3.3.8 データ結合
merge(SQL 風の結合)を身につけるjoin(インデックスベースの結合)を理解するconcat(連結操作)を身につける- さまざまな結合方法の使い分けを理解する
まずは全体像をつかもう
Section titled “まずは全体像をつかもう”データ結合は、「共通キーがあるかどうか」で考えると分かりやすいです。
この節で本当に解決したいのは、次の2点です。
- どんなときに
mergeを最初に思い浮かべるべきか - どんなときに単純な連結でよいのか
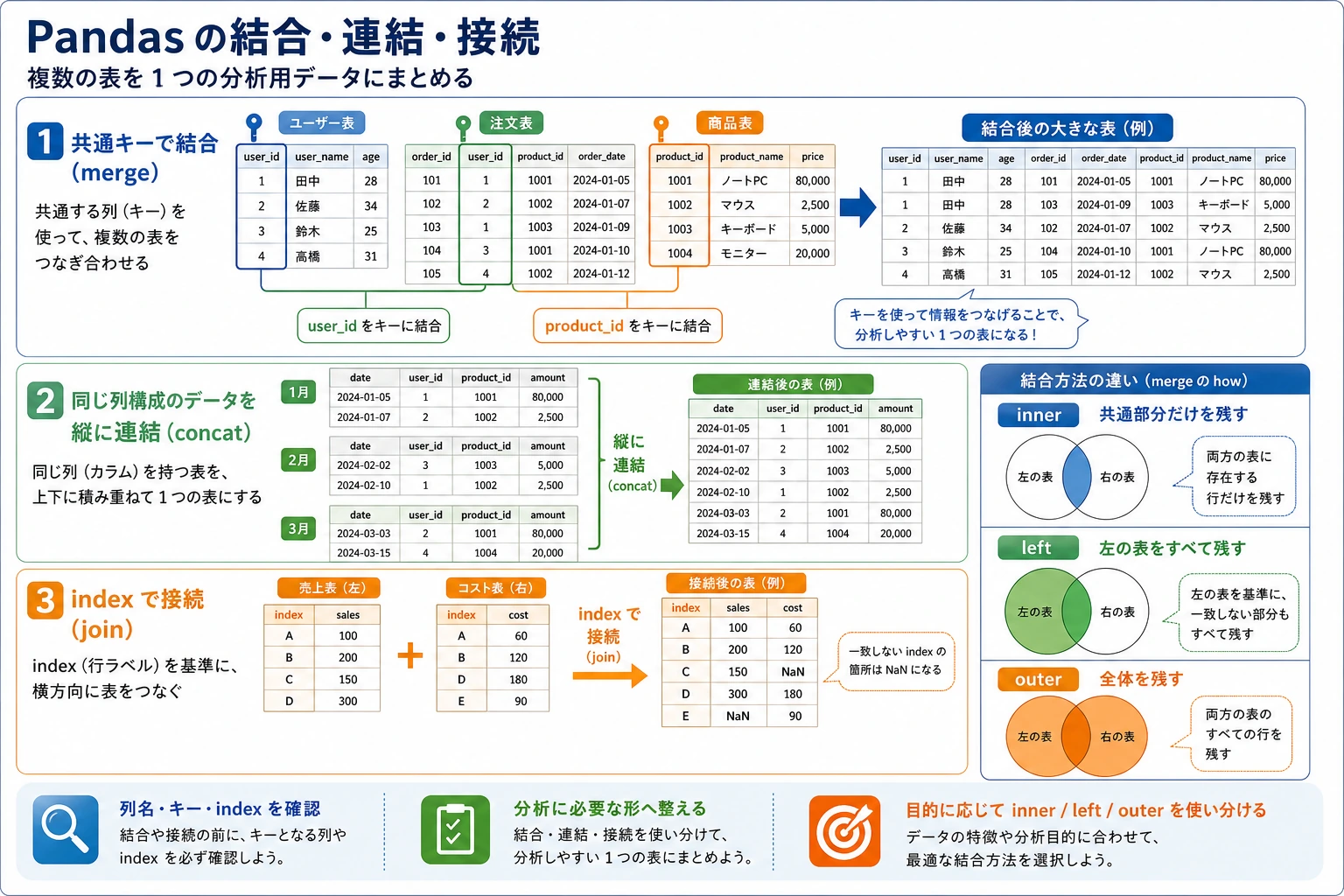
なぜデータを結合するのか?
Section titled “なぜデータを結合するのか?”実際のデータは、たいてい複数の表に分かれています。たとえば EC サイトなら、次のような表があります。
- ユーザー表:ユーザーID、名前、登録時間
- 注文表:注文ID、ユーザーID、商品、金額
- 商品表:商品ID、名前、カテゴリ、価格
「各ユーザーが何を買ったか」を分析するには、これらの表を結合する必要があります。
flowchart LR A["ユーザー表"] --> D["結合後の完全なデータ"] B["注文表"] --> D C["商品表"] --> D
style D fill:#4caf50,color:#fff初心者向けの分かりやすいたとえ
Section titled “初心者向けの分かりやすいたとえ”データ結合は、次のように考えると理解しやすいです。
- さまざまな表にある情報を、同じ人や同じ記録にひも付ける
つまり、
mergeは、身分証番号で2つの台帳をそろえるイメージconcatは、2つの表を上下または左右に並べてつなぐイメージ
この違いはとても大切です。なぜなら、ここで次の2つを分けて考えられるようになるからです。
- 「そろえる」
- 「つなぐ」
この2つは、実は同じではありません。
merge:SQL 風の結合
Section titled “merge:SQL 風の結合”merge は、最も強力な結合方法で、SQL の JOIN に似ています。
例データを準備する
Section titled “例データを準備する”import pandas as pd
# ユーザー表users = pd.DataFrame({ "ユーザーID": [1, 2, 3, 4], "名前": ["張三", "李四", "王五", "趙六"], "都市": ["北京", "上海", "広州", "深圳"]})
# 注文表orders = pd.DataFrame({ "注文ID": [101, 102, 103, 104, 105], "ユーザーID": [1, 2, 1, 3, 5], # 注意:ユーザー5はユーザー表にいない "商品": ["スマホ", "パソコン", "イヤホン", "タブレット", "キーボード"], "金額": [5999, 8999, 299, 3999, 199]})内部結合(inner join)
Section titled “内部結合(inner join)”両方にあるものだけを残します。
result = pd.merge(users, orders, on="ユーザーID", how="inner")print(result)# ユーザーID 名前 都市 注文ID 商品 金額# 0 1 張三 北京 101 スマホ 5999# 1 1 張三 北京 103 イヤホン 299# 2 2 李四 上海 102 パソコン 8999# 3 3 王五 広州 104 タブレット 3999# ユーザー4(趙六)には注文がない → 表示されない# ユーザー5 はユーザー表にない → 表示されない左外部結合(left join)
Section titled “左外部結合(left join)”左側の表の行をすべて残します。
result = pd.merge(users, orders, on="ユーザーID", how="left")print(result)# ユーザーID 名前 都市 注文ID 商品 金額# 0 1 張三 北京 101.0 スマホ 5999.0# 1 1 張三 北京 103.0 イヤホン 299.0# 2 2 李四 上海 102.0 パソコン 8999.0# 3 3 王五 広州 104.0 タブレット 3999.0# 4 4 趙六 深圳 NaN NaN NaN ← 趙六には注文がないので NaN になる右外部結合(right join)
Section titled “右外部結合(right join)”右側の表の行をすべて残します。
result = pd.merge(users, orders, on="ユーザーID", how="right")print(result)# ユーザー5 が表示される(名前と都市は NaN)完全外部結合(outer join)
Section titled “完全外部結合(outer join)”両方の表の行をすべて残します。
result = pd.merge(users, orders, on="ユーザーID", how="outer")print(result)# すべてのユーザーとすべての注文が表示され、足りない部分は NaN で埋められる4種類の結合方法の比較
Section titled “4種類の結合方法の比較”| 結合 | 残る ID | 意味 |
|---|---|---|
inner | {1,2,3} | 両方にある行 |
left | {1,2,3,4} | 左表の全行と、右表の一致情報 |
right | {1,2,3,5} | 右表の全行と、左表の一致情報 |
outer | {1,2,3,4,5} | すべて残す |
初心者がまず覚えやすい早見表
Section titled “初心者がまず覚えやすい早見表”| 目的 | まず思い浮かべる方法 |
|---|---|
| 両方に一致する行だけ残したい | inner merge |
| 左表を基準にして、右表の情報を補いたい | left merge |
| 両方を残して、足りない部分は NaN にしたい | outer merge |
| 複数の表を上下にくっつけたい | concat(axis=0) |
| 複数の列を左右に並べたい | concat(axis=1) |
この表は初心者にとても役立ちます。なぜなら、「結合方法がたくさんある」という状態を、よくある業務目的に整理し直してくれるからです。
列名が違う場合の結合
Section titled “列名が違う場合の結合”# 2つの表で結合列の名前が違う場合df1 = pd.DataFrame({"user_id": [1, 2], "name": ["A", "B"]})df2 = pd.DataFrame({"uid": [1, 2], "score": [90, 85]})
result = pd.merge(df1, df2, left_on="user_id", right_on="uid")print(result)複数列での結合
Section titled “複数列での結合”# 複数の列で一致させるresult = pd.merge(df1, df2, on=["col1", "col2"])concat:連結操作
Section titled “concat:連結操作”concat は、複数の DataFrame を縦または横に連結するときに使います(共通キーは不要です)。
最初に concat で覚えるべきこと
Section titled “最初に concat で覚えるべきこと”まずいちばん大事なのはこれです。
concatは「キーをそろえる」のではなく、「表をつなぐ」操作です。
なので、頭の中で考えていることが
- ユーザーID が一致するか
なら、まずは merge を考えるのが自然です。
縦方向の連結(上下に追加)
Section titled “縦方向の連結(上下に追加)”# 1月と2月の売上データjan = pd.DataFrame({ "商品": ["リンゴ", "牛乳"], "売上": [100, 80], "月": ["1月", "1月"]})
feb = pd.DataFrame({ "商品": ["リンゴ", "パン"], "売上": [120, 90], "月": ["2月", "2月"]})
# 上下に連結all_sales = pd.concat([jan, feb], ignore_index=True)print(all_sales)# 商品 売上 月# 0 リンゴ 100 1月# 1 牛乳 80 1月# 2 リンゴ 120 2月# 3 パン 90 2月横方向の連結
Section titled “横方向の連結”info = pd.DataFrame({"名前": ["張三", "李四"], "年齢": [22, 25]})scores = pd.DataFrame({"数学": [90, 85], "英語": [88, 92]})
# 左右に連結combined = pd.concat([info, scores], axis=1)print(combined)# 名前 年齢 数学 英語# 0 張三 22 90 88# 1 李四 25 85 92merge vs concat vs join
Section titled “merge vs concat vs join”| 方法 | 適用場面 | たとえ |
|---|---|---|
merge | 共通列で2つの表を結合する | SQL JOIN |
concat | 単純に上下または左右に連結する | のりで貼り合わせる |
join | インデックスで結合する | 特別な merge |
flowchart TD A["データを結合したい"] --> B{"共通の key 列はある?"} B -->|"ある"| C["merge を使う"] B -->|"ない、ただ並べたい"| D{"上下に並べる?左右?"} D -->|"上下"| E["concat(axis=0)"] D -->|"左右"| F["concat(axis=1)"]初心者がそのまま使えるデータ結合チェックリスト
Section titled “初心者がそのまま使えるデータ結合チェックリスト”初めて複数表の問題に取り組むときは、次の順番で確認すると安全です。
- 共通キーはあるか?
- キーの型と値の範囲は一致しているか?
- 結合後に行数が増えたり減ったりするのはなぜか?
- 今やっているのは「そろえる」ことか、それとも「つなぐ」ことか?
この4つを先に考えるだけで、merge / concat の問題は、魔法のように見えなくなります。
実践:複数表の結合分析
Section titled “実践:複数表の結合分析”import pandas as pd
# 3つの表を作成# タスク表tasks = pd.DataFrame({ "タスク ID": [1, 2, 3, 4, 5], "機能": ["ログイン API", "RAG デモ", "グラフ画面", "デプロイスクリプト", "評価レポート"], "モジュール": ["バックエンド", "AI", "フロントエンド", "運用", "AI"]})
# 作業ログ表(タスクによっては複数の作業記録がある)work_logs = pd.DataFrame({ "タスク ID": [1, 1, 2, 2, 3, 3, 4, 4, 5, 5], "段階": ["設計", "実装", "設計", "実装", "設計", "実装", "実装", "検証", "設計", "検証"], "時間": [2.0, 5.0, 3.0, 6.5, 1.5, 4.0, 3.5, 1.0, 2.5, 2.0]})
# モジュール担当表modules = pd.DataFrame({ "モジュール": ["バックエンド", "AI", "フロントエンド", "運用"], "担当者": ["Mina", "Kai", "Riley", "Noah"], "スプリント目標": ["安定した API", "根拠のある回答", "読みやすい UI", "再現できるリリース"]})
# 結合1:タスク + 作業ログtask_logs = pd.merge(tasks, work_logs, on="タスク ID")print(task_logs.head())
# 結合2:さらにモジュール担当を追加full = pd.merge(task_logs, modules, on="モジュール")print(full.head())
# 分析:各モジュールの平均作業時間print(full.groupby(["モジュール", "担当者"])["時間"].mean())
# 分析:各タスクの合計作業時間ランキングtotal_hours = full.groupby(["タスク ID", "機能"])["時間"].sum().reset_index()total_hours["順位"] = total_hours["時間"].rank(ascending=False, method="dense")print(total_hours.sort_values("順位"))このページを終えたら、この evidence card を残します。
- データフレーム状態
- 列、dtype、行数、欠損値、サンプル行
- 操作
- read/write、select/filter、clean、transform、groupby、merge、または時系列処理
- 出力
- resulting table、保存ファイル、aggregation、join結果、または時系列インデックスビュー
- 失敗確認
- dtype 不一致、欠損データ、重複キー、チェーン代入、または誤った時間頻度
- 期待される成果
- 前後の表サンプルと、変換理由
| 操作 | 関数 | 重要な引数 |
|---|---|---|
| SQL 風の結合 | pd.merge() | on, how (inner/left/right/outer) |
| 縦方向の連結 | pd.concat(axis=0) | ignore_index=True |
| 横方向の連結 | pd.concat(axis=1) | |
| インデックスでの結合 | df.join() | how |
この節で必ず持ち帰りたいこと
Section titled “この節で必ず持ち帰りたいこと”mergeは共通キーでそろえる操作、concatは表をつなぐ操作- 「共通キーがあるか?」を先に考えると、どの方法を使うか判断しやすい
- 複数表の分析では、後の集計ミスよりも、最初の結合ミスのほうがよく起こる
手を動かしてみよう
Section titled “手を動かしてみよう”練習 1:基本的な merge
Section titled “練習 1:基本的な merge”# 2つの表がある:社員表と部署表# 1. inner join で結合する# 2. left join で部署が未割り当ての社員を見つける# 3. outer join で社員がいない部署を見つける練習 2:複数表の結合分析
Section titled “練習 2:複数表の結合分析”# 商品表、注文表、顧客表を作成する# 1. 3つの表を結合して1つの完全な表にする# 2. 各顧客がどのカテゴリの商品を買ったかを分析する# 3. 購入金額が最も高い上位3人の顧客を見つける練習 3:concat 連結
Section titled “練習 3:concat 連結”# 四半期ごとの売上データ(4つの独立した DataFrame)がある# 1. 縦方向に連結して年間データにする# 2. "四半期" 列を追加してデータの出所を示す# 3. 年間の各四半期の売上傾向を集計する参考実装と解説
- 一致したキーだけが必要なら
innerjoin、左表を正とするならleftjoin、両側の不一致を調べたいならouterjoin を使います。 - 結合前に重複キーを確認し、関係が 1 対 1、1 対多、多対多のどれかを決めます。可能なら
validate=を使い、想定外の重複を Pandas に検出させます。 - 各 merge の後は、行数を比較し、結合列の null を確認し、未一致キーをサンプル表示します。これらを書き残して初めて結合完了です。