9.7.7 実践:マルチ Agent 協調システム
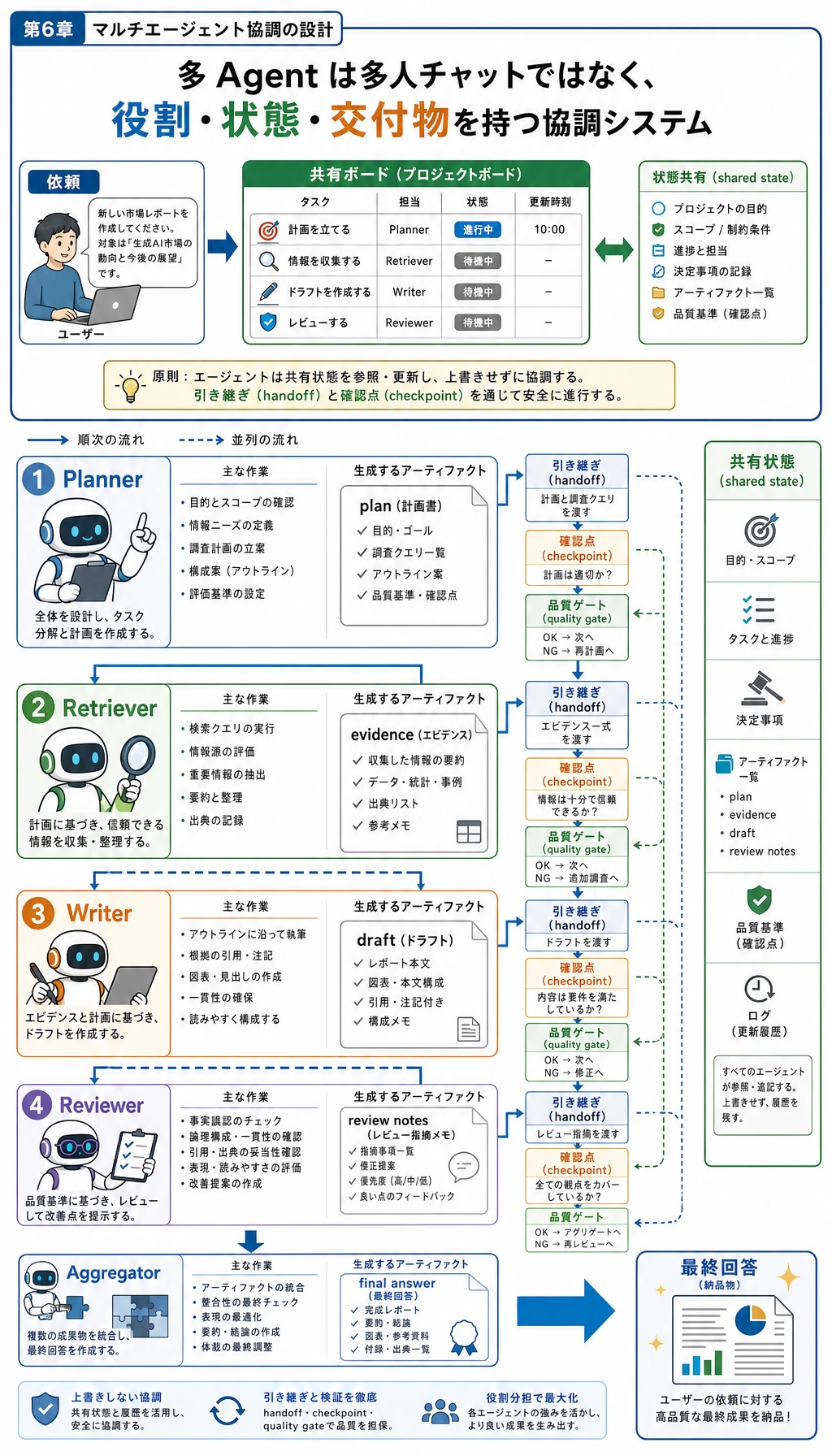
- 最小構成のマルチ Agent 協調ループを作る
- プランナー、検索担当、執筆担当、レビュー担当に役割を分けて動かす
- タスク状態が複数の役割の間でどう流れるかを理解する
- 単一 Agent システムと比べて、マルチ Agent では何が本当に増えるのかを理解する
まずプロジェクトの目的を定義する
Section titled “まずプロジェクトの目的を定義する”最小構成の研究型マルチ Agent システムを作ります。
ユーザー入力:
「返金ポリシーの重要な条件をまとめてください。」
システム内部の役割:
- プランナー:タスクを分解する
- 検索担当:資料を探す
- 執筆担当:要約を書く
- レビュー担当:結果を確認する
このタスクが向いている理由は、自然に分担しやすく、しかも各役割の責任がはっきりしているからです。
まず資料ベースを用意する
Section titled “まず資料ベースを用意する”knowledge_base = { "返金ポリシー": "コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請が可能です。", "証明書ポリシー": "すべての必修項目を完了し、テストに合格すると修了証を取得できます。", "学習順序": "まず Python、データ分析、機械学習を学び、その後に深層学習と大規模モデルの段階に進むのがおすすめです。"}
print(knowledge_base)想定出力:
{'返金ポリシー': 'コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請が可能です。', '証明書ポリシー': 'すべての必修項目を完了し、テストに合格すると修了証を取得できます。', '学習順序': 'まず Python、データ分析、機械学習を学び、その後に深層学習と大規模モデルの段階に進むのがおすすめです。'}これが、このシステムが扱う最小限の知識ソースです。
4つの Agent を定義する
Section titled “4つの Agent を定義する”def planner_agent(user_query): if "返金" in user_query: return ["返金ポリシーを検索する", "重要条件を整理する", "要約を作成する", "出力をレビューする"] return ["関連資料を検索する", "要約を作成する", "出力をレビューする"]def retriever_agent(task): if "返金ポリシー" in task: return knowledge_base["返金ポリシー"] return "資料が見つかりませんでした"def writer_agent(evidence): return f"要約:{evidence}"レビュー担当
Section titled “レビュー担当”def reviewer_agent(draft): if "7 日以内" in draft and "20%" in draft: return {"approved": True, "comment": "重要情報がそろっています"} return {"approved": False, "comment": "重要な条件が不足しています"}それらをつなぎ合わせる
Section titled “それらをつなぎ合わせる”最小構成のマルチ Agent 協調フロー
Section titled “最小構成のマルチ Agent 協調フロー”上の知識ベースと 4 つの Agent 関数を定義したあと、同じ Python ファイルまたは同じインタプリタセッションで続けて実行してください。
def multi_agent_system(user_query): state = { "query": user_query, "plan": [], "evidence": None, "draft": None, "review": None }
# 1. 企画 state["plan"] = planner_agent(user_query)
# 2. 検索 state["evidence"] = retriever_agent(state["plan"][0])
# 3. 執筆 state["draft"] = writer_agent(state["evidence"])
# 4. レビュー state["review"] = reviewer_agent(state["draft"])
return state
result = multi_agent_system("返金ポリシーの重要な条件をまとめてください。")for k, v in result.items(): print(k, "->", v)想定出力:
query -> 返金ポリシーの重要な条件をまとめてください。plan -> ['返金ポリシーを検索する', '重要条件を整理する', '要約を作成する', '出力をレビューする']evidence -> コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請が可能です。draft -> 要約:コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請が可能です。review -> {'approved': True, 'comment': '重要情報がそろっています'}
このコードから分かることは?
Section titled “このコードから分かることは?”このコードから分かるのは、次の点です。
- マルチ Agent は、ただ関数が複数あるだけではない
- 重要なのは状態の流れ
- 各役割は、自分の担当部分だけを処理する
これが、本当に最小構成のマルチ Agent システムです。
システムを実際のワークフローに近づける
Section titled “システムを実際のワークフローに近づける”レビュー担当が承認しなかったらどうする?
Section titled “レビュー担当が承認しなかったらどうする?”実際のシステムでは、review に通らなかったら、そのまま終了することはあまりありません。
より自然なやり方は次のとおりです。
- レビューコメントを執筆担当に戻す
- もう一度修正する
修正版を作る小さな例
Section titled “修正版を作る小さな例”同じファイルまたは同じセッションで続けて実行し、multi_agent_system と前の Agent 関数が定義済みであることを確認してください。
def reviser_agent(draft, review): if review["approved"]: return draft return draft + " 補足: 返金には学習進捗が 20% 未満であることも必要です。"
state = multi_agent_system("返金ポリシーの重要な条件をまとめてください。")final_output = reviser_agent(state["draft"], state["review"])
print("draft :", state["draft"])print("review:", state["review"])print("final :", final_output)想定出力:
draft : 要約:コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請が可能です。review: {'approved': True, 'comment': '重要情報がそろっています'}final : 要約:コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請が可能です。このステップが大切なのは、次のことを表しているからです。
マルチ Agent システムの価値は、分担だけでなく、役割同士で反復できる閉ループを作れることにあります。
より明確なタスクログを加える
Section titled “より明確なタスクログを加える”どうしてプロジェクトに トレース が必要なのか?
Section titled “どうしてプロジェクトに トレース が必要なのか?”もしシステムが間違えたら、少なくとも次のことが分かる必要があります。
- プランナーがどう分解したか
- 検索担当が何を見つけたか
- 執筆担当が何を書いたか
- レビュー担当がなぜ止めなかったか
最小構成の トレース 版
Section titled “最小構成の トレース 版”同じファイルまたは同じセッションで続けて実行し、4 つの Agent 関数が定義済みであることを確認してください。
def traced_multi_agent_system(user_query): trace = []
plan = planner_agent(user_query) trace.append({"agent": "planner", "output": plan})
evidence = retriever_agent(plan[0]) trace.append({"agent": "retriever", "output": evidence})
draft = writer_agent(evidence) trace.append({"agent": "writer", "output": draft})
review = reviewer_agent(draft) trace.append({"agent": "reviewer", "output": review})
return trace
for step in traced_multi_agent_system("返金ポリシーの重要な条件をまとめてください。"): print(step)想定出力:
{'agent': 'planner', 'output': ['返金ポリシーを検索する', '重要条件を整理する', '要約を作成する', '出力をレビューする']}{'agent': 'retriever', 'output': 'コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請が可能です。'}{'agent': 'writer', 'output': '要約:コース購入後 7 日以内、かつ学習進捗が 20% 未満であれば返金申請が可能です。'}{'agent': 'reviewer', 'output': {'approved': True, 'comment': '重要情報がそろっています'}}この trace は、後でデバッグしたり評価したりするときの重要な土台になります。
なぜこのシステムは単一 Agent より学ぶ価値があるのか?
Section titled “なぜこのシステムは単一 Agent より学ぶ価値があるのか?”問題を分けて考えられるから
Section titled “問題を分けて考えられるから”単一 Agent だと、たいてい一気に次のことをやります。
- タスクを理解する
- 検索する
- 要約する
- 自分で確認する
一方、マルチ Agent ではこれらを分けるので、次のことがしやすくなります。
- 各段階を観察する
- 途中の1段階だけ差し替える
- どの段階で失敗したかを見つける
ただし、コストも複雑さも増える
Section titled “ただし、コストも複雑さも増える”だから、本当に大事なエンジニアリング判断は次です。
マルチ Agent は、常により高度というわけではない
ではなく、
このタスクは、「分解しやすい」「制御しやすい」という利点のために、追加の複雑さを払う価値があるか
です。
このプロジェクトをどう発展させるか?
Section titled “このプロジェクトをどう発展させるか?”さらに次の要素を追加できます。
- より実践的な検索担当
- 複数タスクのルーティング
- 非同期通信
- 競合解決の仕組み
- 失敗時の再試行
ここまで拡張すると、実際のマルチ Agent 製品システムにかなり近づきます。
初学者がよくやるミス
Section titled “初学者がよくやるミス”すべての役割をほぼ同じにしてしまう
Section titled “すべての役割をほぼ同じにしてしまう”これでは最後に「名前が違うだけの同じ Agent が複数ある」だけになります。
共有状態や トレース がない
Section titled “共有状態や トレース がない”一度エラーが起きると、原因を追いにくくなります。
見た目はにぎやかでも、実際には役割分担ができていない
Section titled “見た目はにぎやかでも、実際には役割分担ができていない”これは多くのマルチ Agent デモでよくある問題です。
このページを終えたら、この証拠カードを残します。
- 役割
- 所有者、作業者、レビュー担当、または専門担当の責務
- メッセージ契約
- artifact、request、response、handoff 状態
- 調整
- ルーティング、タスク分割、衝突解決、最終責任者
- 失敗確認
- 重複作業、文脈喪失、責任者不在、またはメッセージループ
- 評価アクション
- マルチ Agent の結果を単一 Agent のベースラインと比較する
この節で最も大事なのは、4つの関数を書くことではなく、次を理解することです。
マルチ Agent プロジェクトの核心は、各役割が状態の流れに沿って異なる責任を持ち、最終的に説明可能で、反復可能なワークフローへ収束することです。
これこそが、マルチ Agent が単一 Agent より本当に価値を持つ点です。
- このシステムに
fact_checker_agentを追加して、数値条件を専用に確認してください。 planner_agentが「証明書ポリシー」に対しても異なる計画を出せるようにしてください。- 考えてみましょう:レビュー担当がずっと承認しない場合、システムは修正の回数をどう制限すべきでしょうか?
- 自分の言葉で説明してください。なぜ「マルチ Agent プロジェクトで本当に重要なのは役割数ではなく、状態の流れだ」と言えるのでしょうか?
プロジェクト参考とレビュー観点
fact_checker_agentは draft と抽出された numeric claims を受け取り、各 claim を source evidence と照合し、pass/fail status と修正が必要な正確な claim を返します。- “certificate policy” では、planner は汎用 plan をそのまま使わず、policy retrieval、eligibility extraction、conflict checking、draft answer、reviewer verification を含む plan を作るべきです。
- revision round には上限を置きます。たとえば review-revise を 2 回までにします。それでも失敗する場合は止め、未解決 issue を報告し、人間の input を求めます。無限 loop にしてはいけません。
- state transition が重要なのは、project が各 stage で system state を制御された形で変えることで成功するからです。plan created、evidence collected、draft written、facts checked、review passed、final delivered という流れです。