6.2.7 学習ループ
- 完全な PyTorch 学習ループを書ける。
model.train()、model.eval()、torch.no_grad()、device 移動を正しく使える。- サンプル数で平均した train / validation loss を計算できる。
- メモリ上に best validation checkpoint を保持できる。
- 学習後に予測を実行できる。
まずループの構造を見る
Section titled “まずループの構造を見る”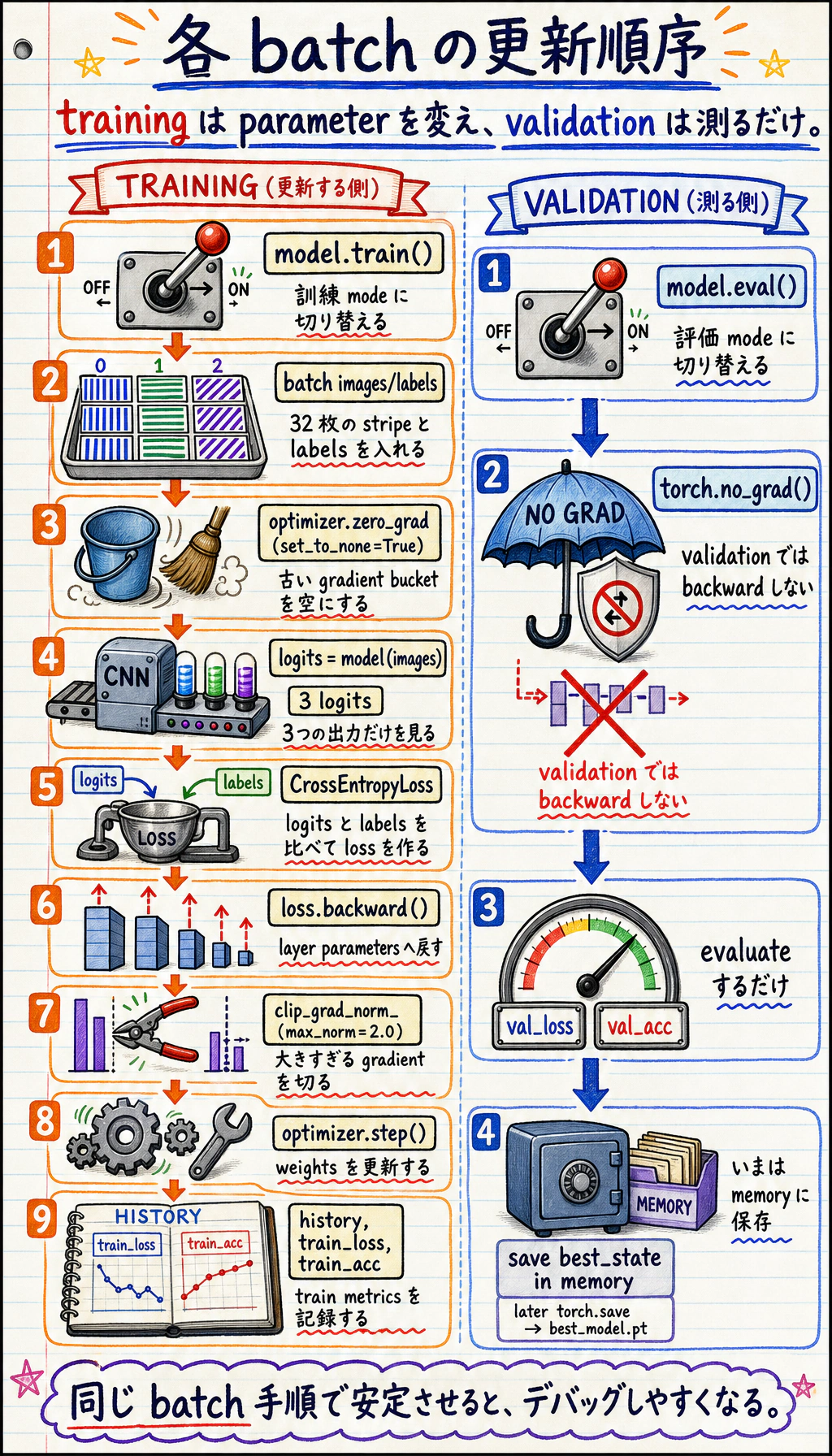
学習のリズムは次です。
検証のリズムは違います。
なぜ学習ループが重要なのか
Section titled “なぜ学習ループが重要なのか”sklearn.fit() は学習過程の多くを隠します。PyTorch がそれを見せるのは、深層学習プロジェクトではカスタムモデル、カスタム loss、カスタム batch ロジック、GPU 制御、ログ、checkpoint が必要になるからです。
同じ骨格は次のような場面に出てきます。
- 画像分類
- テキスト分類
- 物体検出
- fine-tuning
- RAG reranker の学習
- マルチモーダルモデル
アーキテクチャは変わっても、このループは見分けられます。
完全に実行できる学習スクリプト
Section titled “完全に実行できる学習スクリプト”このスクリプトは、合成データで小さな回帰モデルを学習します。
y ~= 3*x1 + 2*x2 + 5device 処理、train / validation 分割、平均 loss、best checkpoint、最後の予測まで含めています。
import copy
import torchfrom torch import nnfrom torch.utils.data import DataLoader, TensorDataset, random_split
torch.manual_seed(42)
# 1. すぐ実行できる小さな合成データセットを作るX = torch.randn(240, 2)noise = torch.randn(240, 1) * 0.3y = 3 * X[:, [0]] + 2 * X[:, [1]] + 5 + noise
dataset = TensorDataset(X, y)train_dataset, val_dataset = random_split( dataset, [192, 48], generator=torch.Generator().manual_seed(42),)
train_loader = DataLoader( train_dataset, batch_size=32, shuffle=True, generator=torch.Generator().manual_seed(7),)val_loader = DataLoader(val_dataset, batch_size=48, shuffle=False)
# 2. device を選ぶif torch.cuda.is_available(): device = torch.device("cuda")elif torch.backends.mps.is_available(): device = torch.device("mps")else: device = torch.device("cpu")
class Regressor(nn.Module): def __init__(self): super().__init__() self.net = nn.Sequential( nn.Linear(2, 16), nn.ReLU(), nn.Linear(16, 1), )
def forward(self, x): return self.net(x)
model = Regressor().to(device)loss_fn = nn.MSELoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.03)
def run_epoch(loader, train): if train: model.train() else: model.eval()
total_loss = 0.0 context = torch.enable_grad() if train else torch.no_grad()
with context: for batch_x, batch_y in loader: batch_x = batch_x.to(device) batch_y = batch_y.to(device)
pred = model(batch_x) loss = loss_fn(pred, batch_y)
if train: optimizer.zero_grad() loss.backward() optimizer.step()
total_loss += loss.item() * len(batch_x)
return total_loss / len(loader.dataset)
best_val = float("inf")best_state = None
print("training_loop_lab")for epoch in range(1, 81): train_loss = run_epoch(train_loader, train=True) val_loss = run_epoch(val_loader, train=False)
if val_loss < best_val: best_val = val_loss best_state = copy.deepcopy(model.state_dict())
if epoch == 1 or epoch % 20 == 0: print( f"epoch={epoch:3d} " f"train_loss={train_loss:.4f} " f"val_loss={val_loss:.4f}" )
model.load_state_dict(best_state)model.eval()
test_x = torch.tensor([[1.0, 2.0], [-1.0, 0.5], [0.0, 0.0]], device=device)with torch.no_grad(): preds = model(test_x).cpu()
print("best_val:", round(best_val, 4))print("predictions:")for row, pred in zip(test_x.cpu(), preds): print(f"x={row.tolist()} -> pred={pred.item():.2f}")期待される出力:
training_loop_labepoch= 1 train_loss=34.8472 val_loss=25.3358epoch= 20 train_loss=0.1022 val_loss=0.0856epoch= 40 train_loss=0.0950 val_loss=0.0776epoch= 60 train_loss=0.0972 val_loss=0.0760epoch= 80 train_loss=0.0936 val_loss=0.0776best_val: 0.0734predictions:x=[1.0, 2.0] -> pred=12.05x=[-1.0, 0.5] -> pred=3.00x=[0.0, 0.0] -> pred=4.98
ノイズなしの真の値は 12、3、5 なので、予測はかなり近いです。
出力をどう読むか
Section titled “出力をどう読むか”スクリプトが終わったかどうかだけを見ないでください。出力を証拠として読みます。
| 出力 | 何を証明するか | 何を証明しないか |
|---|---|---|
train_loss が下がる | モデルが訓練データに合っている | モデルが汎化する |
val_loss が下がる | 学習したパターンが検証サンプルにも効いている | その分割が現実世界を代表している |
best_val が復元される | 最終予測が検証で最良の checkpoint を使っている | 最後の epoch が最良だった |
予測が 12、3、5 に近い | 合成ルールを学べた | 同じモデルが乱れた実データにも効く |
講義ノートやポートフォリオでは、小さな証拠パックを残します。
- タスク
- synthetic regression
- データ
- 240 サンプル、2 特徴、target ~= 3*x1 + 2*x2 + 5
- 最良検証値
- 0.0734
- 予測確認
- [12.05, 3.00, 4.98] は [12, 3, 5] に近い
- 次に試すこと
- ノイズを1.0まで増やして validation loss を比較する
この習慣は後でも効きます。fine-tuning、RAG 評価、Agent 評価はすべて同じ型です。実行し、測り、証拠を保存し、1 つだけ変え、もう一度比較する。
ステップごとの分解
Section titled “ステップごとの分解”| ステップ | コード | なぜ必要か |
|---|---|---|
| device | model.to(device), batch_x.to(device) | モデルとデータは同じ device にある必要がある |
| モード | model.train() / model.eval() | Dropout と BatchNorm はモードで挙動が変わる |
| 順伝播 | pred = model(batch_x) | 現在のパラメータで予測する |
| loss | loss_fn(pred, batch_y) | 誤差を測る |
| クリア | optimizer.zero_grad() | 古い累積勾配を消す |
| 逆伝播 | loss.backward() | 勾配を計算する |
| 更新 | optimizer.step() | パラメータを変える |
| 検証 | torch.no_grad() | 勾配を記録せず評価する |
| checkpoint | copy.deepcopy(model.state_dict()) | 変化し続ける参照ではなく、best weight を保持する |
copy.deepcopy は重要です。best_state = model.state_dict() と直接書くと、後で変化し続ける tensor への参照を持つことがあります。
なぜサンプル数で loss を平均するのか
Section titled “なぜサンプル数で loss を平均するのか”各 batch の loss.item() は、その batch 内の平均です。最後の batch が小さいと、batch loss を単純平均すると少し偏ることがあります。
そのためスクリプトでは次の形にしています。
total_loss += loss.item() * len(batch_x)average_loss = total_loss / len(loader.dataset)これでデータセット全体に対するサンプル平均 loss になります。
よくある変種
Section titled “よくある変種”| タスク | 出力 | よく使う loss |
|---|---|---|
| 回帰 | [batch, 1] | nn.MSELoss() または nn.L1Loss() |
| 多クラス分類 | [batch, classes] logits | nn.CrossEntropyLoss() |
| 二値分類 | [batch, 1] logits | nn.BCEWithLogitsLoss() |
分類では loss に加えて指標も見ます。
- accuracy
- 不均衡データでは precision / recall / F1
- クラスが混同されやすい場合は confusion matrix
デバッグチェックリスト
Section titled “デバッグチェックリスト”学習の挙動がおかしいときは、この順で確認します。
- 1 batch の shape:
batch_xは最初の層に合うか? - ラベル shape と dtype:
batch_yは loss 関数に合うか? - Device:モデルとデータは同じ device にあるか?
- Loss:有限値か、
nan/infか? - 勾配:重要なパラメータに
Noneではない勾配があるか? - 更新:
optimizer.step()後にパラメータは本当に変わったか? - 検証:
model.eval()とtorch.no_grad()を使ったか?
便利な小さなプローブ:
print(batch_x.shape, batch_y.shape)print(batch_x.device, next(model.parameters()).device)print("loss:", loss.item())for name, param in model.named_parameters(): if param.grad is not None: print(name, param.grad.norm().item()) break保存して使える骨格
Section titled “保存して使える骨格”for epoch in range(num_epochs): model.train() for batch_x, batch_y in train_loader: batch_x = batch_x.to(device) batch_y = batch_y.to(device)
pred = model(batch_x) loss = loss_fn(pred, batch_y)
optimizer.zero_grad() loss.backward() optimizer.step()
model.eval() with torch.no_grad(): for batch_x, batch_y in val_loader: batch_x = batch_x.to(device) batch_y = batch_y.to(device) pred = model(batch_x) val_loss = loss_fn(pred, batch_y)- optimizer を
AdamからSGD(lr=0.05)に変えてください。収束はどう変わりますか? - 隠れ層サイズを
16から4と32に変え、train loss と validation loss を比べてください。 - noise を
0.3から1.0に変えてください。best validation loss はどうなりますか? best_epoch変数を追加し、どの epoch が best validation loss を出したか表示してください。y > 5でラベルを作って二値分類タスクに変え、BCEWithLogitsLossを使ってください。
参考実装と解説
- SGD は Adam より learning rate に敏感で、この小さな例では収束が遅くなりやすいです。曲線が荒い場合は、モデルを変える前に learning rate を下げてみます。
- 隠れ層サイズ
4は underfit しやすく、32は training loss を下げやすいです。最終判断では training loss だけでなく validation loss を優先します。 - noise が大きいほど避けられない誤差が増え、best validation loss は悪化しやすくなります。曲線もより揺れることがあります。
- validation loss が改善したときだけ
best_epochを更新します。表示された epoch が、保存すべき checkpoint の位置です。 - 二値分類では、各サンプルに 1 つの logit、または
[batch, 1]出力を使い、ラベルを float にして raw logits をBCEWithLogitsLossに渡します。
- 学習ループは、予測、誤差計測、勾配計算、更新、検証の閉じたサイクルです。
- 学習と検証では別のモードを使います。
zero_grad -> backward -> stepが中心の更新順序です。- batch サイズが異なる場合は、サンプル数で loss を平均します。
- コピーした
state_dictで best checkpoint を保持し、予測前に復元します。