4.2.1 確率ロードマップ:AI に不確実性の言語を与える
確率と統計は、モデルがなぜ信頼度を出すのか、データがなぜ揺れるのか、そして学習がなぜ正解/不正解だけでなく loss を使うのかを説明します。
まずマップを見る
Section titled “まずマップを見る”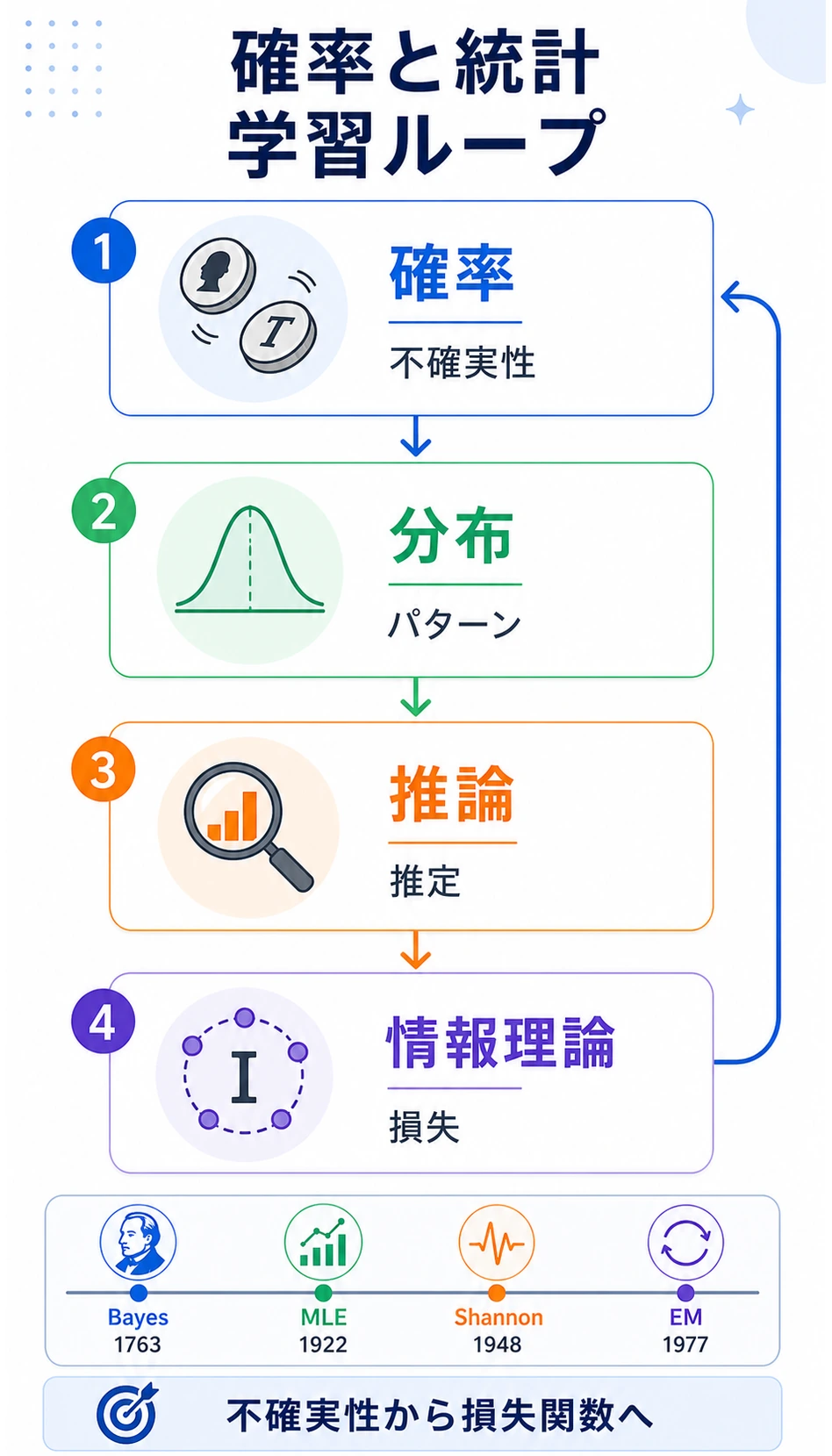
この小章の流れです。

| 用語 | 最初に問うこと |
|---|---|
| 確率 | この事象はどれくらい起きそうか |
| 分布 | 多くのランダムな結果はどんな形になるか |
| 推論 | データを見た後、何を結論できるか |
| エントロピー | 結果はどれくらい不確かか |
| 交差エントロピー | 予測確率分布はどれくらい外れているか |
| KL ダイバージェンス | 2つの分布はどれくらい違うか |
最小ループを動かす
Section titled “最小ループを動かす”probability_first_loop.py を作ります。Python 標準ライブラリだけを使います。
import math
labels = [1, 0, 1, 1]predicted_probs = [0.9, 0.2, 0.6, 0.8]
losses = []for y, p in zip(labels, predicted_probs): loss = -(y * math.log(p) + (1 - y) * math.log(1 - p)) losses.append(loss)
cross_entropy = sum(losses) / len(losses)print("cross_entropy:", round(cross_entropy, 3))print("predicted_probs:", predicted_probs)出力:
cross_entropy: 0.266predicted_probs: [0.9, 0.2, 0.6, 0.8]交差エントロピーが低いほど、予測確率がラベルに近いということです。ここで確率とモデル学習が直接つながります。
このページを終えたら、この evidence card を残します。
- 確率過程
- 事象、分布、サンプル、尤度、エントロピー、またはベイズ更新
- シミュレーションまたは式
- 不確実性を可視化するために使ったコードまたは式
- 出力
- probability、sample statistic、interval、entropy、または更新された信念
- 失敗確認
- ベースレートの混同、p値の誤用、サンプルバイアス、または確率と確実性の混同
- 期待される成果
- 数値結果と平易な言葉での解釈
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | まず見ること |
|---|---|---|
| 1 | 4.2.2 確率基礎 | 事象、条件付き確率、ベイズ更新 |
| 2 | 4.2.3 確率分布 | ベルヌーイ、二項、正規分布 |
| 3 | 4.2.4 統計的推論 | MLE、MAP、信頼度、A/B テスト |
| 4 | 4.2.5 情報理論 | エントロピー、交差エントロピー、KL ダイバージェンス |
| 5 | 4.2.6 歴史的基礎 | Bayes、Fisher、Shannon、EM の位置づけ |
確率用語がどんな不確実性を測っているかを説明でき、分類器の 0.93 が有用でも絶対的な真実ではないと説明できれば合格です。
確認の考え方と解説
- 確率ルートを通過できる目安は、単一の事象から繰り返しサンプルによる推定へ進み、さらに条件つき更新まで説明できることです。
- 証拠として、シミュレーション、分布図、MLE/MAP 推定、エントロピーまたはクロスエントロピー計算を 1 つずつ残します。
- 大事な習慣は、事前確率、独立性、サンプルサイズ、帰無仮説、予測確率などの仮定を明記することです。