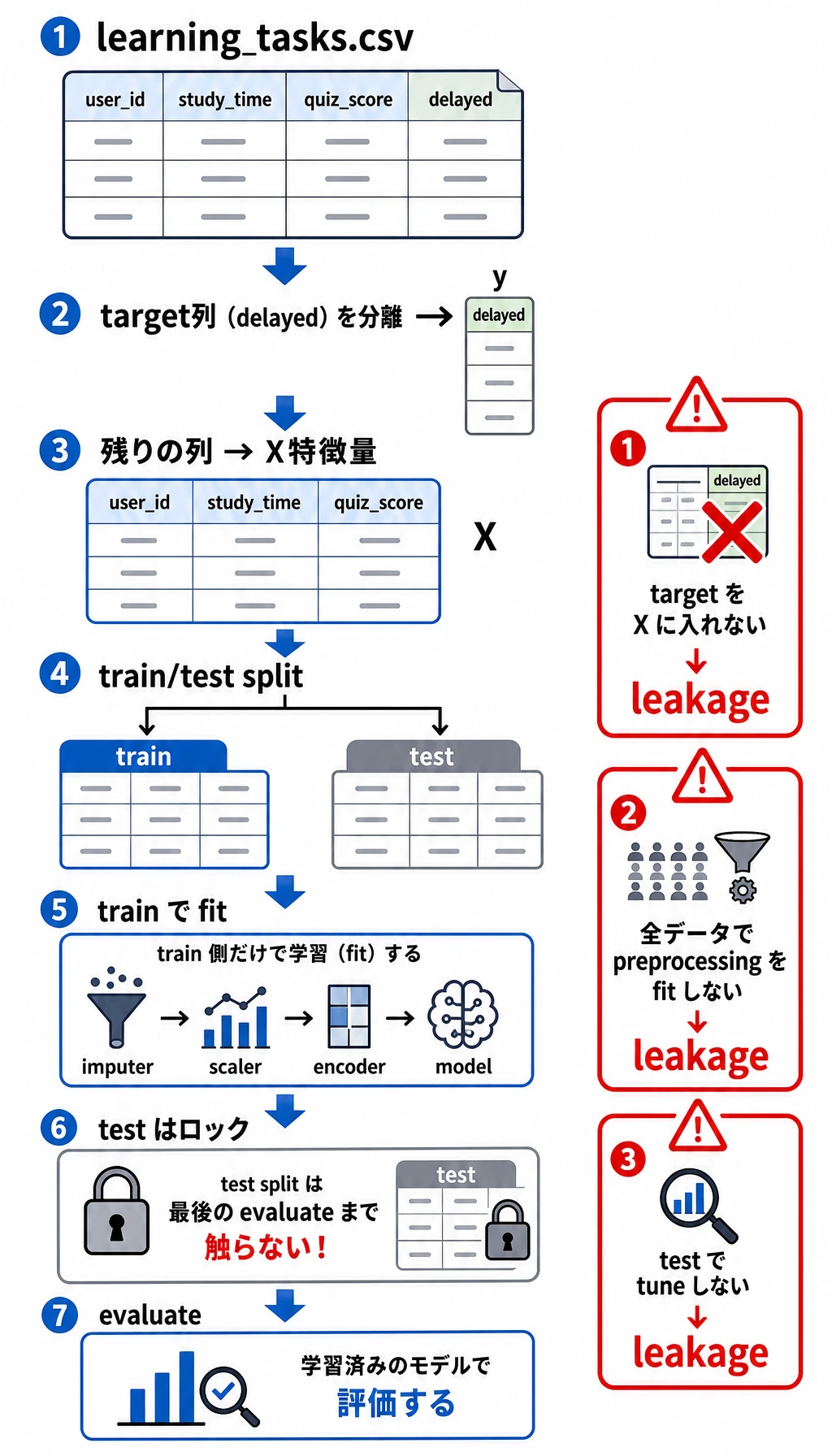
スクリプトを動かす前に、この図を見てください。目的変数 delayed はモデルが学ぶ答えなので、X に入れてはいけません。訓練データでは前処理パラメータとモデルパラメータを学び、テストデータは最後の確認まで取っておきます。この役割を混ぜると、スコアはよく見えてもプロジェクトとしては壊れています。
証拠の流れ:データからレポートへ
Section titled “証拠の流れ:データからレポートへ”
初心者がよくやる失敗は、ここで止まってしまうことです。
model.fit(...)print(score)これは本物の機械学習プロジェクトとしては足りません。次のような証拠を残す必要があります。
- どのデータを使ったのか?
- ベースラインは何か?
- どのモデルがベースラインを上回ったのか?
- どの指標を重視するのか?
- モデルはどこで失敗したのか?
- 他の人はどうやって再実行できるのか?
下のスクリプトは、この証拠パックを生成します。
| 領域 | ファイル |
|---|---|
| データ | data/learning_tasks.csv、data/schema.json |
| モデル出力 | outputs/model_comparison.csv、best_model_metrics.json、classification_report.txt |
| レビュー出力 | outputs/threshold_review.csv、error_samples.csv |
| レポート | reports/leakage_check.md、experiment_log.md |
| 再実行ガイド | README.md |
実行前に用語を確認する
Section titled “実行前に用語を確認する”- ベースライン:最初に作る最も単純なモデル。最低限超えるべき基準を示します。
- F1:precision と recall のバランスを取る指標。正例が重要で、クラスが完全に均衡していないときに役立ちます。
- Recall:本当に遅延した学習者のうち、モデルがどれだけ見つけられたか。
- Precision:遅延リスクありと判定された学習者のうち、実際にどれだけ遅延したか。
- AUC:複数のしきい値にまたがって、正例を負例より前に順位付けできる力。
- Pipeline:前処理とモデル学習を 1 つの安全なワークフローとして実行する scikit-learn オブジェクト。
- Data leakage(データリーク):予測時には本来使えない情報を、モデルが誤って学習してしまうこと。
環境を準備する
Section titled “環境を準備する”このコースリポジトリ内で作業している場合は、第 1〜5 章の実行環境をインストールします。
python -m pip install -r requirements-course-core.txt別フォルダで練習している場合は、必要なパッケージを直接インストールします。
python -m pip install numpy pandas scikit-learnこのワークショップでは、Pipeline、ColumnTransformer、OneHotEncoder、DummyClassifier、LogisticRegression、RandomForestClassifier など、安定した scikit-learn API を使います。ローカルでは Python 3.13、NumPy 2.4、pandas 3.0、scikit-learn 1.8 で確認済みです。
完全なワークショップを実行する
Section titled “完全なワークショップを実行する”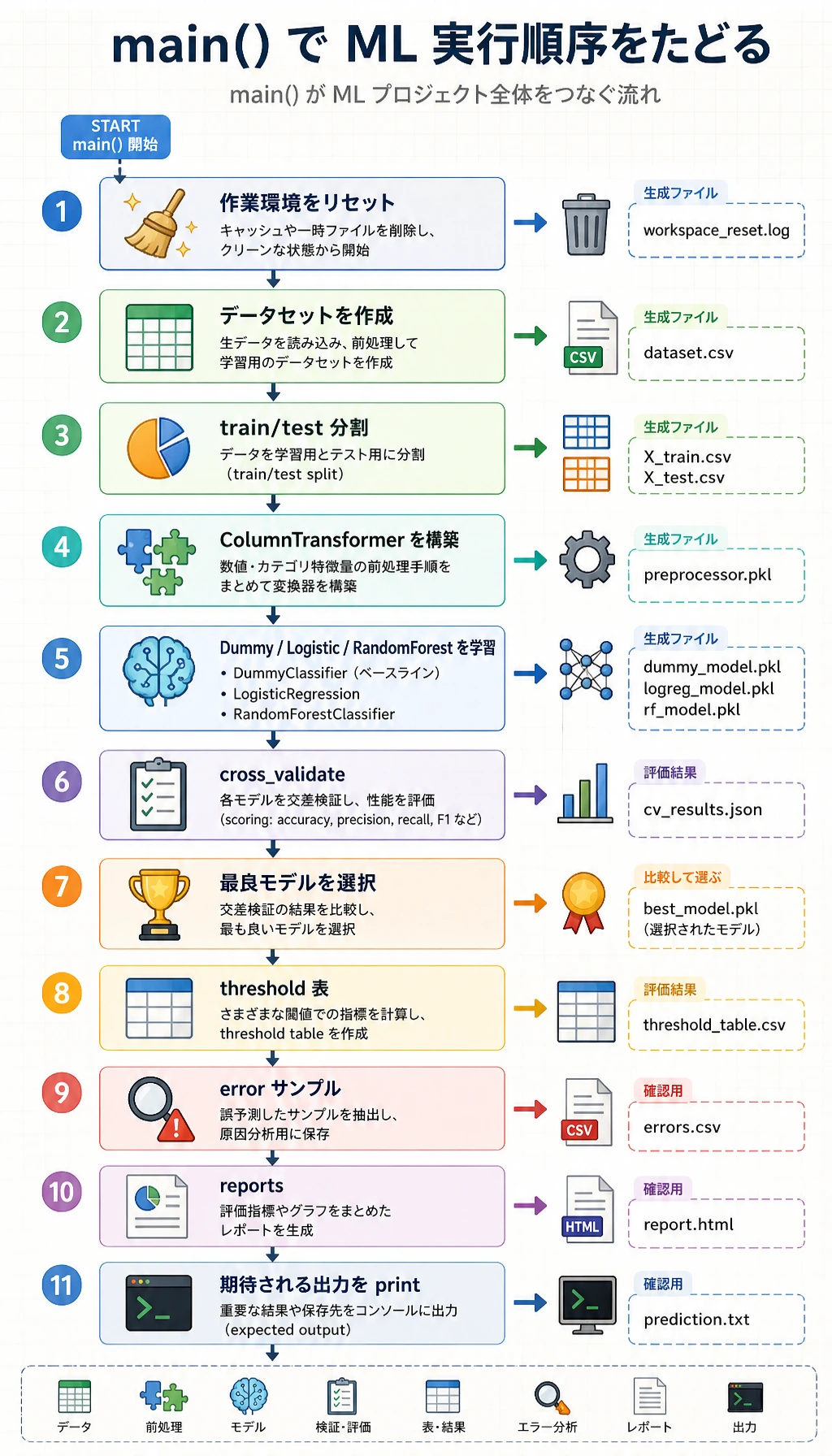
進め方はシンプルです。クリーンなフォルダを作り、1 本のスクリプトをコピーし、まず 1 回だけ実行し、その後で生成された証拠を読みます。最初からモデルをいじらないでください。初回実行が比較の基準になります。
クリーンなフォルダを作る
Section titled “クリーンなフォルダを作る”mkdir ch05-ml-workshopcd ch05-ml-workshopml_workshop.py を作る
Section titled “ml_workshop.py を作る”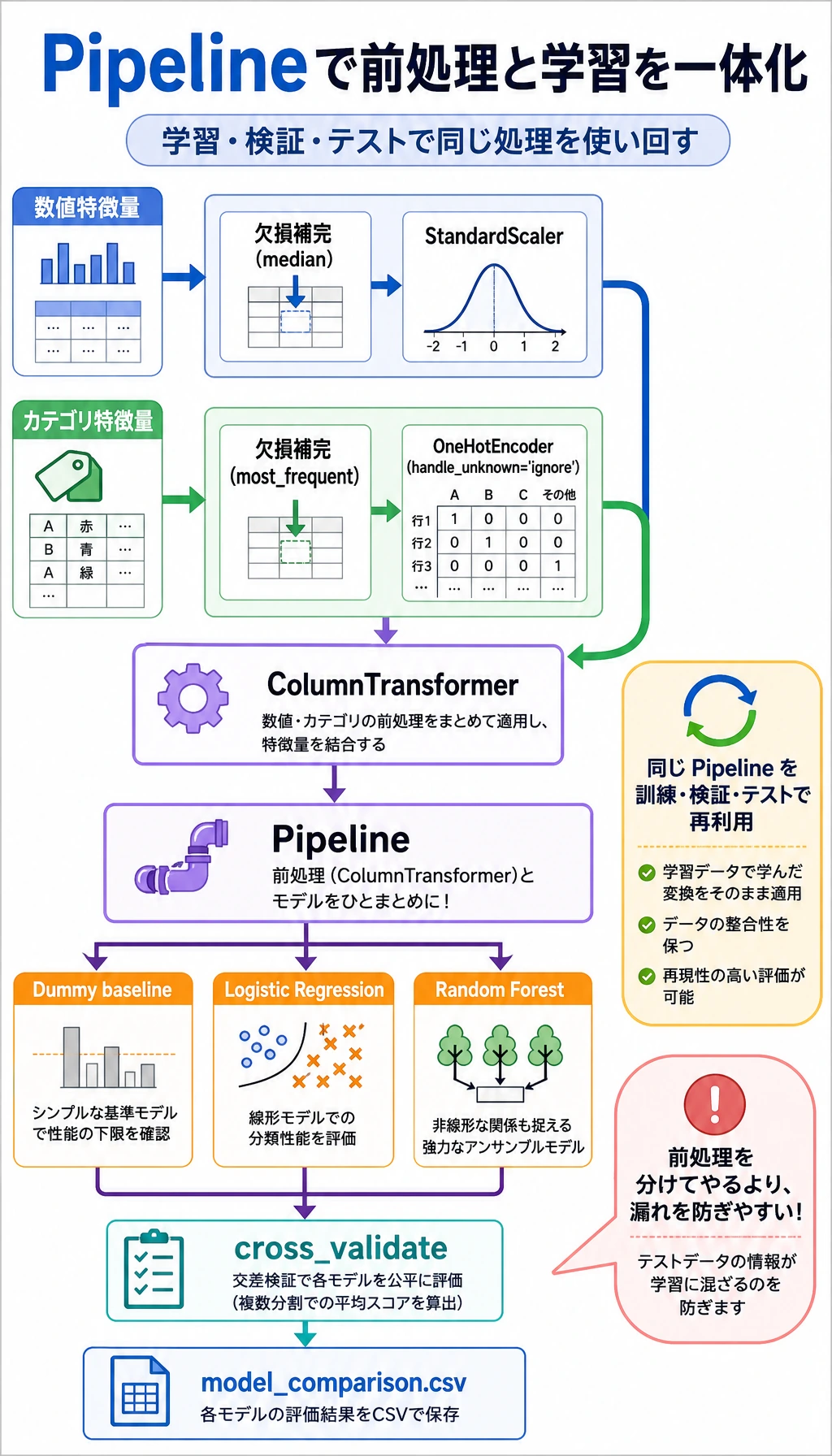
次のコードを ml_workshop.py に保存します。
from __future__ import annotations
import jsonimport shutilfrom pathlib import Path
import numpy as npimport pandas as pdfrom sklearn.compose import ColumnTransformerfrom sklearn.dummy import DummyClassifierfrom sklearn.ensemble import RandomForestClassifierfrom sklearn.impute import SimpleImputerfrom sklearn.linear_model import LogisticRegressionfrom sklearn.metrics import ( accuracy_score, classification_report, confusion_matrix, f1_score, precision_score, recall_score, roc_auc_score,)from sklearn.model_selection import StratifiedKFold, cross_validate, train_test_splitfrom sklearn.pipeline import Pipelinefrom sklearn.preprocessing import OneHotEncoder, StandardScaler
RUN_DIR = Path("ml_workshop_run")DATA_DIR = RUN_DIR / "data"OUTPUT_DIR = RUN_DIR / "outputs"REPORT_DIR = RUN_DIR / "reports"
NUMERIC_FEATURES = [ "hours_practiced", "quiz_score", "forum_questions", "previous_stage_days",]CATEGORICAL_FEATURES = ["track", "study_mode"]TARGET = "delayed"
def reset_workspace() -> None: if RUN_DIR.exists(): shutil.rmtree(RUN_DIR) for folder in (DATA_DIR, OUTPUT_DIR, REPORT_DIR): folder.mkdir(parents=True, exist_ok=True)
def write_json(path: Path, payload) -> None: path.write_text(json.dumps(payload, indent=2, ensure_ascii=False), encoding="utf-8")
def make_learning_dataset(seed: int = 42) -> pd.DataFrame: rng = np.random.default_rng(seed) rows = 240 hours = rng.normal(7.5, 2.2, rows).clip(1, 14) quiz = rng.normal(72, 13, rows).clip(25, 100) questions = rng.poisson(2.5, rows) previous_days = rng.normal(9, 3.5, rows).clip(2, 24) track = rng.choice(["data", "app", "model"], rows, p=[0.38, 0.34, 0.28]) study_mode = rng.choice(["solo", "group", "mentor"], rows, p=[0.45, 0.35, 0.20])
track_risk = np.select([track == "model", track == "app", track == "data"], [0.55, 0.20, 0.05]) mode_bonus = np.select([study_mode == "mentor", study_mode == "group", study_mode == "solo"], [-0.45, -0.18, 0.15]) raw_score = ( 1.3 - 0.22 * hours - 0.035 * quiz + 0.16 * questions + 0.14 * previous_days + track_risk + mode_bonus + rng.normal(0, 0.55, rows) ) probability = 1 / (1 + np.exp(-raw_score)) delayed = (probability >= 0.38).astype(int)
df = pd.DataFrame( { "hours_practiced": hours.round(1), "quiz_score": quiz.round(1), "forum_questions": questions, "previous_stage_days": previous_days.round(1), "track": track, "study_mode": study_mode, TARGET: delayed, } )
missing_hours = rng.choice(df.index, size=10, replace=False) missing_track = rng.choice(df.index, size=8, replace=False) df.loc[missing_hours, "hours_practiced"] = np.nan df.loc[missing_track, "track"] = np.nan return df
def build_preprocessor() -> ColumnTransformer: numeric_pipe = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()), ] ) categorical_pipe = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="most_frequent")), ("onehot", OneHotEncoder(handle_unknown="ignore", sparse_output=False)), ] ) return ColumnTransformer( transformers=[ ("num", numeric_pipe, NUMERIC_FEATURES), ("cat", categorical_pipe, CATEGORICAL_FEATURES), ] )
def make_models() -> dict[str, Pipeline]: return { "Dummy baseline": Pipeline( steps=[ ("preprocess", build_preprocessor()), ("model", DummyClassifier(strategy="most_frequent")), ] ), "Logistic Regression": Pipeline( steps=[ ("preprocess", build_preprocessor()), ("model", LogisticRegression(max_iter=1000, class_weight="balanced")), ] ), "Random Forest": Pipeline( steps=[ ("preprocess", build_preprocessor()), ("model", RandomForestClassifier(n_estimators=160, max_depth=5, random_state=42, class_weight="balanced")), ] ), }
def evaluate_models(models, X_train, y_train, X_test, y_test) -> pd.DataFrame: cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) rows = [] for name, model in models.items(): cv_scores = cross_validate( model, X_train, y_train, cv=cv, scoring={"f1": "f1", "roc_auc": "roc_auc", "recall": "recall"}, n_jobs=None, ) model.fit(X_train, y_train) predictions = model.predict(X_test) probabilities = model.predict_proba(X_test)[:, 1] rows.append( { "model": name, "cv_f1_mean": round(float(cv_scores["test_f1"].mean()), 3), "cv_auc_mean": round(float(cv_scores["test_roc_auc"].mean()), 3), "test_accuracy": round(accuracy_score(y_test, predictions), 3), "test_precision": round(precision_score(y_test, predictions, zero_division=0), 3), "test_recall": round(recall_score(y_test, predictions, zero_division=0), 3), "test_f1": round(f1_score(y_test, predictions, zero_division=0), 3), "test_auc": round(roc_auc_score(y_test, probabilities), 3), } ) return pd.DataFrame(rows).sort_values(["test_f1", "test_auc"], ascending=False)
def threshold_table(model: Pipeline, X_test: pd.DataFrame, y_test: pd.Series) -> pd.DataFrame: probabilities = model.predict_proba(X_test)[:, 1] rows = [] for threshold in [0.30, 0.40, 0.50, 0.60, 0.70]: pred = (probabilities >= threshold).astype(int) rows.append( { "threshold": threshold, "precision": round(precision_score(y_test, pred, zero_division=0), 3), "recall": round(recall_score(y_test, pred, zero_division=0), 3), "f1": round(f1_score(y_test, pred, zero_division=0), 3), "flagged_students": int(pred.sum()), } ) return pd.DataFrame(rows)
def save_error_samples(model: Pipeline, X_test: pd.DataFrame, y_test: pd.Series) -> pd.DataFrame: probabilities = model.predict_proba(X_test)[:, 1] predictions = (probabilities >= 0.5).astype(int) errors = X_test.copy() errors["actual_delayed"] = y_test.to_numpy() errors["predicted_delayed"] = predictions errors["delay_probability"] = probabilities.round(3) errors = errors[errors["actual_delayed"] != errors["predicted_delayed"]] return errors.sort_values("delay_probability", ascending=False).head(8)
def write_markdown_report(path: Path, title: str, lines: list[str]) -> None: path.write_text("# " + title + "\n\n" + "\n".join(lines) + "\n", encoding="utf-8")
def main() -> None: reset_workspace() df = make_learning_dataset() df.to_csv(DATA_DIR / "learning_tasks.csv", index=False) write_json( DATA_DIR / "schema.json", { "target": TARGET, "numeric_features": NUMERIC_FEATURES, "categorical_features": CATEGORICAL_FEATURES, "meaning": "Predict whether a learner is likely to delay the next task.", }, )
X = df[NUMERIC_FEATURES + CATEGORICAL_FEATURES] y = df[TARGET] X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y, )
models = make_models() metrics = evaluate_models(models, X_train, y_train, X_test, y_test) metrics.to_csv(OUTPUT_DIR / "model_comparison.csv", index=False)
best_name = str(metrics.iloc[0]["model"]) best_model = models[best_name] best_model.fit(X_train, y_train)
best_predictions = best_model.predict(X_test) best_probabilities = best_model.predict_proba(X_test)[:, 1] write_json( OUTPUT_DIR / "best_model_metrics.json", { "best_model": best_name, "accuracy": round(accuracy_score(y_test, best_predictions), 3), "precision": round(precision_score(y_test, best_predictions, zero_division=0), 3), "recall": round(recall_score(y_test, best_predictions, zero_division=0), 3), "f1": round(f1_score(y_test, best_predictions, zero_division=0), 3), "auc": round(roc_auc_score(y_test, best_probabilities), 3), "confusion_matrix": confusion_matrix(y_test, best_predictions).tolist(), }, )
threshold_results = threshold_table(best_model, X_test, y_test) threshold_results.to_csv(OUTPUT_DIR / "threshold_review.csv", index=False)
errors = save_error_samples(best_model, X_test, y_test) errors.to_csv(OUTPUT_DIR / "error_samples.csv", index=False)
report_text = classification_report(y_test, best_predictions, zero_division=0) (OUTPUT_DIR / "classification_report.txt").write_text(report_text, encoding="utf-8")
write_markdown_report( REPORT_DIR / "leakage_check.md", "リーク確認", [ "- 補完器、スケーラー、エンコーダー、モデルを fit する前にデータを分割する。", "- 目的変数の列を特徴量リストに入れない。", "- 前処理は ColumnTransformer と Pipeline の中に入れる。", "- 学習側の分割で交差検証し、テスト分割は一度だけ確認する。", ], ) write_markdown_report( REPORT_DIR / "experiment_log.md", "実験ログ", [ "| 版 | 変更 | 主な結果 | 次のステップ |", "|---|---|---|---|", f"| v0 | Dummy baseline | f1={metrics[metrics['model'] == 'Dummy baseline'].iloc[0]['test_f1']} | 実モデルが必要 |", f"| v1 | {best_name} + Pipeline | f1={metrics.iloc[0]['test_f1']} | しきい値とエラーを確認 |", ], )
readme_lines = [ "# 機械学習ワークショップ証拠パック", "", "実行コマンド:", "", "```bash", "python ml_workshop.py", "```", "", "生成ファイル:", "- data/learning_tasks.csv", "- outputs/model_comparison.csv", "- outputs/best_model_metrics.json", "- outputs/threshold_review.csv", "- outputs/error_samples.csv", "- reports/leakage_check.md", "- reports/experiment_log.md", ] (RUN_DIR / "README.md").write_text("\n".join(readme_lines) + "\n", encoding="utf-8")
positive_rate = float(y.mean()) dummy_f1 = float(metrics[metrics["model"] == "Dummy baseline"].iloc[0]["test_f1"]) best_f1 = float(metrics.iloc[0]["test_f1"]) print("STEP 1: data prepared") print(f"rows: {len(df)}") print(f"features: {len(NUMERIC_FEATURES) + len(CATEGORICAL_FEATURES)}") print(f"positive_rate: {positive_rate:.3f}") print("STEP 2: baseline and model comparison") print(f"dummy_f1: {dummy_f1:.3f}") print(f"best_model: {best_name}") print(f"best_f1: {best_f1:.3f}") print("STEP 3: evidence files") print(RUN_DIR / "README.md") print(OUTPUT_DIR / "model_comparison.csv") print(OUTPUT_DIR / "error_samples.csv") print(REPORT_DIR / "leakage_check.md")
if __name__ == "__main__": main()python ml_workshop.py期待される出力は次のようになります。
STEP 1: data preparedrows: 240features: 6positive_rate: 0.287STEP 2: baseline and model comparisondummy_f1: 0.000best_model: Logistic Regressionbest_f1: 0.821STEP 3: evidence filesml_workshop_run/README.mdml_workshop_run/outputs/model_comparison.csvml_workshop_run/outputs/error_samples.csvml_workshop_run/reports/leakage_check.md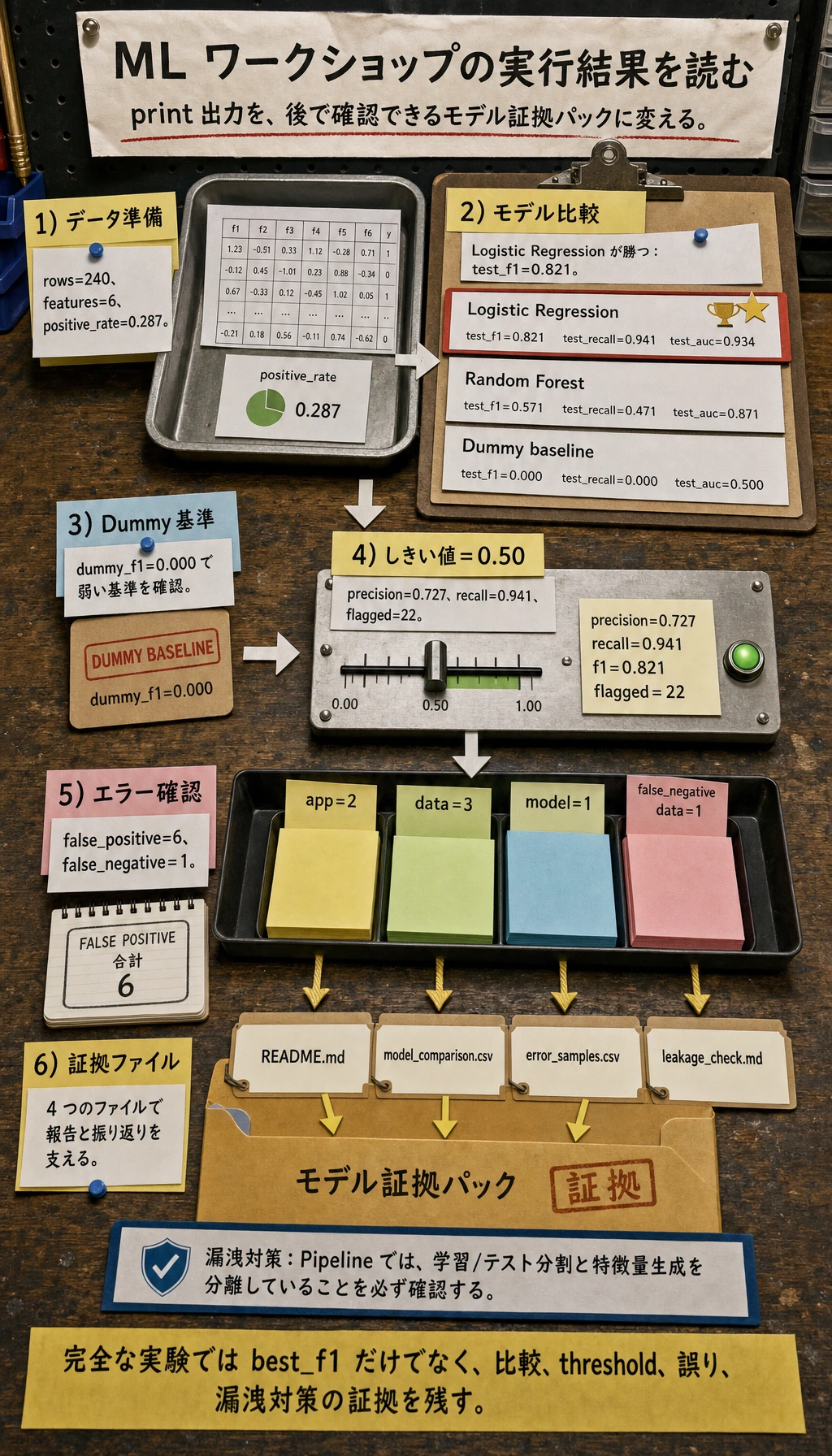
生成された証拠ファイルを確認する
Section titled “生成された証拠ファイルを確認する”スコアを読む前に、まず証拠ファイルが実際に作られているか確認します。
find ml_workshop_run -maxdepth 2 -type f | sort期待される出力:
ml_workshop_run/README.mdml_workshop_run/data/learning_tasks.csvml_workshop_run/data/schema.jsonml_workshop_run/outputs/best_model_metrics.jsonml_workshop_run/outputs/classification_report.txtml_workshop_run/outputs/error_samples.csvml_workshop_run/outputs/model_comparison.csvml_workshop_run/outputs/threshold_review.csvml_workshop_run/reports/experiment_log.mdml_workshop_run/reports/leakage_check.md出力を順番に読む
Section titled “出力を順番に読む”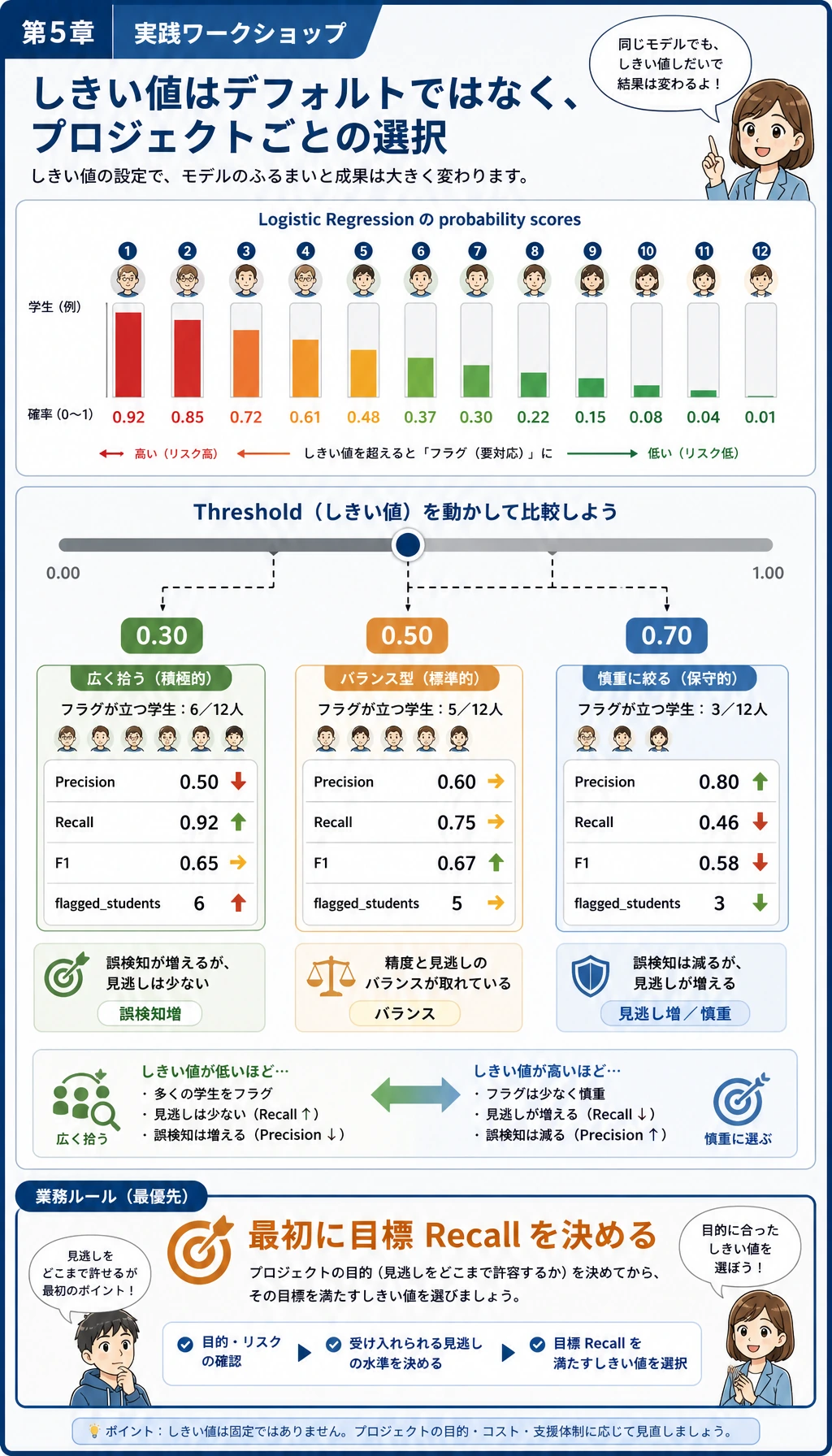
baseline から見る
Section titled “baseline から見る”ml_workshop_run/outputs/model_comparison.csv を開きます。
Dummy baseline は多くの場合 f1 = 0 になります。これは失敗ではありません。これは床です。実モデルがこの床を超えられないなら、データ、特徴量設計、指標、またはタスク定義がまだ準備できていません。
生の CSV を眺めて推測する代わりに、次の小さな読み取りコマンドを使います。
python - <<'PY'import pandas as pd
comparison = pd.read_csv("ml_workshop_run/outputs/model_comparison.csv")print(comparison[["model", "test_f1", "test_recall", "test_auc"]].to_string(index=False))PY期待される出力:
model test_f1 test_recall test_aucLogistic Regression 0.821 0.941 0.934 Random Forest 0.571 0.471 0.871 Dummy baseline 0.000 0.000 0.500実モデルを確認する
Section titled “実モデルを確認する”期待される最良モデルは Logistic Regression です。初心者にとって良い結果です。理由は次の通りです。
- 説明しやすい
- 学習が速い
- 最初の表形式 baseline として十分に強い
- スケーリング済み数値特徴量と one-hot カテゴリ特徴量に合う
Random Forest の方が強そうに聞こえるからといって、すぐ飛びつかないでください。第 5 章で身につける最初の習慣は、まず単純な baseline、次に強いモデル です。
しきい値を見る
Section titled “しきい値を見る”ml_workshop_run/outputs/threshold_review.csv を開きます。
遅延リスクモデルでは、precision より recall が重要になることがあります。目的が学習者を早めに助けることなら、高リスクの学習者を見逃す方が、追加のリマインドを数件送るより高くつくかもしれません。つまり、しきい値はモデルのデフォルトではなく、プロジェクト上の判断です。
次の小さな判断ヘルパーを実行します。recall が 0.90 以上の行から F1 が最もよいものを選び、トレードオフを普通の文章に近い形で表示します。
python - <<'PY'import pandas as pd
thresholds = pd.read_csv("ml_workshop_run/outputs/threshold_review.csv")choice = thresholds[thresholds["recall"] >= 0.90].sort_values( ["f1", "precision"], ascending=False,).iloc[0]
print(f"chosen_threshold={choice.threshold:.2f}")print( f"precision={choice.precision:.3f} " f"recall={choice.recall:.3f} " f"f1={choice.f1:.3f} " f"flagged={int(choice.flagged_students)}")PY期待される出力:
chosen_threshold=0.50precision=0.727 recall=0.941 f1=0.821 flagged=22業務目標が変われば、このルールも変えます。低コストのリマインドなら recall >= 0.80 で十分かもしれません。一方、医療や安全に関わるワークフローなら、より厳しい recall 目標と人間による確認が必要になります。
エラーを確認する
Section titled “エラーを確認する”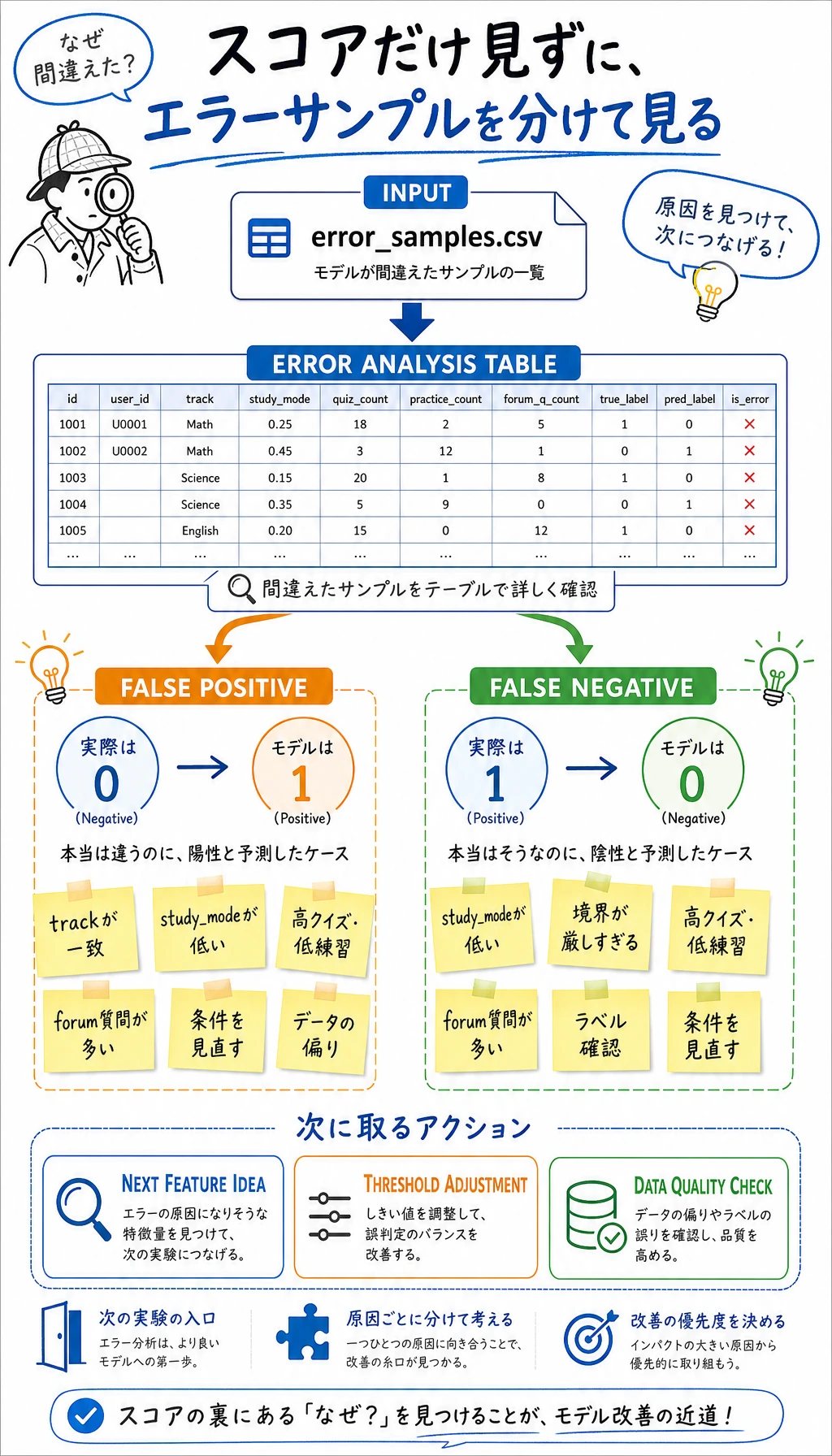
ml_workshop_run/outputs/error_samples.csv を開きます。
次のように問いかけます。
- false negative は、クイズ点数は高いが練習時間が少ない学習者か?
- false positive は、特定のトラックや学習モードに偏っているか?
- 特徴量は遅延の本当の理由を表しているか、それとも重要なシグナルが抜けているか?
エラー分析によって、プロジェクトは「スコア」から「調査」に変わります。
もう 1 つ小さな読み取りコマンドを使い、誤予測をバケットに分けます。
python - <<'PY'import pandas as pd
errors = pd.read_csv("ml_workshop_run/outputs/error_samples.csv")errors["error_type"] = errors.apply( lambda row: "false_negative" if row.actual_delayed == 1 else "false_positive", axis=1,)
print(errors["error_type"].value_counts().to_string())print("--- by track ---")print(errors.groupby(["error_type", "track"]).size().to_string())PY期待される出力:
error_typefalse_positive 6false_negative 1--- by track ---error_type trackfalse_negative data 1false_positive app 2 data 3 model 1これは責任探しではなく、次の作業リストとして読みます。false positive はモデルが慎重すぎるサインかもしれません。学習者を早めに助けることが目的なら、false negative はより優先して確認したい失敗です。
リーク確認を読む
Section titled “リーク確認を読む”ml_workshop_run/reports/leakage_check.md を開きます。
最も大事な一文はこれです。
まず分割し、その後で前処理を学習ワークフローの中だけで fit する。
この例で ColumnTransformer を Pipeline の中に入れている理由はここにあります。
このページを終えたら、この evidence card を残します。
- プロジェクト目標
- 予測、セグメンテーション、Kaggle、またはエンドツーエンドの ML ポートフォリオ対象
- パイプライン
- データ分割、前処理、モデル、評価、レポート成果物
- 結果
- metric 表、chart、予測、失敗サンプル、README の注記
- 失敗確認
- 再現不可能な実行、リーク、過学習、弱いベースライン、またはデプロイ境界の不足
- 期待される成果
- パイプライン、メトリクス、失敗レビューを含む ML プロジェクトフォルダ
よくあるエラーとデバッグループ
Section titled “よくあるエラーとデバッグループ”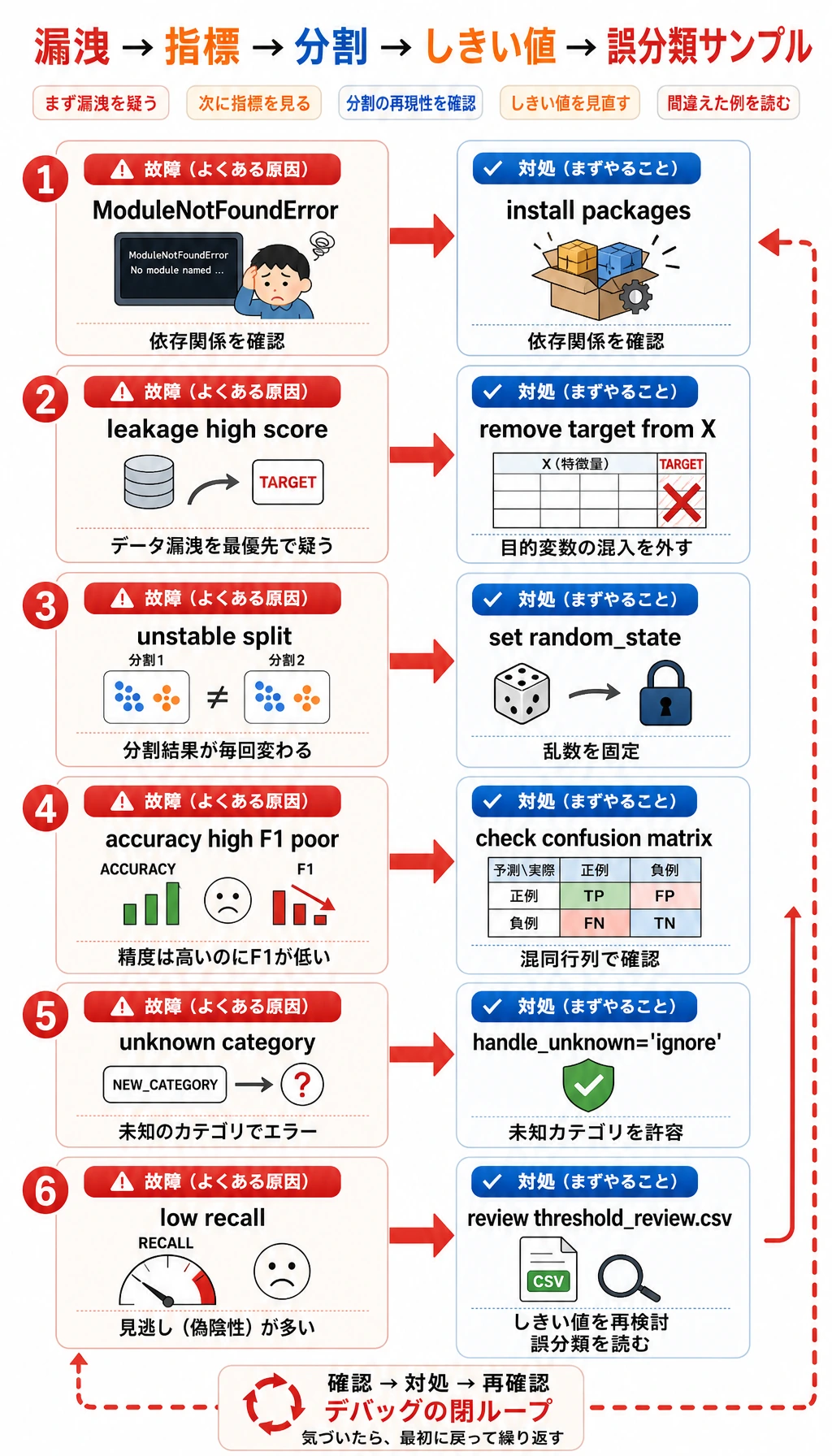
| 症状 | よくある原因 | 対処 |
|---|---|---|
ModuleNotFoundError: No module named 'sklearn' | コース実行環境が入っていない | python -m pip install -r requirements-course-core.txt を実行するか、numpy pandas scikit-learn を入れる |
| スコアが不自然に高い | target leakage または分割の誤り | 特徴量リストを確認し、delayed が X に入っていないことを確認する |
| 実行のたびにテスト F1 が変わる | 乱数 seed または split が固定されていない | 学習中は random_state=42 を維持する |
| accuracy は高いが F1 が低い | クラス不均衡 | precision、recall、F1、混同行列を比較する |
| Pipeline がカテゴリ値で失敗する | テストデータに新しいカテゴリが出た | OneHotEncoder(handle_unknown="ignore") を使う |
| 正例をほとんど拾えない | しきい値が高すぎる | threshold_review.csv を見て、recall を重視するならしきい値を下げる |
作品集プロジェクトに発展させる
Section titled “作品集プロジェクトに発展させる”
小さなステップでこのワークショップを発展させましょう。
- 合成データセットを自分のプロジェクトの CSV に置き換える。
- 乱数 seed、テストサイズ、モデル一覧を管理する
config.jsonを追加する。 - もう 1 つモデルを追加する。ただし Dummy baseline は残す。
- 混同行列の図、またはしきい値曲線を追加する。
- 上位 3 つのエラーパターンを 1 段落で説明する。
README.mdに「次に改善すること」を追加する。
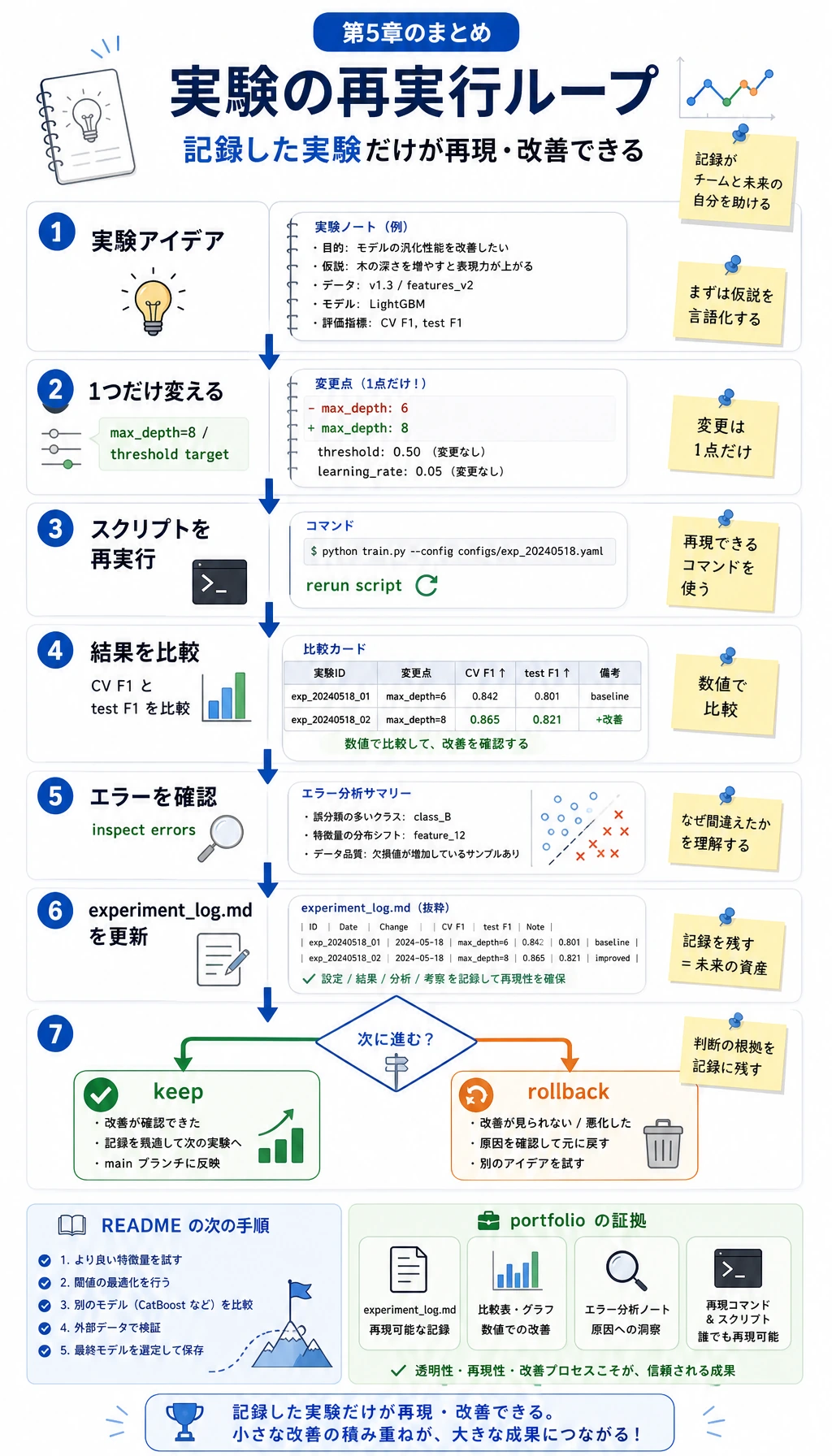
このページを離れる前に、小さな 1 回の反復を行います。まず実験メモを 1 行追加し、その後でランダムフォレストの max_depth=8 のように、ちょうど 1 つだけ変更して再実行します。
python - <<'PY'from pathlib import Path
log_path = Path("ml_workshop_run/reports/experiment_log.md")log = log_path.read_text(encoding="utf-8")log += "\n| v2 | Try RandomForest max_depth=8 | Compare CV F1 and test F1 after rerun | Keep only if both stay stable |\n"log_path.write_text(log, encoding="utf-8")print(log_path.read_text(encoding="utf-8"))PY期待される出力には次の行が含まれます。
| v2 | Try RandomForest max_depth=8 | Compare CV F1 and test F1 after rerun | Keep only if both stay stable |第 5 章で身につけたいのはこの習慣です。変数を 1 つだけ変え、再実行し、証拠を比較して、残すかどうかを決める。なんとなく試すだけではまだモデリング練習ではありません。記録された実験になって初めて、次に進める材料になります。
作品集チェックリスト
Section titled “作品集チェックリスト”第 5 章のプロジェクトを完了したと言う前に、次が揃っているか確認してください。
- クリーンなフォルダから動く実行コマンド
- baseline 指標
- 実モデルの指標
- モデル比較表
- リーク確認
- しきい値または指標の説明
- エラーサンプル
- 次の改善を含む README
プロジェクト参考とレビュー観点
- クリーンなフォルダから動く実行コマンドがあると、隠れた Notebook 状態に依存せず出力を再生成できます。
- baseline 指標と実モデル指標は、同じ split と同じ指標を使って 1 つの比較表に置きます。
- leakage check では、目的変数由来の列が特徴量に入っていないこと、前処理が訓練 workflow の中で fit されていることを明記します。
- 指標やしきい値の説明はタスク目標と結びつけます。特に false negative と false positive のコストが違う場合は重要です。
- エラーサンプルは次の実験につながるべきです。特徴量修正、ラベル確認、セグメント分析、しきい値調整などが候補です。
- README が、何を試し、何が改善し、どこで失敗し、次に何をするかを説明できれば、ポートフォリオに近づきます。
このワークショップは、第 5 章の流れを 1 つのファイルにまとめたものです。データ、baseline、Pipeline、モデル比較、しきい値確認、エラー分析、リーク確認、README 証拠を一通り作ります。再実行でき、各出力ファイルを説明できるなら、あなたは機械学習 API を学んでいるだけではありません。本物のモデリングワークフローを練習しています。