9.2.7 推論評価と最適化
- 推論システムは最終回答の正確率だけでは評価できないと理解する
- 過程の品質、ツール効率、コストも評価する必要がある理由を理解する
- 実行できる例を通して、よく使う推論指標を理解する
- 評価結果に基づいて、狙いを絞って最適化する方法を学ぶ
なぜ推論評価は普通の QA より複雑なのか?
Section titled “なぜ推論評価は普通の QA より複雑なのか?”推論システムは、ただ1つのテキストを出すだけではないから
Section titled “推論システムは、ただ1つのテキストを出すだけではないから”ある推論 Agent は、次のようなものも出します。
- 複数ステップの トレース
- ツール呼び出しの記録
- 中間状態
- 最終回答
つまり、これは単発の出力問題ではなく、
過程を持つシステムの問題です。
最終的な正確率だけを見ると、多くの情報を見落とす
Section titled “最終的な正確率だけを見ると、多くの情報を見落とす”たとえば、どちらのシステムも 80% 正解したとします。
- システム A は平均 3 ステップで、ほとんどツールを無駄に使わない
- システム B は平均 9 ステップで、よく重複して調べ、コストが2倍になる
accuracy だけを見ると、
両者はあまり変わらないように見えます。
でもエンジニアリングの観点では、まったく同じレベルではありません。
たとえ話:目的地に着いたかだけでなく、どうやって着いたかも見る
Section titled “たとえ話:目的地に着いたかだけでなく、どうやって着いたかも見る”2台の車がどちらも目的地に着いたとしても、
- 1台は安定して到着した
- もう1台は遠回りをし、急ブレーキをかけ、危うく事故になりそうだった
この2台を同じとは言いません。
推論システムも同じです。
推論システムでよく見る4種類の指標
Section titled “推論システムでよく見る4種類の指標”最終結果の指標
Section titled “最終結果の指標”もっともよく使うのは次のようなものです。
- 回答精度(answer accuracy)
- 完全一致率(exact match)
- 合格率(pass rate)
これは次の問いに答えます。
- 最終結論は正しいか
過程品質の指標
Section titled “過程品質の指標”たとえば、
- 重要なステップが抜けていないか
- 矛盾していないか
- 無意味なループがないか
これは次の問いに答えます。
- 過程を信頼できるか
ツール使用の指標
Section titled “ツール使用の指標”たとえば、
- ツール成功率
- 重複呼び出し率
- 不要な呼び出し率
これは次の問いに答えます。
- ツールを適切に使えているか
コストと効率の指標
Section titled “コストと効率の指標”たとえば、
- 平均ステップ数
- 平均レイテンシ
- 平均 token コスト
これは次の問いに答えます。
- このシステムは本番投入する価値があるか
まずは本当に役立つ評価スクリプトを動かしてみよう
Section titled “まずは本当に役立つ評価スクリプトを動かしてみよう”次のコードは、2つの agent の trace の品質を比較します。
以下を集計します。
- 最終回答の正確率
- 平均ステップ数
- ツール成功率
- 重複ツール呼び出し率
agent_a = [ { "id": "case_1", "expected": "59", "final_answer": "59", "trace": [ {"tool": "calculator", "ok": True}, ], }, { "id": "case_2", "expected": "3〜7営業日", "final_answer": "3〜7営業日", "trace": [ {"tool": "search_policy", "ok": True}, ], },]
agent_b = [ { "id": "case_1", "expected": "59", "final_answer": "59", "trace": [ {"tool": "search_policy", "ok": True}, {"tool": "calculator", "ok": True}, {"tool": "calculator", "ok": True}, ], }, { "id": "case_2", "expected": "3〜7営業日", "final_answer": "5〜10営業日", "trace": [ {"tool": "search_policy", "ok": False}, {"tool": "search_policy", "ok": True}, ], },]
def evaluate_agent(cases): accuracy = sum(case["final_answer"] == case["expected"] for case in cases) / len(cases) avg_steps = sum(len(case["trace"]) for case in cases) / len(cases)
tool_calls = [item for case in cases for item in case["trace"]] tool_success = sum(item["ok"] for item in tool_calls) / len(tool_calls)
repeated_tool_calls = 0 for case in cases: tools = [item["tool"] for item in case["trace"]] repeated_tool_calls += len(tools) - len(set(tools))
repeated_rate = repeated_tool_calls / len(cases)
return { "accuracy": round(accuracy, 3), "avg_steps": round(avg_steps, 3), "tool_success": round(tool_success, 3), "repeated_tool_calls_per_case": round(repeated_rate, 3), }
print("agent_a:", evaluate_agent(agent_a))print("agent_b:", evaluate_agent(agent_b))期待される出力:
agent_a: {'accuracy': 1.0, 'avg_steps': 1.0, 'tool_success': 1.0, 'repeated_tool_calls_per_case': 0.0}agent_b: {'accuracy': 0.5, 'avg_steps': 2.5, 'tool_success': 0.8, 'repeated_tool_calls_per_case': 1.0}このコードから何を持ち帰るべきか?
Section titled “このコードから何を持ち帰るべきか?”一番大事なのは、どの式かではありません。
大事なのは、この考え方です。
同じシステムでも、少なくとも答えの品質、過程の長さ、ツールの挙動を同時に見る必要がある。
この3つをまとめて見ることで、
そのシステムが本当に安定しているのか、それともたまたま正解しているだけなのかが分かります。
なぜ agent_b は一見そこまで悪く見えなくても、実際にはもっと悪いのか?
Section titled “なぜ agent_b は一見そこまで悪く見えなくても、実際にはもっと悪いのか?”なぜなら、次のような問題が起こりやすいからです。
- ステップ数が長い
- 重複したツール呼び出しが多い
- ツール失敗後のリカバリーが必要になる
個々の case でたまたま答えが合っていても、
コストはより高くなります。
なぜ重複呼び出し率を個別に見る価値があるのか?
Section titled “なぜ重複呼び出し率を個別に見る価値があるのか?”多くの Agent でよくある問題は、「まったくできない」ことよりも、次のようなものです。
- 思い切りが足りない
- 同じツールを何度も試す
- 不要な動きをたくさんする
これはシステムを遅くし、コストを直接押し上げます。
評価では「正解したかどうか」だけを見てはいけない
Section titled “評価では「正解したかどうか」だけを見てはいけない”答え型タスクでは、正確率を見る
Section titled “答え型タスクでは、正確率を見る”たとえば、
- 数学問題
- ルールに基づく QA
- 明確な検索問題
過程型タスクでは、ステップが妥当かを見る
Section titled “過程型タスクでは、ステップが妥当かを見る”たとえば、
- 重要なステップが抜けていないか
- 先に結論を出していないか
- まず調べてから計算しているか
Agent タスクでは、アクションが割に合っているかを見る
Section titled “Agent タスクでは、アクションが割に合っているかを見る”たとえば、
- 不要なツール呼び出しがないか
- ツール失敗後にループしていないか
- 十分な情報がそろったら、適切なタイミングで止まれているか
止めるタイミング自体も、能力の一部です。
評価結果を取ったあと、どう最適化するか?
Section titled “評価結果を取ったあと、どう最適化するか?”正確率が低い場合
Section titled “正確率が低い場合”まず確認するのは次の点です。
- 問題の理解を間違えていないか
- ツールの選択を間違えていないか
- observation の統合を間違えていないか
正確率はまあまあでも、ステップ数が長すぎる場合
Section titled “正確率はまあまあでも、ステップ数が長すぎる場合”まず確認するのは次の点です。
- ツールを重複して呼んでいないか
- もっと早く stop できないか
- ステップをまとめられないか
ツール成功率が低い場合
Section titled “ツール成功率が低い場合”まず確認するのは次の点です。
- スキーマ が分かりやすく書かれているか
- パラメータ生成が安定しているか
- observation が十分に構造化されているか
タスクごとの成績差が大きい場合
Section titled “タスクごとの成績差が大きい場合”タスク別に分けて分析すべきです。
たとえば、
- 計算問題
- ポリシー検索問題
- 複数制約の計画問題
このように分けると、狙いを絞って最適化できます。
評価用サンプルはどう設計すべきか?
Section titled “評価用サンプルはどう設計すべきか?”簡単な問題ばかりにしない
Section titled “簡単な問題ばかりにしない”そうすると、システムがとても良く見えやすくなります。
意図的に次のような問題も入れましょう。
- 誤判定しやすい問題
- 複数ステップのツール連携が必要な問題
- 無限ループに入りやすい問題
失敗パターンをなるべくカバーする
Section titled “失敗パターンをなるべくカバーする”たとえば、
- stop すべきなのに止まらない
- ツールを使うべきでないのに乱用する
- ツール失敗後に復帰できない
固定の評価セットは長期的に保存する
Section titled “固定の評価セットは長期的に保存する”そうすると、prompt や戦略、ツールを変えるたびに、
前後比較をきちんと行えます。
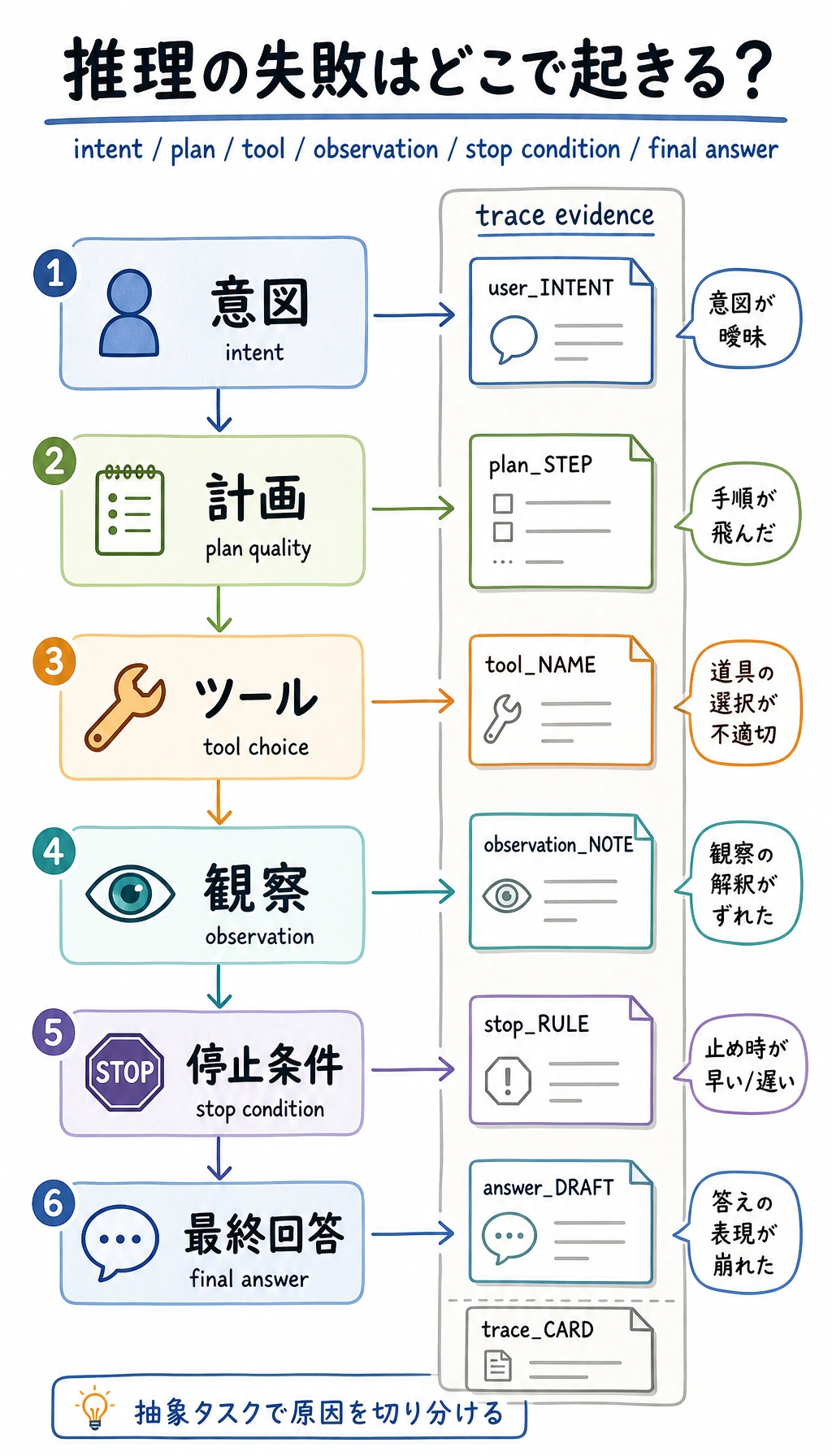
このページを終えたら、この証拠カードを残します。
- タスク目標
- Agent が解決しようとしていること
- 計画またはトレース
- 推論手順、計画、ReAct trace、または実行グラフ
- 観察
- 各アクションの後に何が変わったか
- 失敗確認
- 幻覚のステップ、古い観測、ループ、または未検証の結論
- 評価アクション
- 期待結果と比較して計画を修正する
よくある誤解
Section titled “よくある誤解”誤解1: 最終回答が正しければシステムに問題はない
Section titled “誤解1: 最終回答が正しければシステムに問題はない”そうとは限りません。
実際には、次のような問題を抱えているかもしれません。
- 過程が非常に非効率
- コストが高すぎる
- 安定性が低い
誤解2: 指標は多ければ多いほどよい
Section titled “誤解2: 指標は多ければ多いほどよい”指標は集めることが目的ではありません。
大事なのは次の2点です。
- 指標で問題を説明できるか
- 指標が最適化の指針になるか
誤解3: 固定ベンチマークがなくても、感覚で改善できる
Section titled “誤解3: 固定ベンチマークがなくても、感覚で改善できる”主観だけに頼ると、
システムをどんどん扱いにくくしてしまう危険があります。
この節で一番大切なのは、指標の名前をたくさん覚えることではありません。
評価の閉ループを作ることです。
推論システムは、最終回答、過程の品質、ツール使用、コスト効率を同時に評価し、その具体的な弱点に合わせて最適化するべきである。
この閉ループに沿って改善できるようになると、
Agent システムは「たまに動くデモ」から、「説明できて、改善できて、本番投入できるシステム」へ進化します。
- 例の
agent_bにもう1つ case を追加して、指標がどう変わるか見てみましょう。 - なぜ「最終回答の正確率」だけでは、推論 Agent を十分に評価できないのでしょうか?
- あなたのシステムが同じツールを何度も呼んでしまう場合、最初にどの層を確認しますか?
- ある Agent タスクのために、少なくとも 3 つの主要指標を設計し、それぞれに価値がある理由を説明してください。
参考実装と解説
- case を追加すると、accuracy、tool-use rate、loop count、失敗分布などが変わることがあります。どの指標が動いたのか、なぜ動いたのかを確認します。
- 最終正答率だけでは、悪い trace を見逃します。たとえば、ツールの繰り返し呼び出し、安全でない行動、引用不足、高すぎるコスト、偶然の正解などです。
- まず routing と停止ロジックを確認します。ツール説明、observation の解析、ループ終了条件、retry policy が主な確認対象です。
- 有用な指標には、タスク成功率、step count、無効なツール呼び出し率、復旧率、レイテンシとコスト、groundedness、ユーザーに見えるエラー率などがあります。