6.2.9 PyTorch + Matplotlib 実践ワークショップ
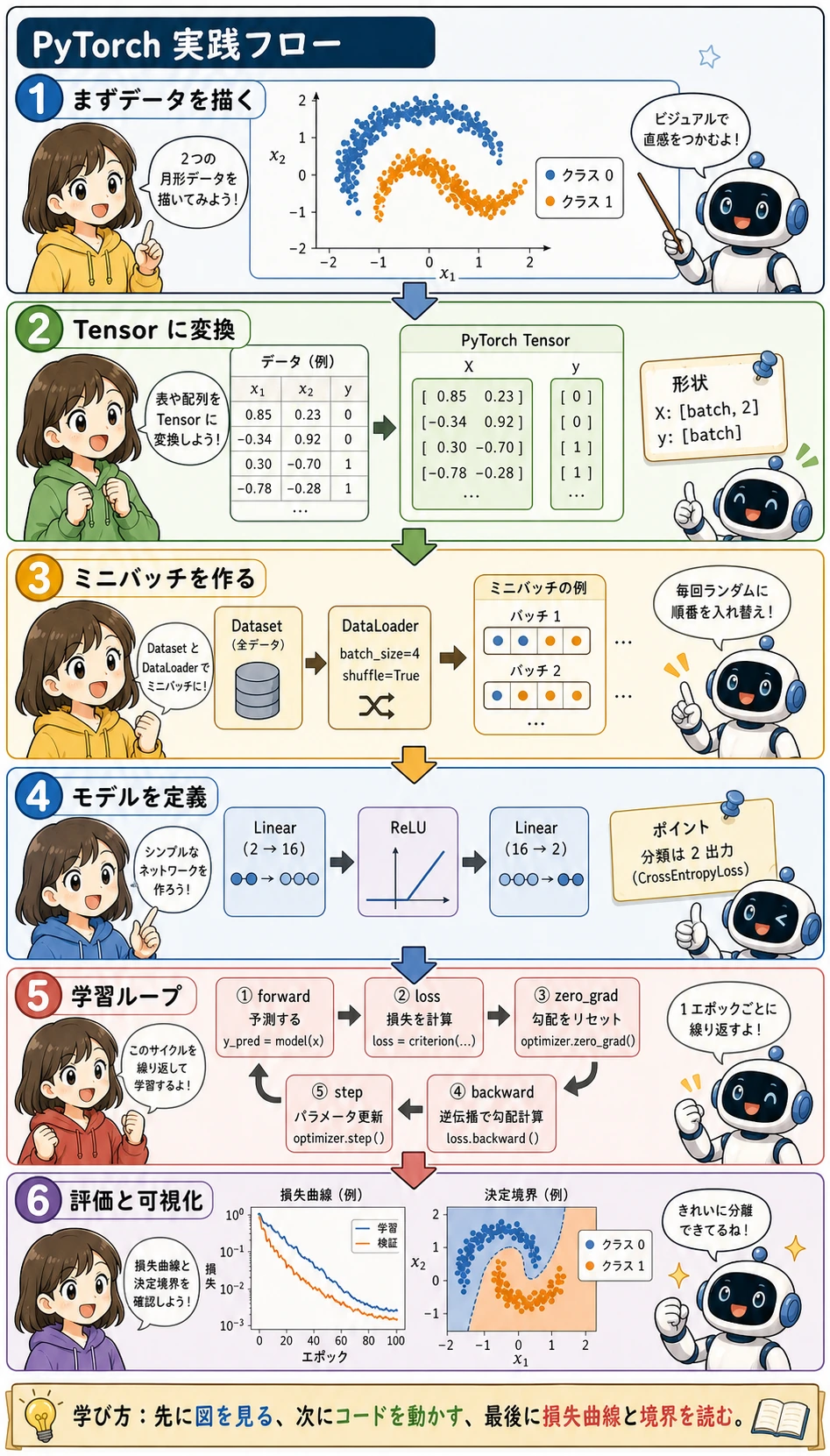
この節で作るもの
Section titled “この節で作るもの”小さなニューラルネットワークを訓練して、2 つの月形の点群を分類します。小さくてすぐ動きますが、PyTorch の基本ワークフローが一通り入っています。
- Matplotlib でデータを可視化する
- NumPy 配列を PyTorch Tensor に変換する
TensorDatasetとDataLoaderを作るnn.Moduleを定義するCrossEntropyLossとAdamで訓練する- accuracy を評価する
- 損失曲線と決定境界を描く
キーワード整理
Section titled “キーワード整理”| 用語 | 初学者向けの意味 | ここで重要な理由 |
|---|---|---|
| Matplotlib | Python の基本的な描画ライブラリ | データ、損失曲線、決定境界を見るために使う |
| Tensor | PyTorch の多次元配列 | モデルは Tensor データで訓練する |
Dataset | 1 つのサンプルが何かを定義するもの | データとラベルの対応を保つ |
DataLoader | サンプルをミニバッチにするもの | 学習ループへバッチ単位で渡す |
| MLP | Multilayer Perceptron。小さな全結合ニューラルネットワーク | 最初の 2D や表形式タスクに向いている |
| logits | 確率に変換する前のモデルの生スコア | CrossEntropyLoss は softmax 後ではなく logits を受け取る |
| epoch | 訓練データを 1 周見ること | 学習が何周進んだかを数える |
| 決定境界 | モデルがクラスを切り替える境目 | 分類のふるまいを直感的に見られる |
まずデータを作って描く
Section titled “まずデータを作って描く”モデルを書く前に、必ずデータを見ます。これは、モデルが何を学ぶべきか分からないまま訓練する、という初学者によくある失敗を防ぎます。
import matplotlib.pyplot as pltfrom sklearn.datasets import make_moons
X_np, y_np = make_moons(n_samples=600, noise=0.18, random_state=42)
plt.figure(figsize=(6, 5))plt.scatter(X_np[:, 0], X_np[:, 1], c=y_np, cmap="coolwarm", s=18, alpha=0.8)plt.xlabel("x1")plt.ylabel("x2")plt.title("Two Moons Dataset")plt.grid(True, alpha=0.3)plt.show()見るべきポイント:
- 2 クラスは直線では分けにくい
- そのため、非線形を持つ小さなニューラルネットワークが役立つ
- この図は、後で決定境界を見るときの基準になる
Tensor に変換する
Section titled “Tensor に変換する”PyTorch モデルは Tensor を受け取ります。CrossEntropyLoss に使う分類ラベルは、整数クラス ID で、型は torch.long にします。
import torch
torch.manual_seed(42)
X = torch.tensor(X_np, dtype=torch.float32)y = torch.tensor(y_np, dtype=torch.long)
print("X shape:", X.shape, "dtype:", X.dtype)print("y shape:", y.shape, "dtype:", y.dtype)出力例:
X shape: torch.Size([600, 2]) dtype: torch.float32y shape: torch.Size([600]) dtype: torch.int64shape の意味:
X:[batch, features]。各サンプルは 2 つの特徴量を持つy:[batch]。各値は0または1のクラスラベル
Dataset と DataLoader を作る
Section titled “Dataset と DataLoader を作る”TensorDataset は X と y の対応を保ちます。DataLoader はデータをシャッフルし、ミニバッチを作ります。
from torch.utils.data import DataLoader, TensorDataset, random_split
dataset = TensorDataset(X, y)train_dataset, val_dataset = random_split( dataset, [480, 120], generator=torch.Generator().manual_seed(42))
train_loader = DataLoader( train_dataset, batch_size=64, shuffle=True, generator=torch.Generator().manual_seed(7))val_loader = DataLoader(val_dataset, batch_size=128, shuffle=False)
batch_x, batch_y = next(iter(train_loader))print("batch_x shape:", batch_x.shape)print("batch_y shape:", batch_y.shape)期待される出力:
batch_x shape: torch.Size([64, 2])batch_y shape: torch.Size([64])なぜ重要か:
batch_size=64は、64 サンプルごとにモデルを更新するという意味shuffle=Trueは、毎回同じ順番で見ることを防ぐ- 検証データは評価だけに使うので、通常シャッフルしなくてよい
小さなニューラルネットワークを定義する
Section titled “小さなニューラルネットワークを定義する”このモデルは 2D の点を 2 つの logits に変換します。各クラスに 1 つのスコアがあります。
from torch import nn
class MoonClassifier(nn.Module): def __init__(self): super().__init__() self.net = nn.Sequential( nn.Linear(2, 32), nn.ReLU(), nn.Linear(32, 32), nn.ReLU(), nn.Linear(32, 2), )
def forward(self, x): return self.net(x)
model = MoonClassifier()print(model)期待される出力:
MoonClassifier( (net): Sequential( (0): Linear(in_features=2, out_features=32, bias=True) (1): ReLU() (2): Linear(in_features=32, out_features=32, bias=True) (3): ReLU() (4): Linear(in_features=32, out_features=2, bias=True) ))大切な点:
- 最後の層は
2個の値を出します。これは 2 クラス分類だからです - ここで
Softmaxは追加しません。nn.CrossEntropyLoss()は生の logits を受け取るためです
学習ループは前に学んだリズムと同じです。
forward → loss → zero_grad → backward → step
loss_fn = nn.CrossEntropyLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
train_losses = []val_losses = []val_accuracies = []
for epoch in range(1, 101): model.train() train_loss_sum = 0.0
for batch_x, batch_y in train_loader: logits = model(batch_x) loss = loss_fn(logits, batch_y)
optimizer.zero_grad() loss.backward() optimizer.step()
train_loss_sum += loss.item() * len(batch_x)
train_loss = train_loss_sum / len(train_dataset) train_losses.append(train_loss)
model.eval() val_loss_sum = 0.0 correct = 0
with torch.no_grad(): for batch_x, batch_y in val_loader: logits = model(batch_x) loss = loss_fn(logits, batch_y) val_loss_sum += loss.item() * len(batch_x)
pred = logits.argmax(dim=1) correct += (pred == batch_y).sum().item()
val_loss = val_loss_sum / len(val_dataset) val_acc = correct / len(val_dataset) val_losses.append(val_loss) val_accuracies.append(val_acc)
if epoch == 1 or epoch % 20 == 0: print( f"epoch={epoch:3d}, " f"train_loss={train_loss:.4f}, " f"val_loss={val_loss:.4f}, " f"val_acc={val_acc:.1%}" )期待される出力:
epoch= 1, train_loss=0.5568, val_loss=0.3786, val_acc=84.2%epoch= 20, train_loss=0.0755, val_loss=0.1064, val_acc=98.3%epoch= 40, train_loss=0.0719, val_loss=0.1260, val_acc=98.3%epoch= 60, train_loss=0.0657, val_loss=0.1290, val_acc=98.3%epoch= 80, train_loss=0.0655, val_loss=0.1415, val_acc=98.3%epoch=100, train_loss=0.0687, val_loss=0.1370, val_acc=98.3%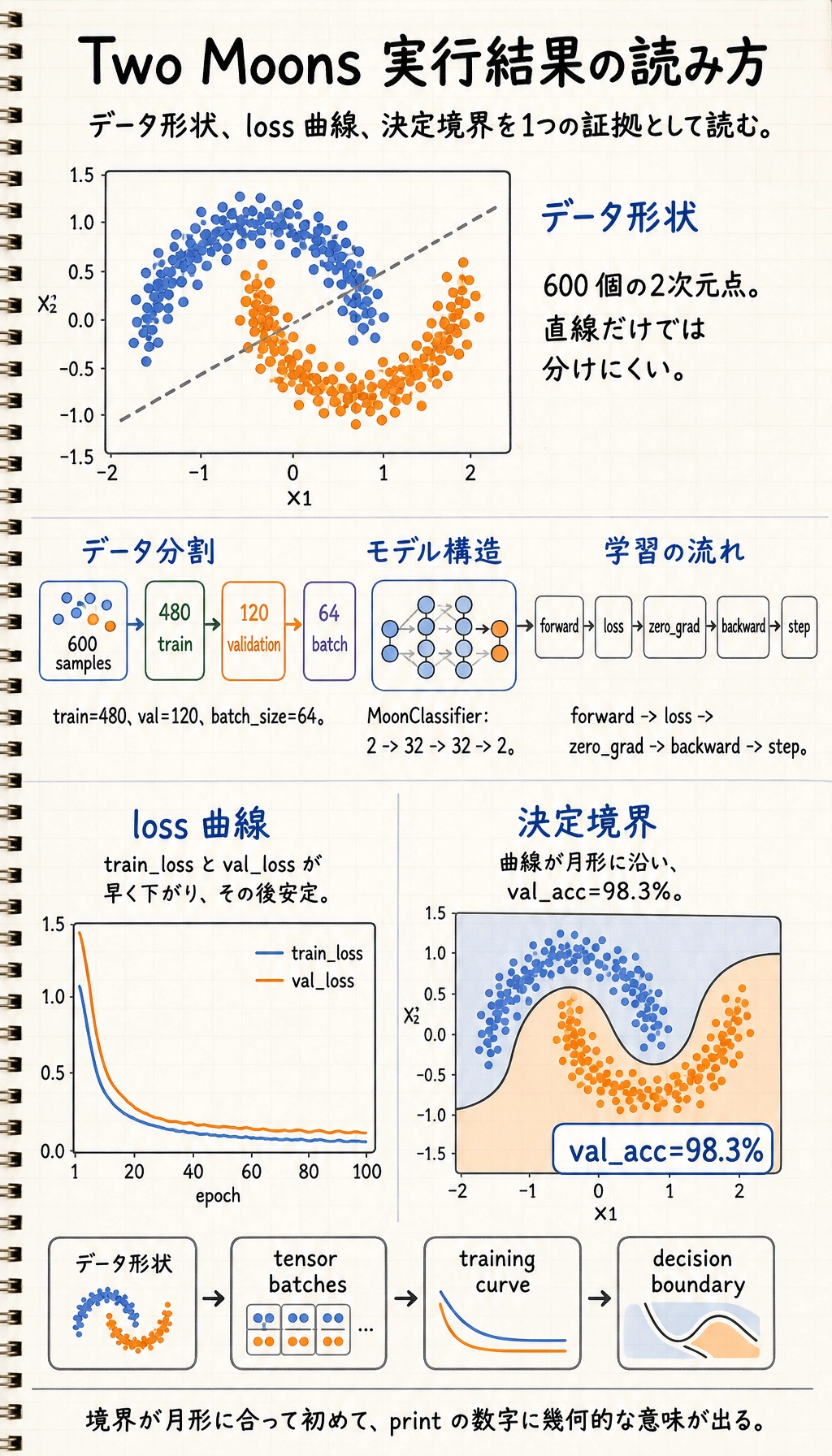
数値が少し違っても問題ありません。大事なのは、検証 accuracy がランダム予測より明らかに高くなることです。
損失曲線を描く
Section titled “損失曲線を描く”損失曲線は、学習が正しい方向に進んでいるかを見るためのものです。
plt.figure(figsize=(7, 4))plt.plot(train_losses, label="train loss")plt.plot(val_losses, label="validation loss")plt.xlabel("Epoch")plt.ylabel("Loss")plt.title("Training and Validation Loss")plt.legend()plt.grid(True, alpha=0.3)plt.show()読み方:
- 両方の loss が下がるなら、だいたい正常に学習している
- training loss は下がるのに validation loss が上がるなら、過学習に注意する
- どちらも下がらないなら、learning rate、ラベル、出力 shape、loss function を確認する
決定境界を描く
Section titled “決定境界を描く”決定境界は、モデルが学んだ分類ルールを幾何的に見せてくれます。
import numpy as np
x_min, x_max = X_np[:, 0].min() - 0.5, X_np[:, 0].max() + 0.5y_min, y_max = X_np[:, 1].min() - 0.5, X_np[:, 1].max() + 0.5xx, yy = np.meshgrid( np.linspace(x_min, x_max, 250), np.linspace(y_min, y_max, 250))
grid = np.c_[xx.ravel(), yy.ravel()]grid_tensor = torch.tensor(grid, dtype=torch.float32)
model.eval()with torch.no_grad(): logits = model(grid_tensor) grid_pred = logits.argmax(dim=1).numpy().reshape(xx.shape)
plt.figure(figsize=(7, 5))plt.contourf(xx, yy, grid_pred, alpha=0.25, cmap="coolwarm")plt.scatter(X_np[:, 0], X_np[:, 1], c=y_np, cmap="coolwarm", s=16, edgecolors="k", linewidths=0.2)plt.xlabel("x1")plt.ylabel("x2")plt.title(f"Decision Boundary (validation accuracy {val_accuracies[-1]:.1%})")plt.grid(True, alpha=0.2)plt.show()この図を見ると、PyTorch がかなり具体的に感じられます。モデルは数字を出すだけではなく、空間をどう分けているかを見せてくれます。
ワークショップから 4 つの成果物を保存します。
- データプロット
- 元のクラスパターンを示す
- 損失曲線
- 学習と検証が一緒に改善しているかを示す
- 決定境界
- モデルが幾何学的に学習した内容を示す
- 失敗ノート
- 境界または検証曲線が不自然に見える1件
この 4 つを説明できれば、ワークショップは copied notebook ではなく、訓練の証拠パックになります。
よくあるエラーと直し方
Section titled “よくあるエラーと直し方”| 現象 | よくある原因 | 直し方 |
|---|---|---|
expected scalar type Long | ラベルが torch.long ではない | y = torch.tensor(y_np, dtype=torch.long) を使う |
| Loss が下がらない | 学習率が大きすぎる、または小さすぎる | lr=0.001 や lr=0.01 を試す |
| loss の shape エラー | 出力またはラベルの形が違う | CrossEntropyLoss では logits は [batch, classes]、ラベルは [batch] |
| 検証時にメモリを使いすぎる | 検証中も勾配を記録している | model.eval() と with torch.no_grad() を使う |
- hidden size を
32から16と64に変え、決定境界を比較する。 noise=0.18をnoise=0.3に変え、タスクがどのくらい難しくなるか見る。- optimizer を
AdamからSGDに変え、損失曲線を比較する。 - 3 つ目の hidden layer を追加し、validation loss が改善するか過学習するか確認する。
操作例と確認ポイント
- hidden size が小さいと境界は単純になり、大きいと複雑な境界を作れます。検証 loss と境界の滑らかさを一緒に見ます。
- noise を増やすとクラスが重なり、訓練 loss も検証 loss も下がりにくくなります。境界はより不確かになります。
- SGD は Adam より学習率設定に敏感です。曲線が遅い、振動する、または途中で止まる可能性があります。
- 層を増やすと容量は増えますが、validation loss が悪化するなら過学習です。改善した場合も seed を変えて再確認します。
このワークショップを終えたら、完整な PyTorch ワークフローを自分の言葉で説明できるようになりましょう。
データの図 → Tensor → DataLoader → model → loss → optimizer → training loop → validation → visualization。
損失曲線と決定境界も読めるなら、ただ PyTorch コードを写している段階を超えて、訓練プロセスが何をしているか理解し始めています。