9.1.4 Agent の能力レベル分け
この節を終えると、次のことができるようになります。
- 階層的な考え方で、さまざまな Agent の能力の境界を説明する
- 「答えられる」「ツールを呼び出せる」「複数ステップでタスクを完了できる」の違いを区別する
- タスクの複雑さに応じて、より適切なシステム形態を選ぶ
- 小さな例で、タスクに必要な能力レベルを判断する練習をする
なぜ Agent をレベル分けするのか?
Section titled “なぜ Agent をレベル分けするのか?”「Agent」という言葉は、盛って言われやすいから
Section titled “「Agent」という言葉は、盛って言われやすいから”中には、ただ次のことができるだけのシステムもあります。
- 1つのツールを呼び出せる
また、中には次のようなことができるシステムもあります。
- 複数ステップの計画
- 状態の保持
- 複数ツールの連携
これらを全部 Agent と呼ぶと、多くの概念が混ざってしまいます。
レベル分けの意味は、システム能力をより正直に表すこと
Section titled “レベル分けの意味は、システム能力をより正直に表すこと”これによって、次のことがわかりやすくなります。
- このシステムは、実際に何ができるのか?
- これは安定したワークフローなのか、それとも柔軟な自律エージェントなのか?
- 問題があるとしたら、どの層にあるのか?
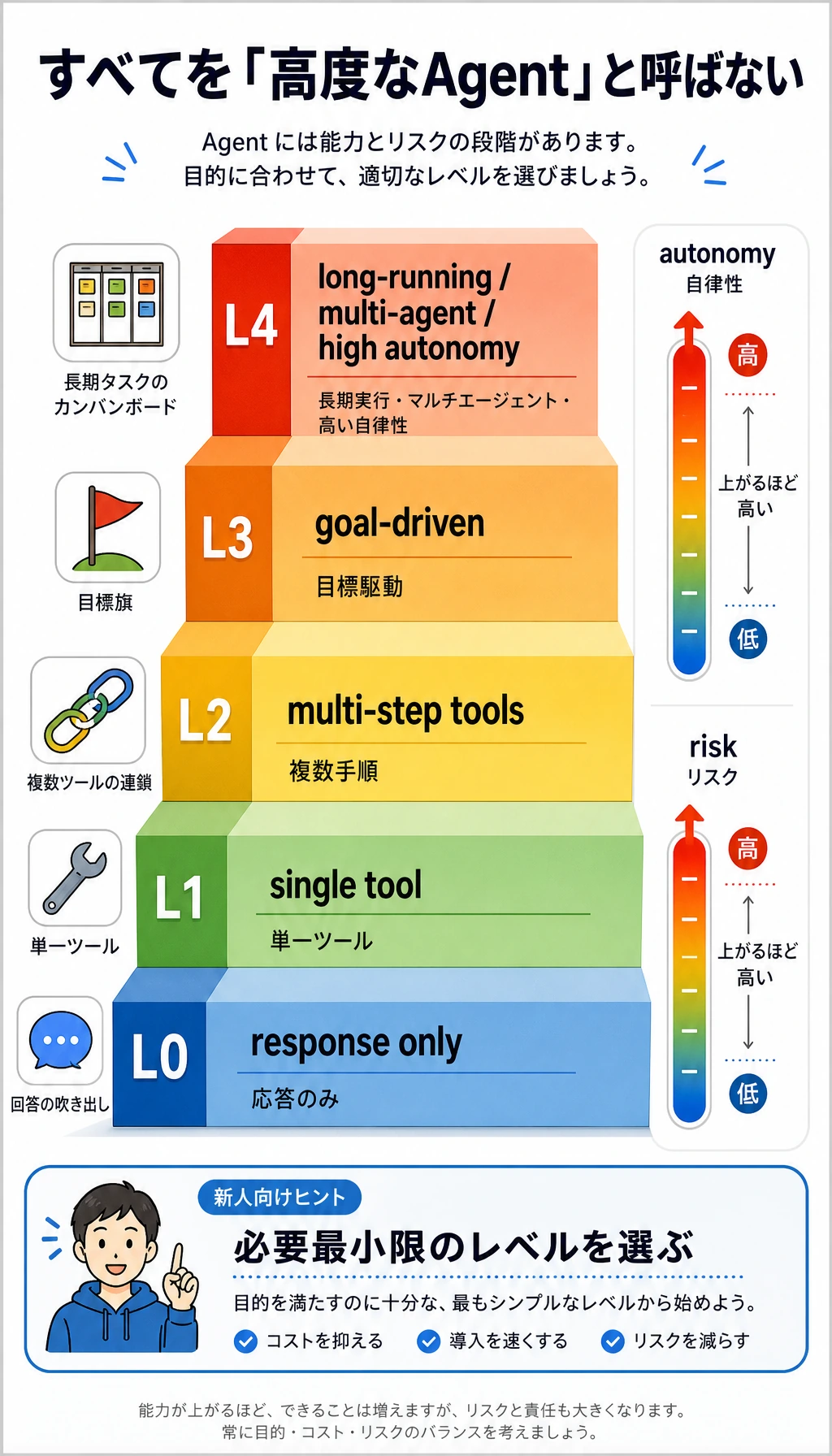
実用的な能力レベル分けのフレームワーク
Section titled “実用的な能力レベル分けのフレームワーク”L0:純粋な応答型
Section titled “L0:純粋な応答型”特徴:
- 入力に基づいて回答を生成できる
- 基本的に自分からツールを呼び出さない
- チャットモデルに近い
例:
- 普通のQAボット
- ただ Prompt を生成するだけのもの
L1:単一ツール実行型
Section titled “L1:単一ツール実行型”特徴:
- 問題に応じて1つのツールを選べる
- 1回呼び出したら、そのまま回答する
例:
- 天気確認アシスタント
- 計算機アシスタント
- 単発検索QA
さらに上のレベル
Section titled “さらに上のレベル”L2:複数ステップのツール連携型
Section titled “L2:複数ステップのツール連携型”特徴:
- 2回以上のアクションを実行できる
- 中間結果を見て、次の行動を決められる
例:
- まず注文を確認し、次に返金ポリシーを調べ、最後に結論を出す
- まず資料を検索し、それを要約してレポートにする
L3:目標駆動型
Section titled “L3:目標駆動型”特徴:
- 上位の目標を1つ受け取る
- 自分で実行フローを組み立てる
- 状態管理や失敗時の再試行を伴うことがある
例:
- 自動リサーチアシスタント
- 自動データ分析アシスタント
- 自動コード修正フロー
より高いレベルの能力は、たいていより高いリスクも意味する
Section titled “より高いレベルの能力は、たいていより高いリスクも意味する”L4:長時間実行 / マルチ Agent / 強い自律性
Section titled “L4:長時間実行 / マルチ Agent / 強い自律性”特徴:
- 長いタスクチェーンを実行できる
- 複数のツールや複数の子 Agent を呼び出せる
- 記憶、計画、振り返りの仕組みを持つ
この種のシステムは一番かっこよく聞こえますが、同時に一番エンジニアリングが難しいです。
能力が高いほど、あなたのタスクに向いているとは限らない
Section titled “能力が高いほど、あなたのタスクに向いているとは限らない”能力が上がると、たいてい次のようなものも増えます。
- コストが高くなる
- デバッグが難しくなる
- エラーの起こり方が増える
なので、正しい考え方は「高ければ高いほど良い」ではなく、次のようになります。
ちょうど十分なレベルを使う。
能力レベルの速見表
Section titled “能力レベルの速見表”| レベル | コア能力 | 代表的なシステム |
|---|---|---|
| L0 | 純粋な応答 | チャットQA |
| L1 | 単一ツール呼び出し | 天気 / 計算 / 単発検索 |
| L2 | 複数ステップ実行 | 先に調べてから計算、先に検索してから書く |
| L3 | 目標駆動 | リサーチアシスタント、データ分析アシスタント |
| L4 | 長時間自律 / マルチ Agent | 複雑な自動化チームシステム |
小さな練習:タスクをレベル分けしてみる
Section titled “小さな練習:タスクをレベル分けしてみる”実行可能な例
Section titled “実行可能な例”tasks = [ "回答:RAG とは何ですか?", "北京の天気を調べて", "まず返金ポリシーを調べて、それから条件を満たすか判断して", "売上データに基づいて週報を自動生成してメールで送る"]
def recommend_level(task): if "まず" in task and "それから" in task: return "L2" if "自動生成" in task or "メール" in task: return "L3" if "調べて" in task: return "L1" return "L0"
for task in tasks: print(task, "-> 推奨能力レベル:", recommend_level(task))期待される出力:
回答:RAG とは何ですか? -> 推奨能力レベル: L0北京の天気を調べて -> 推奨能力レベル: L1まず返金ポリシーを調べて、それから条件を満たすか判断して -> 推奨能力レベル: L2売上データに基づいて週報を自動生成してメールで送る -> 推奨能力レベル: L3もちろん、これは簡略版です。ただし、次のようなとても実用的な習慣を身につける助けになります。
まず、そのタスクにどの能力レベルが必要かを判断してから、システムの作り方を決める。
低いレベルからどう上げるのか?
Section titled “低いレベルからどう上げるのか?”L0 から L1 へ
Section titled “L0 から L1 へ”重要なのは、次を追加することです。
- ツール API
- パラメータ生成
- ツール結果の反映
L1 から L2 へ
Section titled “L1 から L2 へ”重要なのは、次を追加することです。
- 中間状態
- 複数ステップ実行
- アクション同士の依存関係
L2 から L3 へ
Section titled “L2 から L3 へ”重要なのは、次を追加することです。
- タスク分解
- サブゴール管理
- エラー復旧
上に行くほど、「小さなオペレーティングシステム」を作っているようなものになります。
エンジニアリングで「能力を盛りすぎる」のを避けるには?
Section titled “エンジニアリングで「能力を盛りすぎる」のを避けるには?”まずシステムの境界を決める
Section titled “まずシステムの境界を決める”例えば、次のようにします。
- 最大で何ステップ実行するか
- 最大でいくつのツールを呼ぶか
- どのタスクは人間の確認が必要か
まず最小限の能力でリリースする
Section titled “まず最小限の能力でリリースする”多くのシステムは、最初は実際には次のどちらかだけで十分です。
- L1 または L2
最初から L4 を目指すと、たいてい次のようになりがちです。
- 複雑すぎる
- 高すぎる
- 安定しない
初心者がよくやる誤解
Section titled “初心者がよくやる誤解”ツールを呼べるなら、高度な Agent だと思ってしまう
Section titled “ツールを呼べるなら、高度な Agent だと思ってしまう”1つのツールを呼べる程度なら、通常はせいぜい L1 です。
ステップが多いほど賢いと思ってしまう
Section titled “ステップが多いほど賢いと思ってしまう”ステップが増えても、ただエラー経路が増えるだけのことがあります。
タスクレベルを分けずに、やみくもにアーキテクチャを積み上げる
Section titled “タスクレベルを分けずに、やみくもにアーキテクチャを積み上げる”これは、多くの Agent プロジェクトが実運用に乗りにくい理由の1つです。
このページを終えたら、この証拠カードを残します。
- エージェント境界
- これが chatbot や固定ワークフローとどう違うか
- 目標/状態/行動
- 目標、現在の状態、次の行動、観測
- アーキテクチャ要素
- planner、tools、memory、guardrails、evaluator
- 失敗確認
- 自律性が高すぎる、あいまいな目標、状態不足、または trace がない
- 次の行動
- 追跡可能な最小の single-agent ループを構築する
この節で最も重要なのは、次の認識です。
Agent の能力はスイッチではなく、連続的なレベル帯である。
レベル分けを理解すると、より堅実にアーキテクチャを判断できるようになり、「完全自動の知的エージェント」という言い方に引っ張られにくくなります。
- 自分で5つのタスクを挙げ、それぞれ L0、L1、L2、L3 のどれが適切か判断してみましょう。
- あなたの実際のプロジェクトについて、なぜ L3 / L4 まで上げなくてもよいのかを考えてみましょう。
- あるシステムがよく間違ったツールを呼び出すとしたら、それはどの能力レベルの問題に近いでしょうか?
プロジェクト参考とレビュー観点
- 例:FAQ の一致判定は L0、天気検索は L1、ポリシー検索を含む返金可否判断は L2、週報を作ってメール送信する処理は L3、長時間の自律運用はリスクと監督の強さによって L3 または L4 です。
- 多くのプロジェクトは L3 / L4 まで必要ありません。自律性が上がるほど、コスト、リスク、評価負荷、復旧の複雑さも増えるからです。より単純な L1 / L2 の方が信頼できる場合もあります。
- 間違ったツール呼び出しは、たいてい tool use / routing 層の問題です。タスク分類、ツール説明、schema 制約、observation の扱いを確認します。