1.4.2 AI Coding Agent のワークフロー
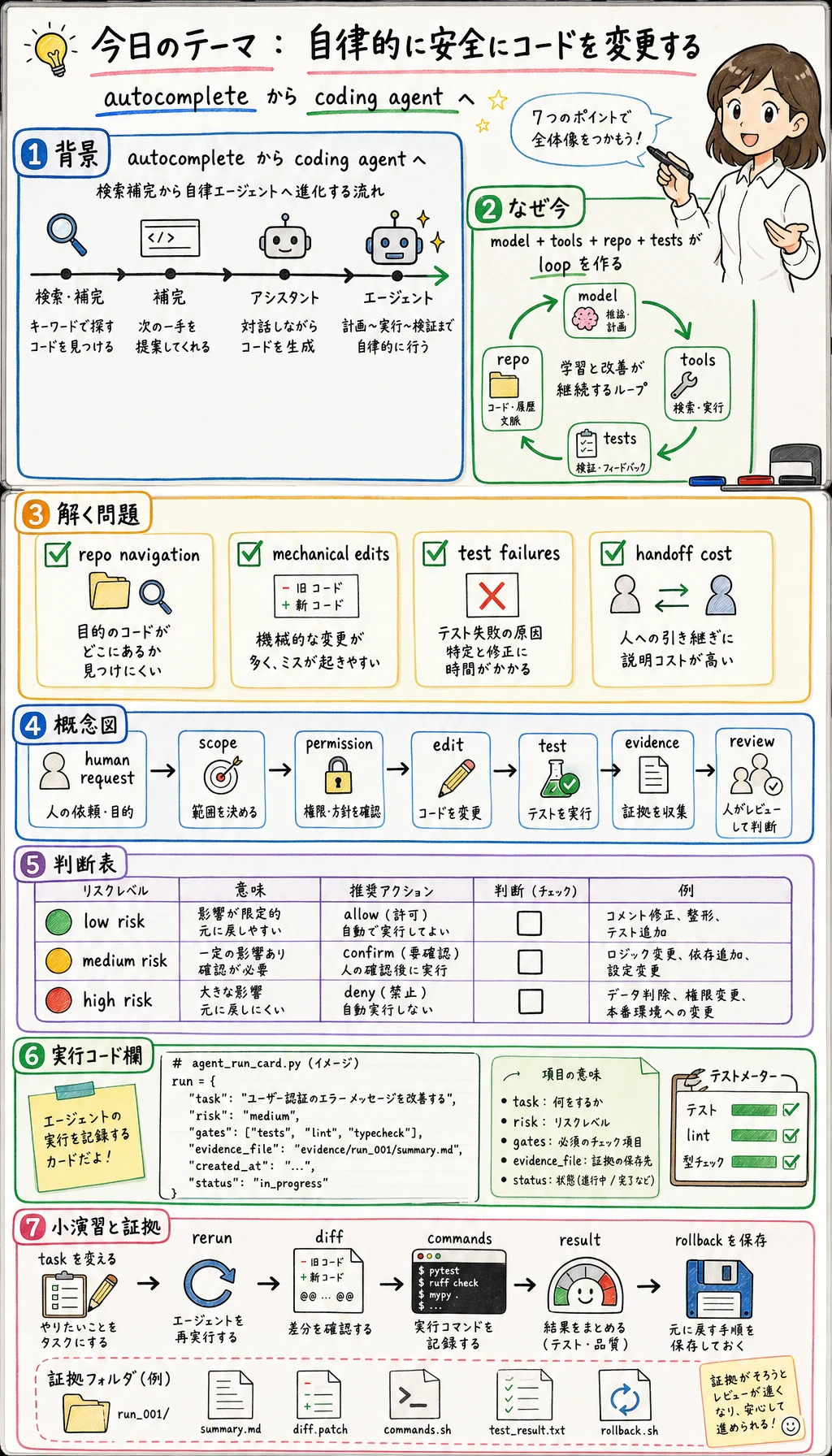
AI Coding Agent は、単なるコード補完ではありません。Codex や Google Antigravity のようなツールは、リポジトリを読み、ファイルを編集し、テストを実行し、作業の証跡を残せます。ただし、本当に役に立つのは、タスクが狭く、権限が明確で、結果を証明できるときです。
このレッスンでは、まずワークフローを学びます。最後には、他の開発者がレビューできる実行カードを作れるようになります。
なぜ登場したのか
Section titled “なぜ登場したのか”以前の AI コーディング支援は「この関数をどう書くか」に近いものでした。Agentic Coding が扱う問いは別です。
モデルは実リポジトリの文脈を読み、コードを変更し、検証し、リスクを説明できるか。
それが可能になった背景には、モデル推論、ツール呼び出し、長文脈、ターミナル実行、コードレビュー UI の成熟があります。基本ループは次の通りです。
- リポジトリと制約を読む。
- 小さな編集計画を作る。
- ファイルをパッチする。
- テストやチェックを実行する。
- 証拠をまとめる。
- リスクが高い場合は人間レビューに戻す。
解く問題は「速く書く」だけではありません。より重要なのは引き継ぎコストを下げることです。Agent は文脈を集め、範囲を絞って変更し、人間が確認できる証拠をまとめます。
解決する問題
Section titled “解決する問題”| 開発上の問題 | Agent の役割 | 人間の役割 | 残す証拠 |
|---|---|---|---|
| 大きなリポジトリで入口が分からない | ファイル検索、入口の特定、所有範囲の推定 | 依頼範囲を確認 | 検索メモと変更ファイル |
| 小さなバグに機械的変更が多い | 一貫した編集とフォーマット | 意図とプロダクト挙動を確認 | diff、テスト、スクリーンショット |
| テスト失敗の原因が曖昧 | ログを読み、失敗層を切り分ける | 修正範囲を判断 | 失敗コマンドと修正後コマンド |
| リファクタのリスクが隠れる | 編集前にリスクカードを出す | 承認、縮小、拒否を決める | リスクレベルとロールバックメモ |
| レビューが重い | 各変更の理由を要約 | 挙動とエッジケースを確認 | commit メッセージと QA メモ |
Agent に渡す前に、この表でタスクを絞ります。
| 状況 | 良い Agent タスク | 最初に避けるタスク | 必須ゲート |
|---|---|---|---|
| 1つの単体テストが失敗 | 「この失敗を直し、根本原因を説明する」 | 「モジュール全体を書き直す」 | 失敗テストと近いテストを実行 |
| UI 文言やレイアウト | 「この部分を直してスクショで確認する」 | 「アプリ全体を再設計する」 | ブラウザスクリーンショット |
| 新しい教材ページ | 「既存テンプレートに合わせて1ページ追加」 | 「カリキュラム構造を作り直す」 | リンク確認と course QA |
| セキュリティや削除 | 「調査し、パッチ計画を出す」 | 「破壊的な削除を実行」 | 人間の承認 |
| 依存関係更新 | 「破壊的変更を見て1つ更新」 | 「全部更新」 | lockfile diff とビルド |
実行できる演習: Agent 実行カード
Section titled “実行できる演習: Agent 実行カード”agent_run_card.py を作り、Python 3.10 以上で実行します。
import jsonfrom pathlib import Path
task = { "request": "fix a broken course sidebar link", "files_likely_touched": ["src/content/docs", "astro.config.mjs"], "can_run_tests": True, "touches_user_data": False, "changes_public_behavior": True,}
def classify_risk(info): if info["touches_user_data"]: return "high" if info["changes_public_behavior"]: return "medium" return "low"
def choose_gates(info): gates = ["read surrounding files", "make minimal patch", "record diff"] if info["can_run_tests"]: gates.append("run relevant QA command") if info["changes_public_behavior"]: gates.append("capture before/after behavior") return gates
run_card = { "task": task["request"], "agent_scope": "one narrow bug or content fix", "risk": classify_risk(task), "permissions": { "read": True, "edit": True, "network": False, "destructive_commands": False, }, "gates": choose_gates(task), "evidence_file": "agent_evidence.md",}
Path("agent_run_card.json").write_text(json.dumps(run_card, indent=2), encoding="utf-8")print(json.dumps(run_card, indent=2))期待される出力:
{ "task": "fix a broken course sidebar link", "agent_scope": "one narrow bug or content fix", "risk": "medium", "permissions": { "read": true, "edit": true, "network": false, "destructive_commands": false }, "gates": [ "read surrounding files", "make minimal patch", "record diff", "run relevant QA command", "capture before/after behavior" ], "evidence_file": "agent_evidence.md"}コードを一行ずつ読む
Section titled “コードを一行ずつ読む”task は入力契約です。人間の依頼、触りそうなファイル、リスクを明示します。
classify_risk() は権限ゲートです。文言修正とユーザーデータ移行を同じ扱いにしてはいけません。
choose_gates() はタスクを検証ステップに変えます。「変更した」から「変更し、確認し、証拠を示せる」へ変わります。
run_card は引き継ぎ成果物です。実際のリポジトリでは PR、commit メッセージ、タスクメモに添付します。
request を次のどれかに変えて再実行してください。
- 「トップページの meta description を更新する」
- 「古いユーザーアカウントを削除する」
- 「新しい API endpoint を追加する」
各回で答えます。
| 質問 | 判断すること |
|---|---|
| リスクは low / medium / high のどれか | ラベルだけでなく理由を書く |
| 追加ゲートは何か | テスト、スクショ、セキュリティレビュー、移行バックアップ、人間承認 |
| レビュー担当を納得させる証拠は何か | diff、ログ、スクショ、request/response、rollback メモ |
AI Coding Agent の作業を終える前に、最低限このパケットを残します。
- Request
- 人間の依頼
- Scope
- 意図して触ったファイルや挙動
- Risk
- low, medium, high
- Commands
- 実行したチェック
- Result
- pass, fail, または未実行の理由
- Diff Summary
- 何をなぜ変更したか
- Rollback
- 戻し方、または commit の位置
AI Coding Agent は「手が速く、ノートを厳密に書く初級エンジニア」として扱うと強力です。狭いタスク、明確な権限、検証、証拠をセットにしてください。
理解チェック
曖昧な依頼を実行カードに変え、リスクを名付け、検証ゲートを選び、レビュー担当が見るべき証拠を説明できれば合格です。