3.5.1 データベースロードマップ:1つのファイルを越えて残る表
この節は第3章の選択内容です。実際のプロジェクトで、データが CSV や DataFrame になる前にどこへ置かれるのかを知りたいときに読みます。
まずデータベースマップを見る
Section titled “まずデータベースマップを見る”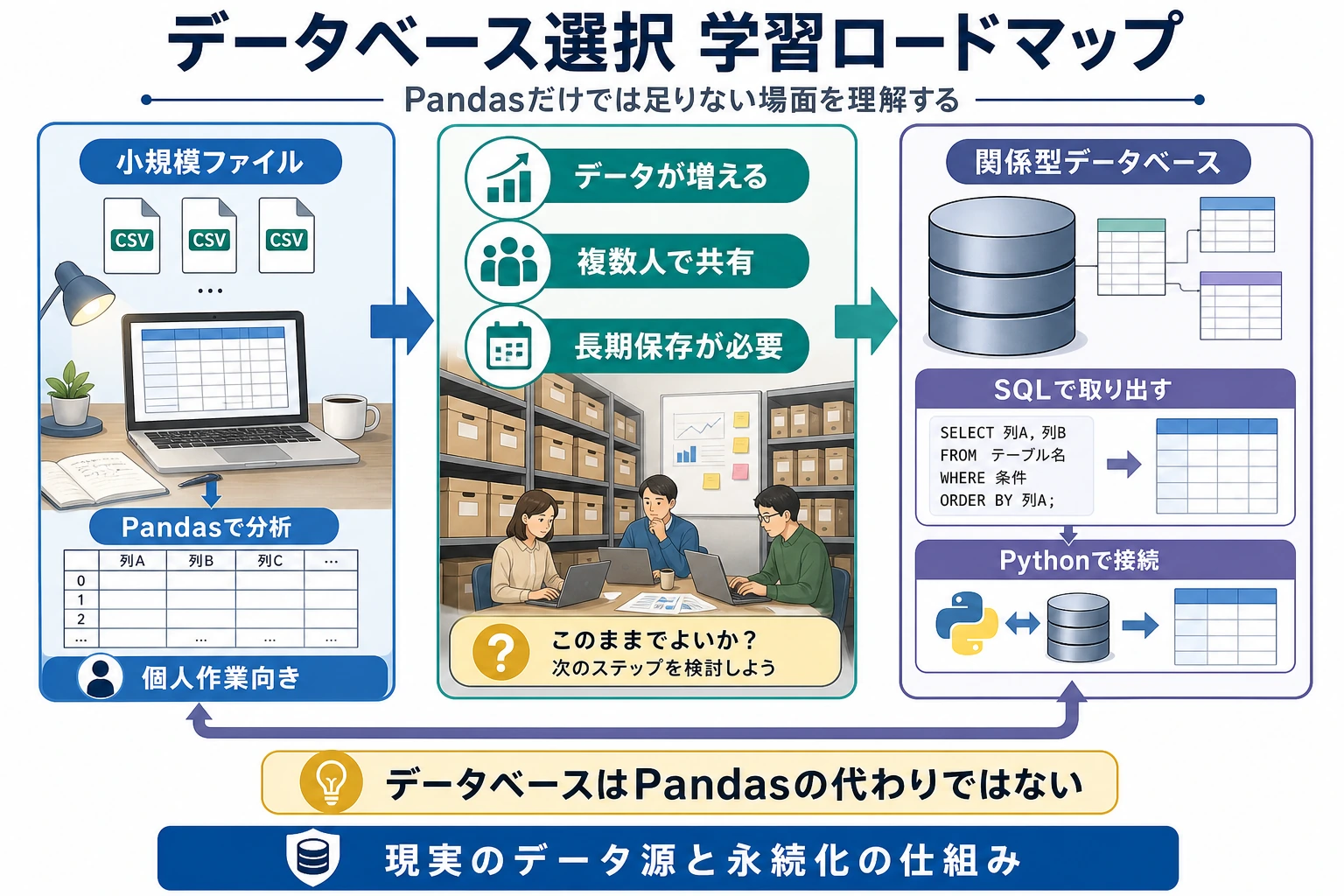
まずこの比較を覚えます。
| CSV または DataFrame | データベース |
|---|---|
| 1回のローカル分析に向く | 長期的な共有データに向く |
| 移動しやすい | クエリ、権限、更新に向く |
| たいてい1ファイルまたは1表 | 関連する複数テーブルになりやすい |
ここで DBA になる必要はありません。データを問い合わせ、Python へつなげられれば十分です。
SQLite クエリを一度動かす
Section titled “SQLite クエリを一度動かす”sqlite_first_loop.py を作ります。Python 付属の sqlite3 を使います。
import sqlite3
conn = sqlite3.connect(":memory:")conn.execute("CREATE TABLE orders (category TEXT, amount INTEGER)")conn.executemany( "INSERT INTO orders VALUES (?, ?)", [("book", 120), ("tool", 80), ("book", 150)],)
rows = conn.execute( "SELECT category, SUM(amount) AS total FROM orders GROUP BY category ORDER BY category").fetchall()
for category, total in rows: print(category, total)出力:
book 270tool 80これはデータベースの基本ループです。テーブルを作り、行を入れ、SQL で質問し、結果表を受け取ります。
このページを終えたら、この evidence card を残します。
- スキーマ
- テーブル名、キー、関係、サンプル行
- クエリ
- 使われた SQL または Python のデータベースコード
- 出力
- result rows、row count、または保存された抽出結果
- 失敗確認
- 間違った結合キー、危険なクエリ、トランザクション不足、またはスキーマ不一致
- 期待される成果
- クエリと結果表、および1件のデータ品質メモ
この順番で学ぶ
Section titled “この順番で学ぶ”| 順番 | 読む | 練習すること |
|---|---|---|
| 1 | 3.5.2 リレーショナルデータベース基礎 | 表、行、列、主キー、外部キー |
| 2 | 3.5.3 SQL 基礎 | SELECT、WHERE、JOIN、GROUP BY |
| 3 | 3.5.4 Python データベース操作 | sqlite3、Pandas の読み書き、クエリ結果 |
| 4 | 3.5.5 データベース設計 | テーブル分割、重複削減、関係の整理 |
データベースと CSV の違いを説明し、SELECT ... GROUP BY クエリを1つ書き、Python から結果を読めれば、この選択小節は合格です。
確認の考え方と解説
- 合格レベルの答えでは、問いを先に定義し、必要な table、DataFrame、または SQL query と、再現できるクリーニング手順を示します。
- 証拠には、小さな出力例、必要に応じた図表や query 結果、そして結果を解釈する一文を残します。
- 欠損値、重複行、誤った join、集計の誤解、読みにくい可視化など、少なくとも1つのデータ品質リスクを説明できれば十分です。