11.4.2 シーケンスラベリングタスク
- シーケンスラベリングと文全体分類の根本的な違いを理解する
- BIO / BIOES のようなラベル体系がなぜよく使われるのかを理解する
- 実行可能な例を通して token 単位のラベリング手順を理解する
- シーケンスラベリングと情報抽出タスクのつながりを理解する
一、シーケンスラベリングは何を解決するのか?
Section titled “一、シーケンスラベリングは何を解決するのか?”「この文は何か」を判断するだけでなく、「この文のどの部分が何か」を判断する
Section titled “「この文は何か」を判断するだけでなく、「この文のどの部分が何か」を判断する”たとえば、次の文を考えます。
- 「張三は北京大学で働いている」
テキスト分類なら、たとえば次のように出力されるかもしれません。
- これは人物と場所に関する文である
しかしシーケンスラベリングでは、より重要なのは次のような点です。
張三は人名北京大学は組織名
なぜこれが重要なのか?
Section titled “なぜこれが重要なのか?”なぜなら、実際の多くの業務では、文全体の理解だけでは足りないからです。 より知りたいのは、たとえば次のような情報です。
- 人名
- 住所
- 組織名
- 金額
- 時間
つまり、具体的な断片の位置や境界です。
たとえで考えると
Section titled “たとえで考えると”テキスト分類は、記事全体にラベルを貼るようなものです。 シーケンスラベリングは、蛍光ペンで文の重要部分を囲むようなものです。
二、なぜ出力は通常 token 単位なのか?
Section titled “二、なぜ出力は通常 token 単位なのか?”実体は連続した断片だから
Section titled “実体は連続した断片だから”抽出したい情報の多くは、単語1つではなく、連続した span です。 たとえば次のようなものです。
上海交通大学2025年6月1日
token 単位のラベルなら境界を表現できる
Section titled “token 単位のラベルなら境界を表現できる”そのため、よく使われるラベル体系は、単純に次のように書くのではなく、
- PERSON
- LOCATION
次のように書きます。
B-PERI-PERO
BIO の直感
Section titled “BIO の直感”B-:実体の開始I-:実体の内部O:どの実体にも属さない
こうすることで、システムはより明確に区別できます。
- 実体がどこから始まるか
- どこで終わるか
三、まずは最小の BIO ラベリング例を動かしてみる
Section titled “三、まずは最小の BIO ラベリング例を動かしてみる”tokens = ["張三", "は", "北京", "大学", "で", "働いている"]tags = ["B-PER", "O", "B-ORG", "I-ORG", "O", "O"]
for tok, tag in zip(tokens, tags): print(tok, tag)実行結果の例:
張三 B-PERは O北京 B-ORG大学 I-ORGで O働いている Otoken の列とタグの列は同じ長さでなければなりません。系列ラベリングのデータを見るとき、最初に確認するのはこの一対一の対応です。
この例でいちばん大事なことは?
Section titled “この例でいちばん大事なことは?”ここで見えてくるのは、
- シーケンス入力
- 対応するシーケンス出力
です。
これが、シーケンスラベリングの最も基本的な形です。
token の列を入力し、同じ長さのラベル列を出力する。
なぜ 北京 大学 が B-ORG / I-ORG なのか?
Section titled “なぜ 北京 大学 が B-ORG / I-ORG なのか?”ここで表したいのは、
- これは同じ連続した実体である
ということです。
別々の2つの実体ではありません。
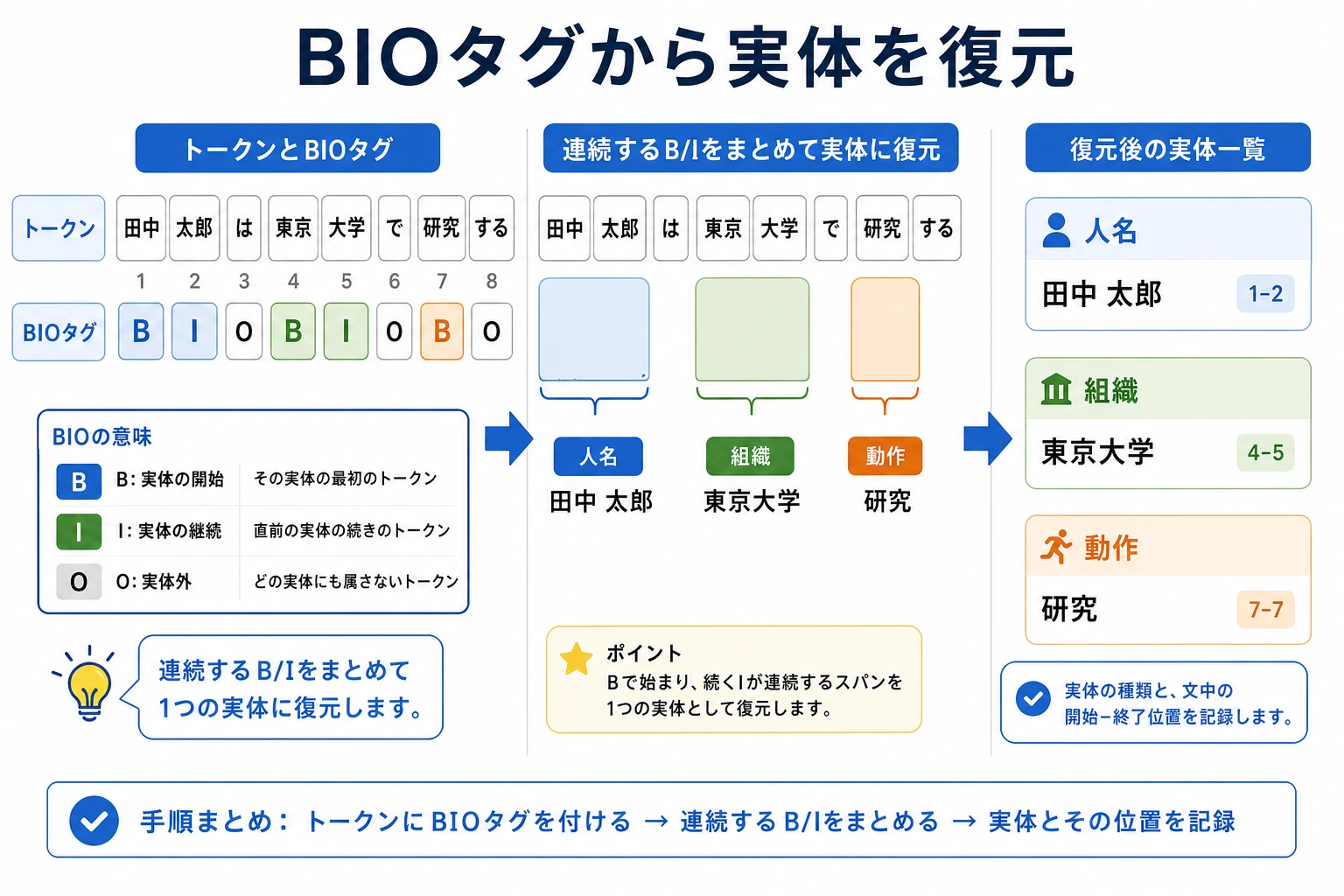
四、ラベル列から実体を復元する
Section titled “四、ラベル列から実体を復元する”次の例では、token + BIO ラベルから実体の断片を復元します。
tokens = ["張三", "は", "北京", "大学", "で", "働いている"]tags = ["B-PER", "O", "B-ORG", "I-ORG", "O", "O"]
def decode_entities(tokens, tags): entities = [] current_tokens = [] current_type = None
for token, tag in zip(tokens, tags): if tag == "O": if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [] current_type = None continue
prefix, entity_type = tag.split("-", 1)
if prefix == "B": if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type elif prefix == "I" and current_type == entity_type: current_tokens.append(token) else: # ラベルが不正な場合は、いったん切って開き直す if current_tokens: entities.append(("".join(current_tokens), current_type)) current_tokens = [token] current_type = entity_type
if current_tokens: entities.append(("".join(current_tokens), current_type))
return entities
print(decode_entities(tokens, tags))実行結果の例:
[('張三', 'PER'), ('北京大学', 'ORG')]この処理で、token 単位のラベルが実際に使う成果物、つまりエンティティ文字列とエンティティタイプに変わります。
このコードが重要なのはなぜ?
Section titled “このコードが重要なのはなぜ?”これは「ラベリングタスク」と「抽出結果」をつないでいるからです。 実際のシステムで本当に大事なのは、タグそのものよりも、次のような結果です。
- 実体 span
- 実体の種類
五、シーケンスラベリングと情報抽出の関係は?
Section titled “五、シーケンスラベリングと情報抽出の関係は?”NER は典型的なシーケンスラベリングタスク
Section titled “NER は典型的なシーケンスラベリングタスク”最も代表的なのは次のタスクです。
- 命名実体認識
でも NER だけではない
Section titled “でも NER だけではない”ほかにも次のような用途があります。
- スロットフィリング
- キーワード抽出
- イベントトリガー語の位置特定
つまり「情報抽出の土台となるスキル」
Section titled “つまり「情報抽出の土台となるスキル」”多くの抽出システムは、さらに複雑になります。 それでも、いちばん基礎となる一歩は、しばしば次のことです。
- まず重要な span を見つける
六、よくある落とし穴
Section titled “六、よくある落とし穴”誤解1:シーケンスラベリングを普通の分類だと思ってしまう
Section titled “誤解1:シーケンスラベリングを普通の分類だと思ってしまう”文全体分類との最大の違いは、
- 出力が列に対して対応づいていること
です。
誤解2:ラベルだけ見て、境界の復元を見ない
Section titled “誤解2:ラベルだけ見て、境界の復元を見ない”実際のシステムでは、ラベル表そのものよりも、最終的に抽出された実体片のほうが重要です。
誤解3:ラベル体系を適当に決める
Section titled “誤解3:ラベル体系を適当に決める”ラベル設計が乱れていると、モデルも評価も一緒に乱れます。
このページを終えたら、この evidence card を残します。
- スキーマ
- エンティティ型、BIO タグ、またはシーケンスラベル規則
- 予測
- トークン単位のラベルと抽出スパン
- 指標
- エンティティの precision/recall/F1 と境界ケース
- 失敗確認
- span 境界、入れ子のエンティティ、未知語、または不一致なアノテーション
- 期待される成果
- 少なくとも1つの miss がある、gold と predicted の span 表
この節でいちばん大切なのは、次の考え方を身につけることです。
シーケンスラベリングの核心は、入力シーケンスの各 token にラベルを付け、それによって文の中の重要な断片と境界を復元すること。
この感覚がしっかりしていれば、後で NER、BiLSTM+CRF、情報抽出プロジェクトを学ぶときに、かなり理解しやすくなります。
- 例に時間表現
2025年を追加して、自分で BIO ラベルの組を作ってみましょう。 - なぜ BIO ラベル体系の重要な役割は、実体の境界を表すことだと言えるのでしょうか?
- 自分の言葉で説明してみましょう。シーケンスラベリングとテキスト分類の最大の違いは何ですか?
- 考えてみましょう。ラベル列の中に不正な
I-XXXが出てきたら、システムはどう処理するとより安定でしょうか?
参考実装と解説
2025が 1 token の時間エンティティならB-TIMEです。複数 token にまたがる場合だけB-TIME I-TIME ...を使います。- BIO の役割は boundary を表すことです。どの token で entity が始まり、どの token が同じ entity を続けるかを示します。
- sequence labeling は token ごとに label を出します。text classification はテキスト全体に 1 つの label を出します。
- 不正な
I-XXXは post-processing で修復または拒否し、error として記録し、training label や decoding rule に戻って確認します。