7.3.5 効率的な注意力機構
- 通常の注意力が長いコンテキストでなぜ高コストになるのかを理解する
- さまざまな効率化の手法が、それぞれどのボトルネックを改善しているのかを区別する
- 実行可能な例を通して、グローバル注意力とローカル注意力の違いを感じ取る
- 学習時と推論時の効率問題を、まず最初の層で見分けられるようにする
一、通常の注意力はどこがそんなに高いのか?
Section titled “一、通常の注意力はどこがそんなに高いのか?”各 token はたくさんの token と比較する必要がある
Section titled “各 token はたくさんの token と比較する必要がある”系列長を n とします。
通常の自己注意では、各位置が他の位置と類似度計算を行います。
すると、比較回数はおおよそ次のようになります。
n * n
つまり、
O(n^2)
n = 512 ならまだそれほど大げさではありません。
しかし n = 32768 になると、状況はまったく違ってきます。
長さが2倍でも、コストは2倍ではない
Section titled “長さが2倍でも、コストは2倍ではない”ここが初心者が最も見落としやすい点です。
系列長が例えば次のように増えるとします。
- 4k -> 8k
コストが単純に2倍になるわけではなく、
多くの部分が4倍近くになります。
だから長いコンテキストのモデルで本当に難しいのは、
「より多くの token を扱える」という言葉そのものではなく、次の点です。
コストを爆発させずに、どうやってより多くの token を扱うか。
学習時と推論時では、つらいポイントが少し違う
Section titled “学習時と推論時では、つらいポイントが少し違う”学習時によくある負荷は次の通りです。
- 注意力行列が大きすぎる
- 中間活性が多すぎる
推論時によくある負荷は次の通りです。
- KV cache がどんどん蓄積する
- 長い会話ほど遅くなり、メモリも多く使う
そのため、効率的な注意力の方法には複数の方向性があります。
すべてが同じ問題を解いているわけではありません。
二、主流の方向性を先に分けておく
Section titled “二、主流の方向性を先に分けておく”スライディングウィンドウ / ローカル注意力:誰が誰を見るかを減らす
Section titled “スライディングウィンドウ / ローカル注意力:誰が誰を見るかを減らす”最も直感的な方法は次のようなものです。
- 各 token に世界中を見せない
- 近くの小さなウィンドウだけを見るようにする
これはつまり、
- 遠くの情報がまったく不要という意味ではない
- ただし、毎層・各位置で全量を見なくてもよい
という考え方です。
代表的な考え方には次のものがあります。
- sliding window attention
- local attention
MQA / GQA:KV cache のサイズを減らす
Section titled “MQA / GQA:KV cache のサイズを減らす”もう1つ重要な方向性は、mask を変えるのではなく、
多頭注意力の K / V の持ち方を変えることです。
通常の多頭注意力では、head ごとに独立した K/V を持つことが多く、
これが推論時の KV cache を非常に大きくします。
そこで次のような方法が登場しました。
- MQA:複数の クエリ head が1組の K/V を共有する
- GQA:クエリ head をグループ化して K/V を共有する
主な効果は次の通りです。
- 推論時のメモリを節約できる
- スループットがよくなる
FlashAttention:公式ではなく、計算の仕方を変える
Section titled “FlashAttention:公式ではなく、計算の仕方を変える”FlashAttention は、よく次のように誤解されます。
- 新しい注意力の定義である
より正確には、次のように理解するとよいです。
注意力の公式自体はほぼ変えず、より効率的な分割計算とメモリの読み書き方法によって、VRAM の使用量とメモリアクセスの無駄を減らす技術。
改善の中心は次の通りです。
- 学習時と推論時の実装効率
モデルが突然、まったく別の関係を理解できるようになるわけではありません。

線形注意力:式そのものから複雑度を下げようとする
Section titled “線形注意力:式そのものから複雑度を下げようとする”さらに踏み込んだ方法もあります。
注意力の計算式そのものを書き換えて、複雑度を二乗から下げようとするものです。
この種の方法では、通常次のようなトレードオフがあります。
- 理論上の複雑度
- 表現力
- 実際の性能
三、まずは本質がわかる例を動かしてみる
Section titled “三、まずは本質がわかる例を動かしてみる”次の例では、2つを比較します。
- グローバル注意力:各位置がすべての位置を見られる
- ローカル注意力:各位置が近くのウィンドウだけを見られる
ここでは「誰を見られるか」だけでなく、
処理しなければならないペアの数も比較します。
from math import exp
values = [0.2, 0.1, 0.0, 0.8, 0.9, 0.7, 0.1, 0.0]
def softmax(scores): m = max(scores) exps = [exp(x - m) for x in scores] total = sum(exps) return [x / total for x in exps]
def attention_outputs(sequence, window=None): outputs = [] pairs = 0 neighborhoods = []
for i in range(len(sequence)): if window is None: neighbors = list(range(len(sequence))) else: left = max(0, i - window) right = min(len(sequence), i + window + 1) neighbors = list(range(left, right))
neighborhoods.append(neighbors) pairs += len(neighbors)
scores = [sequence[i] * sequence[j] for j in neighbors] weights = softmax(scores) output = sum(w * sequence[j] for w, j in zip(weights, neighbors)) outputs.append(output)
return outputs, pairs, neighborhoods
full_outputs, full_pairs, full_neighbors = attention_outputs(values, window=None)local_outputs, local_pairs, local_neighbors = attention_outputs(values, window=2)
print("full pairs :", full_pairs)print("local pairs:", local_pairs)print("token 4 full neighbors :", full_neighbors[4])print("token 4 local neighbors:", local_neighbors[4])print("full outputs :", [round(x, 3) for x in full_outputs])print("local outputs:", [round(x, 3) for x in local_outputs])期待される出力:
full pairs : 64local pairs: 34token 4 full neighbors : [0, 1, 2, 3, 4, 5, 6, 7]token 4 local neighbors: [2, 3, 4, 5, 6]full outputs : [0.376, 0.363, 0.35, 0.457, 0.47, 0.443, 0.363, 0.35]local outputs: [0.101, 0.285, 0.4, 0.604, 0.615, 0.592, 0.44, 0.267]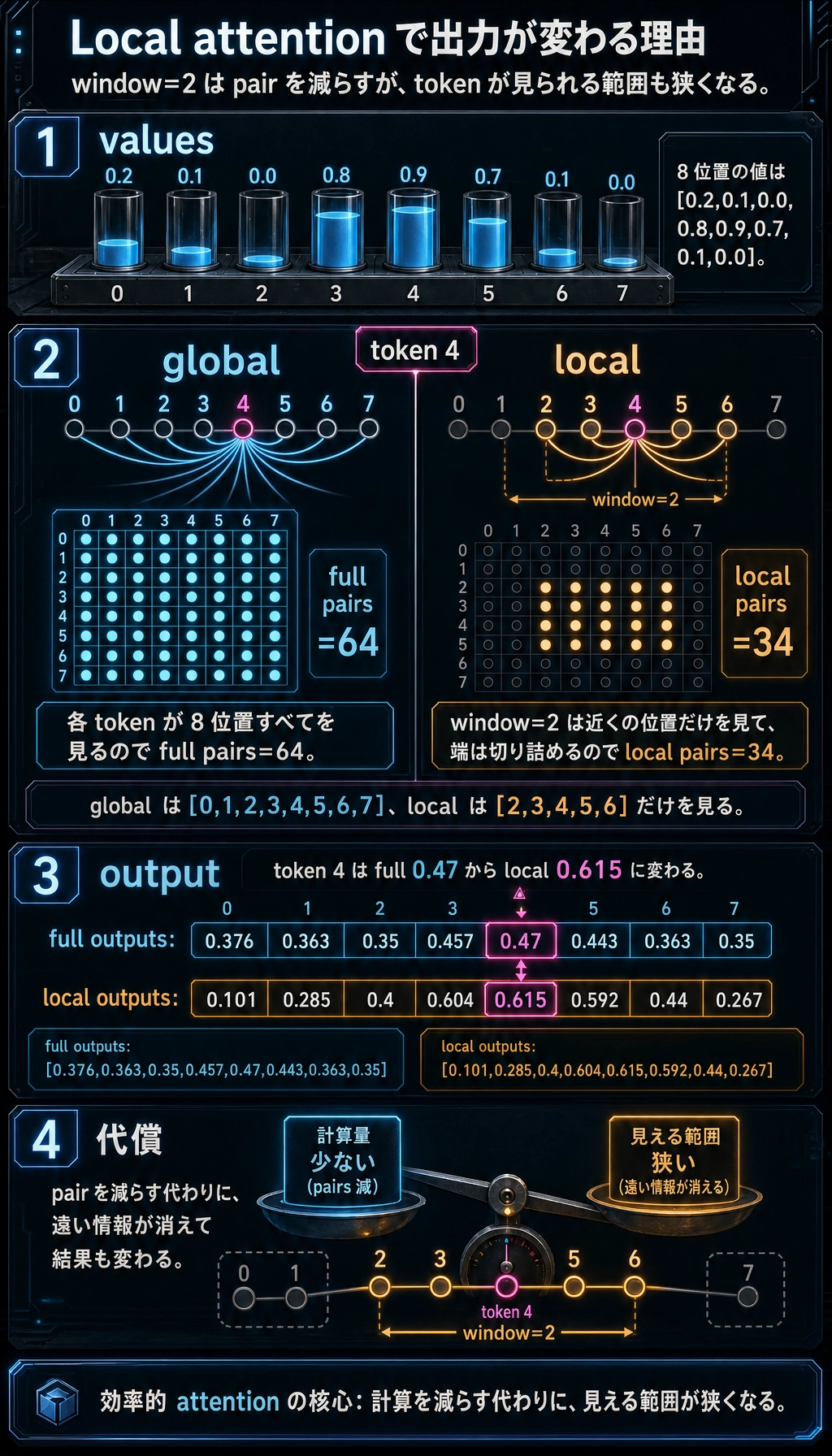
このコードは、どんな直感に対応しているのか?
Section titled “このコードは、どんな直感に対応しているのか?”このコードが教えてくれる重要な点は2つです。
- 各位置が見る範囲を局所に限定すると、ペア数は明らかに減る
- しかし出力も変わる。モデルが遠くの情報を失うからです
これこそが効率的な注意力の核心です。
無料で高速化しているのではなく、効率と見える範囲を引き換えにしている。
なぜ full pairs と local pairs は大きく違うのか?
Section titled “なぜ full pairs と local pairs は大きく違うのか?”グローバル注意力では、各位置がすべての位置を見ます。
ローカル注意力では、各位置はウィンドウ近辺だけを見ます。
系列長が長くなるほど、この差は急速に大きくなります。
なぜローカル注意力が必ずしも悪いとは限らないのか?
Section titled “なぜローカル注意力が必ずしも悪いとは限らないのか?”多くの情報には、もともと局所性があるからです。
たとえば言語では、次のような傾向があります。
- 直近の数 token が最も関連しやすい
- 遠距離依存は重要だが、毎層で全量をモデル化する必要はないことも多い
そのため、多くの長文コンテキストモデルでは次のような混合方式が使われます。
- 一部の層はグローバル
- 一部の層はローカル
- あるいは疎なパターンを持つハイブリッド方式
四、推論時のもう1つの大きな負荷:KV cache
Section titled “四、推論時のもう1つの大きな負荷:KV cache”なぜチャットが長くなると推論が重くなるのか?
Section titled “なぜチャットが長くなると推論が重くなるのか?”decoder-only モデルが生成を行うとき、
前の各ステップの K / V は保存され、後続 token で再利用されます。
これが:
- KV cache
です。
これは重複計算を大幅に減らしてくれますが、
代わりに次の問題があります。
- 会話が長くなるほどキャッシュが大きくなる
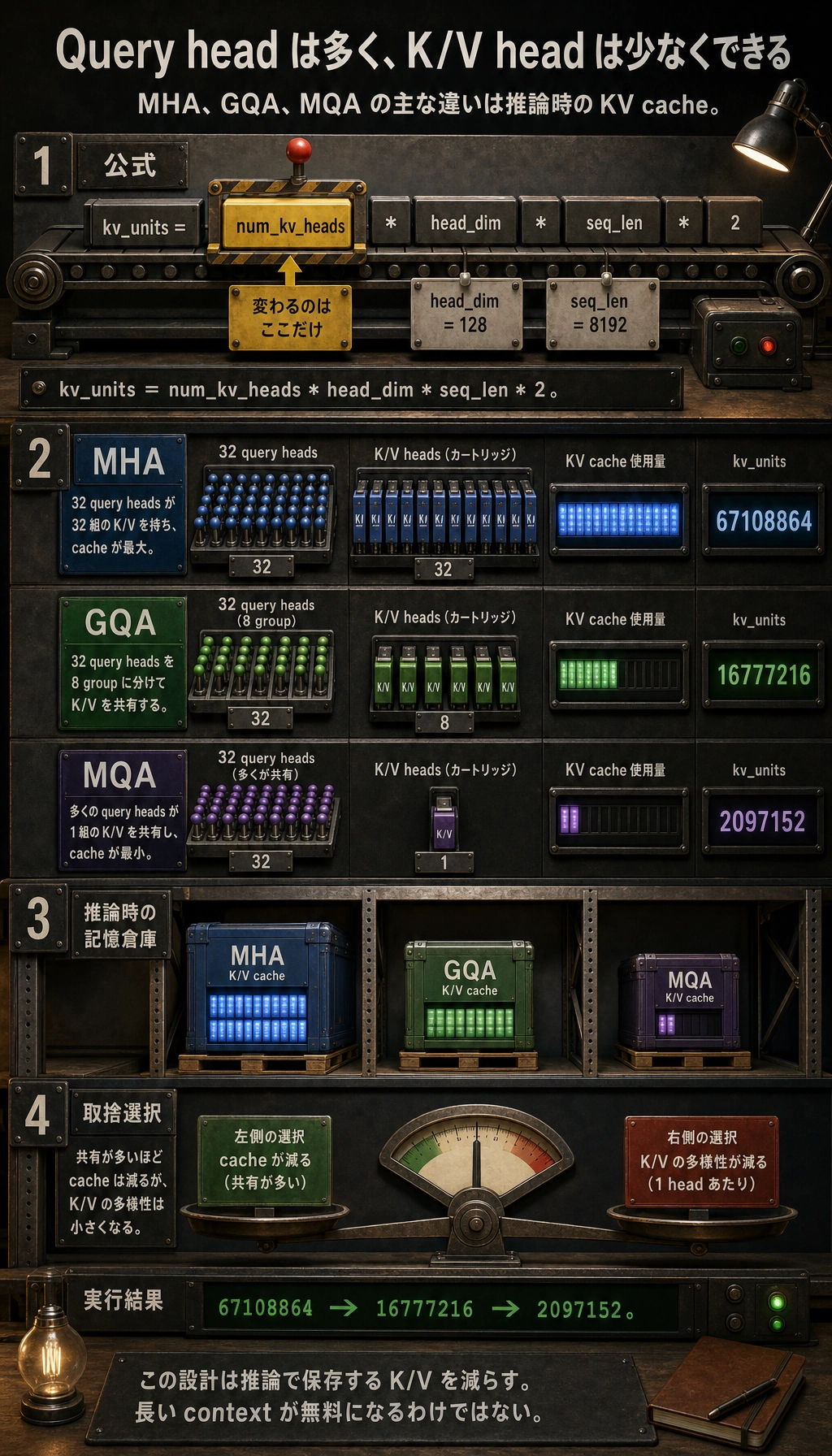
MQA / GQA は何を節約しているのか?
Section titled “MQA / GQA は何を節約しているのか?”節約しているのは注意力行列そのものではなく、
各層・各ステップで保存する K/V の体積です。
ざっくり言うと次のようになります。
- 通常の MHA:各 head がそれぞれ K/V を持つ
- MQA:多くの クエリ head が1組の K/V を共有する
- GQA:クエリ head のグループごとに1組の K/V を共有する
そのため、次の用途に特に向いています。
- 大規模モデルの推論
- 長い対話
- 高スループットのサービス
どれがどれだけ省メモリか、簡単に見積もる
Section titled “どれがどれだけ省メモリか、簡単に見積もる”def kv_units(num_query_heads, num_kv_heads, head_dim, seq_len): return num_kv_heads * head_dim * seq_len * 2
seq_len = 8192head_dim = 128
print("MHA units =", kv_units(32, 32, head_dim, seq_len))print("GQA units =", kv_units(32, 8, head_dim, seq_len))print("MQA units =", kv_units(32, 1, head_dim, seq_len))期待される出力:
MHA units = 67108864GQA units = 16777216MQA units = 2097152この数字は完全な VRAM 公式ではありません。
でも、最初の直感をつかむには十分です。
num_kv_headsが少ないほど- KV cache は小さくなる
五、なぜ FlashAttention はこんなに話題になるのか?
Section titled “五、なぜ FlashAttention はこんなに話題になるのか?”ボトルネックは「計算できないこと」ではなく「データ移動が高すぎること」だから
Section titled “ボトルネックは「計算できないこと」ではなく「データ移動が高すぎること」だから”注意力の実装では、よく次の問題が起こります。
- 中間行列が大きすぎる
- GPU の VRAM の読み書きが頻繁になる
FlashAttention の核心は次の通りです。
- 計算をブロックに分ける
- 高コストなメモリへ中間結果をできるだけ戻さない
そのため、次のような効果が期待できます。
- スループットが上がる
- VRAM 使用量が下がる
これはスライディングウィンドウとは同じ種類ではない
Section titled “これはスライディングウィンドウとは同じ種類ではない”ここは非常に重要です。
- スライディングウィンドウは「誰を見るか」を変える
- FlashAttention は「どう計算するか」を変える
したがって、これらは組み合わせ可能であり、
互いに排他的ではありません。
六、どの方向性を優先して考えるべきか?
Section titled “六、どの方向性を優先して考えるべきか?”長文コンテキストの学習時 VRAM が主な問題なら
Section titled “長文コンテキストの学習時 VRAM が主な問題なら”まず考えるのは次のものです。
- FlashAttention
- activation checkpointing
- sequence parallelism
推論時に KV cache が大きすぎるなら
Section titled “推論時に KV cache が大きすぎるなら”まず考えるのは次のものです。
- MQA
- GQA
- KV cache の量子化
超長文コンテキストで二乗複雑度が問題なら
Section titled “超長文コンテキストで二乗複雑度が問題なら”まず考えるのは次のものです。
- スライディングウィンドウ
- 疎な注意力
- ブロック化またはハイブリッド注意力
- 線形注意力系の方法
つまり、
効率的な注意力は1本のハンマーではなく、異なるボトルネックに対応する道具の集まりです。
七、よくある誤解
Section titled “七、よくある誤解”誤解1:効率的な注意力 = 速くなるうえに必ず良くなる
Section titled “誤解1:効率的な注意力 = 速くなるうえに必ず良くなる”多くの方法は本質的に次のものを交換しています。
- 速度
- メモリ
- 見える範囲
- 実装の複雑さ
すべての指標をただで得られるわけではありません。
誤解2:長いコンテキストに対応すれば、モデルは必ずそれを使いこなせる
Section titled “誤解2:長いコンテキストに対応すれば、モデルは必ずそれを使いこなせる”128k のコンテキストをサポートできることと、
モデルがその中の重要情報を安定して使えることは別です。
これは2つの違う問題です。
- エンジニアリングとして長さを支えること
- モデルがその長さを有効に活用できること
誤解3:FlashAttention は新しいモデルアーキテクチャである
Section titled “誤解3:FlashAttention は新しいモデルアーキテクチャである”違います。
より正確には、効率のよい実装技術に近いものです。
このページを終えたら、この証拠カードを残します。
- コスト源
- 通常の attention は seq_len x seq_len の相互作用を保存または計算する
- アプローチ
- ボトルネックに応じて sparse、linear、FlashAttention、または KV cache
- KVキャッシュ
- デコードを高速化するが、メモリを消費する
- ハードウェア注意
- アルゴリズムの利点は実行時/kernel の対応に依存する
- 判断
- アーキテクチャを変える前に latency/メモリを測る
この節で最も大切なのは、方法名をたくさん覚えることではありません。
まず、問題を切り分けることです。
あなたが今ぶつかっているのは、二乗複雑度なのか、KV cache なのか、それとも VRAM の読み書き効率なのか。
このボトルネックを分けて考えられれば、次に見るべきものが分かります。
- スライディングウィンドウ
- GQA / MQA
- FlashAttention
のどれが適切かを判断しやすくなります。
- 例の
window=2をwindow=1またはwindow=3に変えて、pair 数がどう変わるか観察してみましょう。 - 自分の言葉で説明してみましょう。なぜスライディングウィンドウは「誰を見るか」を変えるのであり、FlashAttention は「どう計算するか」を変えるのでしょうか?
- 長い対話の推論サービスを作るなら、なぜ GQA / MQA はスライディングウィンドウより先に検討されることが多いのでしょうか?
- とても長いコンテキストをサポートすることと、その長いコンテキストを本当に有効に使えることは、なぜ同じではないのでしょうか?
参考実装と解説
- window が小さいほど見える pair は減り、大きいほど増えます。具体的な数は、各 token が見られる局所文脈の範囲に応じて増減します。
- スライディングウィンドウは attention pattern、つまり各 token が見られる相手を変えます。FlashAttention は数学的な attention の結果を変えず、よりメモリ効率のよい kernel で計算します。
- 長い対話の推論サービスでは、まず KV cache のメモリが問題になりやすいです。GQA / MQA は key-value cache を減らせるため、full attention のままでも提供可能な同時セッション数を改善できます。
- 多くの token を受け取れることと、正しい根拠を見つけて結び付け、優先して使えることは別です。context length は容量の上限であり、長文脈を使う力は別途評価すべき挙動です。