7.2.4 大規模モデル産業の構造

この節を終えると、あなたは次のことができるようになります。
- 産業チェーンの視点から大規模モデルのエコシステムを理解する
- モデル層、プラットフォーム層、アプリケーション層がそれぞれ何をしているかを区別する
- オープンソースとクローズドソースの違う強みを理解する
- 小さな例でモデル選定の考え方を練習する
一、まず産業チェーンを分けて見てみよう
Section titled “一、まず産業チェーンを分けて見てみよう”モデル層:誰が「エンジン」を作っているのか?
Section titled “モデル層:誰が「エンジン」を作っているのか?”モデル層は、主に基盤モデルと汎用モデルの学習を担当します。
これは「エンジンを作る人」と考えるとわかりやすいです。
この層で主に重視されるのは次のような点です。
- モデルアーキテクチャ
- 学習データ
- 学習計算資源
- モデル性能
一般的な形としては、次のようなものがあります。
- クローズドソースの API モデル
- オープンソースでダウンロード可能なモデル
- 業界特化モデル
プラットフォーム層:誰がモデルを使いやすくしているのか?
Section titled “プラットフォーム層:誰がモデルを使いやすくしているのか?”プラットフォーム層は、「道を整備し、電気を供給する人」のような役割です。
ここでよく行われることには次のようなものがあります。
- モデルホスティング
- 推論サービス
- ベクトルデータベース
- 監視と評価
- 微調整プラットフォーム
- Agent / ワークフロー開発フレームワーク
プラットフォーム層がなければ、多くのチームはモデルを手に入れても、安定して実運用に乗せるのが難しくなります。
初学者向け用語メモ:プラットフォーム層でよく出る言葉
Section titled “初学者向け用語メモ:プラットフォーム層でよく出る言葉”| 用語 | 意味 | なぜ重要か |
|---|---|---|
| API | モデルやサービスを呼び出すための標準インターフェース | アプリがモデル内部を管理せずに結果を取得できる |
| 推論 | モデルを実行して出力を得ること | ユーザーが質問するたびに、裏側でよく行われる処理 |
| ベクトルデータベース | embedding を保存し、近いものを検索しやすくしたデータベース | RAG システムの検索層としてよく使われる |
| 監視 | 遅延、エラー、コスト、出力品質を継続的に見ること | 本番環境で問題を早く見つけるために必要 |
| 評価 | 出力がタスク要件を満たしているか測ること | 感覚だけでモデルの良し悪しを判断しないために必要 |
二、アプリケーション層:本当にユーザーの近くにある
Section titled “二、アプリケーション層:本当にユーザーの近くにある”アプリケーション層が売っているのはモデルではなく、結果
Section titled “アプリケーション層が売っているのはモデルではなく、結果”アプリケーション層は「レストランを開く人」に近いです。
ユーザーは、どの注意機構を使っているかはあまり気にしません。気にするのは次のような点です。
- 仕事をちゃんと手伝ってくれるか
- 回答が信頼できるか
- 十分に速いか
- コストを受け入れられるか
代表的なアプリケーションには次のようなものがあります。
- AI 検索
- AI カスタマーサポート
- AI プログラミングアシスタント
- AI オフィスツール
- AI 学習支援アシスタント
同じモデルでも、いろいろな製品に変わる
Section titled “同じモデルでも、いろいろな製品に変わる”同じ基盤モデルでも、チームが違えばまったく別の製品になることがあります。
- 法務アシスタント
- 営業アシスタント
- 教育支援アシスタント
- コードレビューツール
これは、産業競争が「モデルがどれだけ大きいか」だけで起きているわけではなく、次のような点でも起きていることを示しています。
- ワークフロー設計
- データ蓄積
- 製品体験
- 業界知識
三、オープンソース路線とクローズドソース路線、どう選ぶ?
Section titled “三、オープンソース路線とクローズドソース路線、どう選ぶ?”クローズドソースモデルは「すぐ使える成熟したエンジン」に近い
Section titled “クローズドソースモデルは「すぐ使える成熟したエンジン」に近い”メリットは一般的に次の通りです。
- すぐに使ってよい効果が出やすい
- モデルの保守作業が少ない
- リリースまでが速い
代わりに、デメリットとしては次のような点があります。
- 利用ごとに課金される
- 制御しにくい
- プライベート環境への導入が制限される
オープンソースモデルは「自分で改造できるエンジン」に近い
Section titled “オープンソースモデルは「自分で改造できるエンジン」に近い”メリットは一般的に次の通りです。
- 自分でデプロイできる
- 微調整できる
- データと推論の流れをより細かく管理できる
代わりに、デメリットとしては次のような点があります。
- デプロイと保守がより複雑
- そのままで必ずしも最強の性能ではない
- より高いエンジニアリング力が必要
一言で覚えるなら、
クローズドソースは手軽さ重視、オープンソースは制御性重視。
四、多くのチームが本当に競っているのは「システム能力」
Section titled “四、多くのチームが本当に競っているのは「システム能力」”モデルはシステムの中の一部にすぎない
Section titled “モデルはシステムの中の一部にすぎない”実際の大規模モデル製品は、多くの場合「モデルだけが頑張る」のではなく、システム全体で協力しています。
- Prompt
- RAG
- ツール呼び出し
- 評価体系
- 安全対策
- コスト管理
つまり、次のように考えられます。
ユーザー体験 = モデル性能 × システム設計 × データ品質
なぜ同じモデルでも、製品によって体験が大きく違うのか?
Section titled “なぜ同じモデルでも、製品によって体験が大きく違うのか?”体験を左右するのは、モデル性能だけではないからです。たとえば次のような要素も重要です。
- ナレッジベースが良いか
- ツールが正確に動くか
- 失敗時のフォールバックがあるか
- レイテンシーがうまく抑えられているか
これが、「API を使える」ことと「AI 製品を作れる」ことは同じではない理由です。
五、実践的なモデル選定フレームワーク
Section titled “五、実践的なモデル選定フレームワーク”まず「誰が最強か」ではなく、「何が必要か」を考える
Section titled “まず「誰が最強か」ではなく、「何が必要か」を考える”よく使う選定の観点には次のようなものがあります。
| 観点 | 確認したいこと |
|---|---|
| 品質 | タスクの結果は十分に良いか? |
| コスト | 1回あたりの呼び出し料金は高くないか? |
| レイテンシー | ユーザーは応答速度を受け入れられるか? |
| 制御性 | プライベート導入、微調整、監査はできるか? |
| マルチモーダル | 画像や音声を見る必要があるか? |
| ツール能力 | 関数呼び出し / agent が必要か? |
小さなスコアリングスクリプト
Section titled “小さなスコアリングスクリプト”次の例は、実在する最新モデルを選ぶためのものではなく、「要件に合わせてどう評価するか」を練習するためのものです。
models = { "cloud_api_model": { "quality": 9, "cost": 4, "latency": 8, "control": 4 }, "open_source_8b": { "quality": 6, "cost": 9, "latency": 7, "control": 9 }, "open_source_70b": { "quality": 8, "cost": 5, "latency": 5, "control": 9 }}
weights = { "quality": 0.4, "cost": 0.2, "latency": 0.2, "control": 0.2}
def score_model(info, weights): return sum(info[k] * weights[k] for k in weights)
scores = []for name, info in models.items(): scores.append((score_model(info, weights), name))
for score, name in sorted(scores, reverse=True): print(name, "->", round(score, 2))期待される出力:
open_source_8b -> 7.4open_source_70b -> 7.0cloud_api_model -> 6.8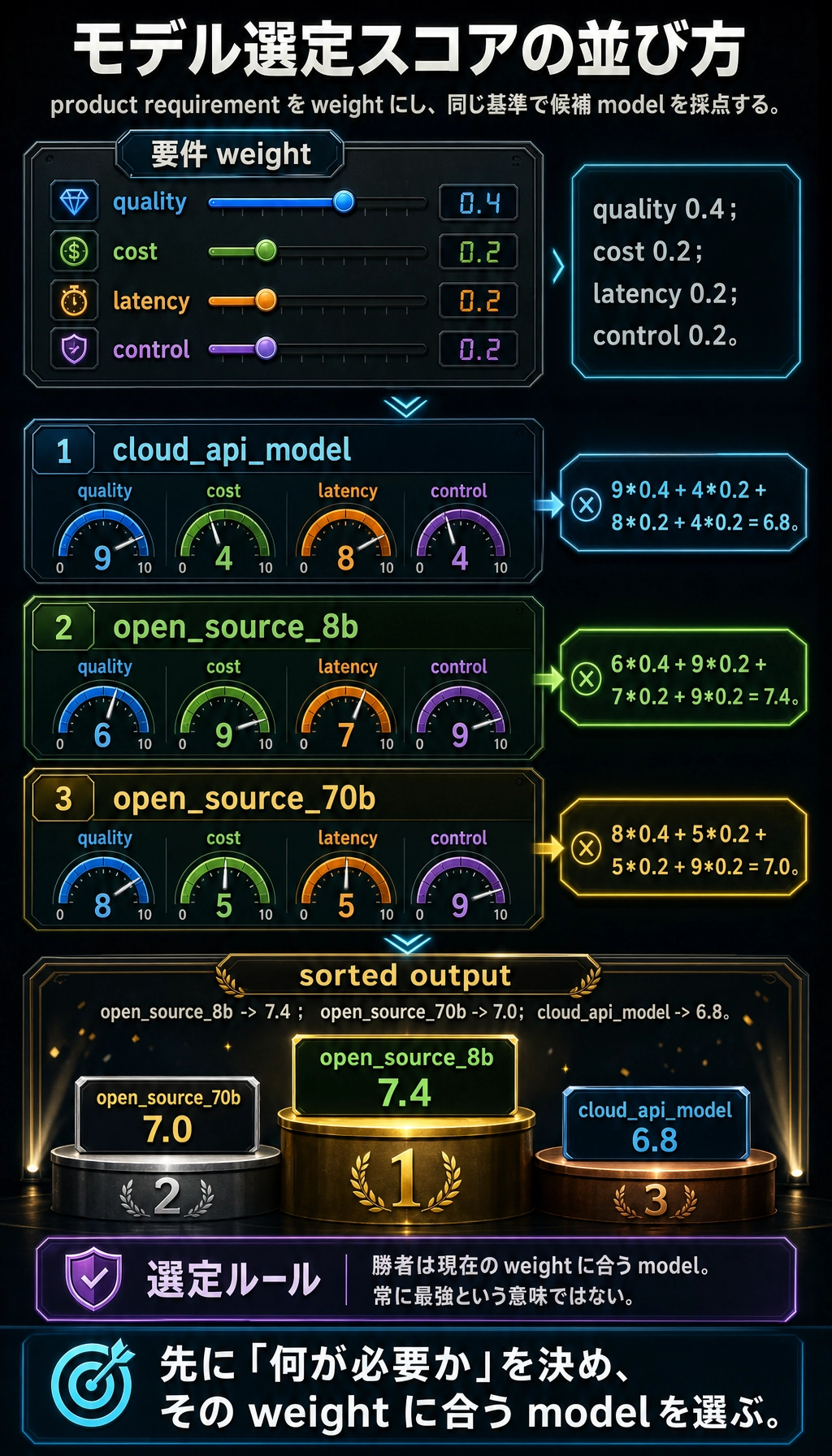
weights を変えることで、会社ごとの重視点の違いを再現できます。
六、なぜ「産業構造」がエンジニアにも重要なのか?
Section titled “六、なぜ「産業構造」がエンジニアにも重要なのか?”毎日、技術選定をしているから
Section titled “毎日、技術選定をしているから”あなたは次のような問題に何度も出会うことになります。
- API を使うか、自前でデプロイするか?
- まず RAG を作るか、先に微調整するか?
- 汎用モデルを使うか、垂直特化モデルを使うか?
- 単一モデルにするか、複数モデルのルーティングにするか?
これらの問題は、根本的にはすべて産業構造と関係しています。
技術路線はキャリアパスにも影響するから
Section titled “技術路線はキャリアパスにも影響するから”職種によって、重視する能力は少しずつ違います。
- 基盤モデル:学習とアルゴリズム寄り
- プラットフォームエンジニアリング:推論、デプロイ、最適化寄り
- アプリケーションエンジニアリング:プロダクト、ワークフロー、評価寄り
産業構造を知ることで、自分がどの分野に進みたいかをよりはっきり考えられます。
七、初学者がよくする誤解
Section titled “七、初学者がよくする誤解”ランキングだけを見る
Section titled “ランキングだけを見る”ランキングには価値がありますが、それだけがすべてではありません。
実際のプロジェクトでは、コスト、レイテンシー、安定性も同じくらい重要です。
「オープンソースなら必ず安い」と思う
Section titled “「オープンソースなら必ず安い」と思う”モデル自体がオープンソースでも、学習、デプロイ、保守まで安いとは限りません。
「最良のモデル」が常にあると思う
Section titled “「最良のモデル」が常にあると思う”多くの場合、「絶対に最良のモデル」はありません。あるのは「今の場面に最も合うモデル」だけです。
このページを終えたら、この証拠カードを残します。
- モデル選択
- closed、open、hosted、または self-deployed の選択肢
- 判断要素
- 品質、レイテンシー、プライバシー、コスト、エコシステム
- システム能力
- model + data + product + eval + ops
- リスク注意
- ベンダーロックイン、コンプライアンス、またはデプロイ制約
- 証拠
- 実際のユースケース向けのモデル選定表1つ
この節で最も大切な理解は次の通りです。
大規模モデル産業は、モデルのパラメータ数だけで競っているのではなく、モデル、プラットフォーム、データ、製品、エンジニアリング能力の組み合わせで競っている。
アプリケーションを作る人が産業構造を理解するのは、流行を追うためではなく、より安定した技術的・製品的判断をするためです。
- スコアリングスクリプトの重みを変更して、「スタートアップチーム」と「金融企業」の選定傾向をそれぞれ再現してみましょう。
- 考えてみましょう:もしあなたのプロジェクトがプライベートデプロイを必要とするなら、オープンソース路線とクローズドソース路線の優先順位はどう変わるでしょうか?
- 自分の言葉で説明してみましょう:なぜ多くの場合、真の競争優位はモデル本体だけではないのでしょうか?
プロジェクト参考とレビュー観点
- startup team は speed、cost、API simplicity、iteration velocity を高く重みづけしがちです。financial enterprise は privacy、compliance、auditability、reliability、vendor control を高く見るべきです。
- private deployment が必要なら、open-weight model、self-hosting、private cloud、data governance の優先度が上がります。closed-source API も、隔離と compliance を満たすなら選択肢です。
- 優位性は proprietary data、workflow integration、evaluation loop、user trust、distribution、operations から生まれることが多いです。model は重要ですが、product system の 1 層です。