3.2.5 配列の変形と操作
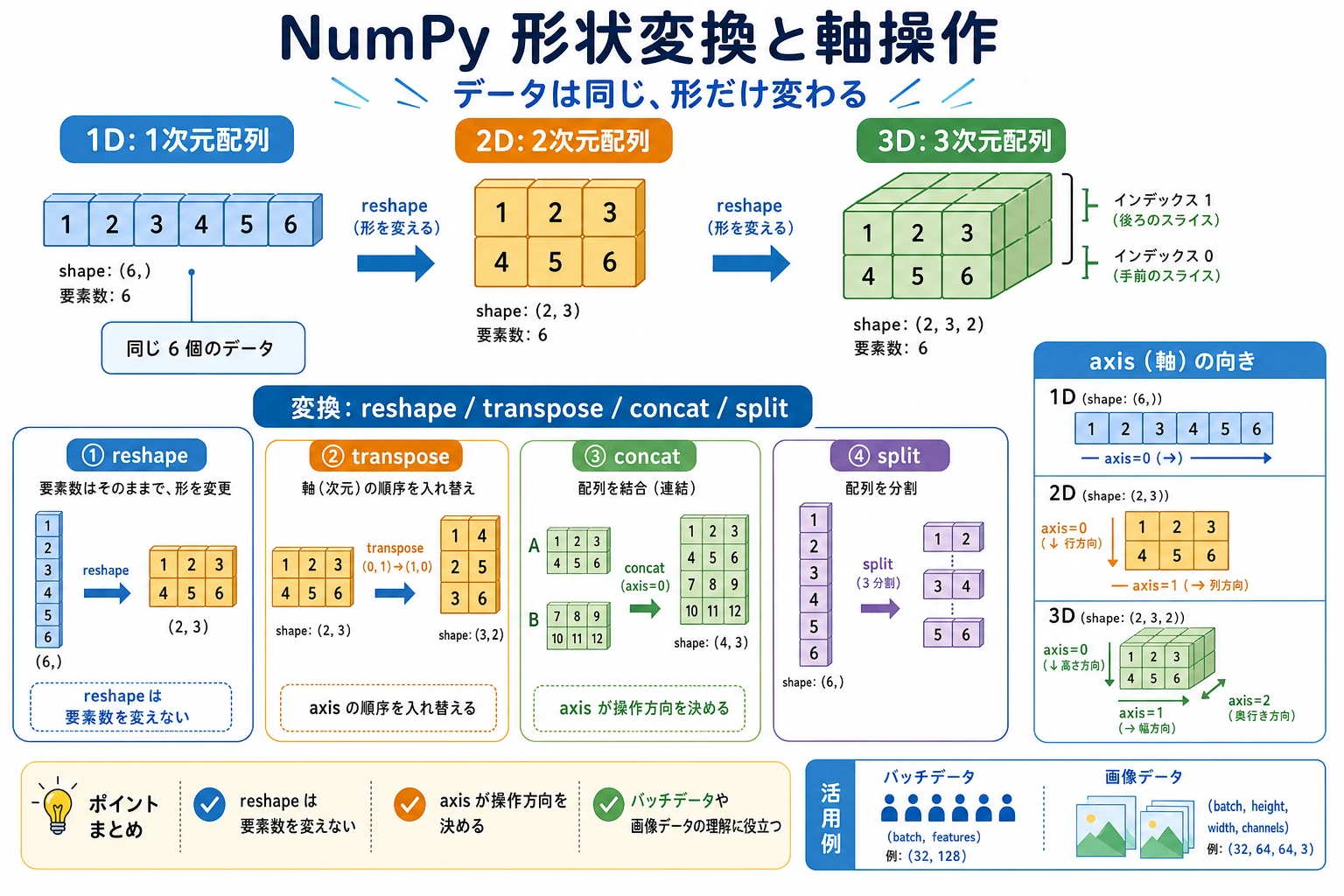
- reshape、flatten、ravel などの変形操作を身につける
- 配列の結合(concatenate、stack、hstack、vstack)を学ぶ
- 配列の分割(split、hsplit、vsplit)を学ぶ
- 転置と軸の入れ替えを理解する
reshape:形状を変える
Section titled “reshape:形状を変える”reshape は最もよく使う変形操作です。データを変えずに配列の形状だけを変えます。
基本的な使い方
Section titled “基本的な使い方”import numpy as np
arr = np.arange(12) # [ 0 1 2 3 4 5 6 7 8 9 10 11]print(arr.shape) # (12,)
# 3 行 4 列にするm1 = arr.reshape(3, 4)print(m1)# [[ 0 1 2 3]# [ 4 5 6 7]# [ 8 9 10 11]]
# 4 行 3 列にするm2 = arr.reshape(4, 3)print(m2)# [[ 0 1 2]# [ 3 4 5]# [ 6 7 8]# [ 9 10 11]]
# 2×2×3 の3次元配列にするm3 = arr.reshape(2, 2, 3)print(m3)# [[[ 0 1 2]# [ 3 4 5]]# [[ 6 7 8]# [ 9 10 11]]]-1 を使って自動計算する
Section titled “-1 を使って自動計算する”-1 は「NumPy にこの次元を自動計算してもらう」という意味です。
arr = np.arange(12)
# 3 行にしたい。列数は自動で計算してほしいm1 = arr.reshape(3, -1) # 4 列になるprint(m1.shape) # (3, 4)
# 4 列にしたい。行数は自動で計算してほしいm2 = arr.reshape(-1, 4) # 3 行になるprint(m2.shape) # (3, 4)
# 1 列にする(列ベクトル)col = arr.reshape(-1, 1)print(col.shape) # (12, 1)flatten と ravel:配列を平らにする
Section titled “flatten と ravel:配列を平らにする”多次元配列を1次元に戻します。
matrix = np.array([ [1, 2, 3], [4, 5, 6]])
# flatten:コピーを返す(変更しても元の配列に影響しない)flat = matrix.flatten()print(flat) # [1 2 3 4 5 6]flat[0] = 99print(matrix[0, 0]) # 1 ← 元の配列は変わらない
# ravel:ビューを返す(変更すると元の配列にも影響する)rav = matrix.ravel()print(rav) # [1 2 3 4 5 6]rav[0] = 99print(matrix[0, 0]) # 99 ← 元の配列も変わる!| 方法 | 戻り値の種類 | 変更が元の配列に影響するか | 速度 |
|---|---|---|---|
flatten() | コピー | しない | やや遅い(データをコピーする) |
ravel() | ビュー | する | やや速い(コピーしない) |
reshape(-1) | ビュー | する | やや速い |
concatenate:汎用的な結合
Section titled “concatenate:汎用的な結合”a = np.array([1, 2, 3])b = np.array([4, 5, 6])
# 1次元の結合c = np.concatenate([a, b])print(c) # [1 2 3 4 5 6]2次元配列を結合するときは、方向(axis)を指定します。
m1 = np.array([[1, 2], [3, 4]])m2 = np.array([[5, 6], [7, 8]])
# axis=0:上下に結合(行数が増える)v = np.concatenate([m1, m2], axis=0)print(v)# [[1 2]# [3 4]# [5 6]# [7 8]]
# axis=1:左右に結合(列数が増える)h = np.concatenate([m1, m2], axis=1)print(h)# [[1 2 5 6]# [3 4 7 8]]vstack と hstack:手軽な結合
Section titled “vstack と hstack:手軽な結合”m1 = np.array([[1, 2], [3, 4]])m2 = np.array([[5, 6], [7, 8]])
# vstack = vertical stack = 上下に結合 = concatenate(axis=0)print(np.vstack([m1, m2]))# [[1 2]# [3 4]# [5 6]# [7 8]]
# hstack = horizontal stack = 左右に結合 = concatenate(axis=1)print(np.hstack([m1, m2]))# [[1 2 5 6]# [3 4 7 8]]stack:新しい次元を作る
Section titled “stack:新しい次元を作る”stack と concatenate の違いは、stack が次元を1つ増やすことです。
a = np.array([1, 2, 3]) # shape: (3,)b = np.array([4, 5, 6]) # shape: (3,)
# stack で新しい次元に積むs0 = np.stack([a, b], axis=0) # 「横に並べる」イメージprint(s0)# [[1 2 3]# [4 5 6]]print(s0.shape) # (2, 3)
s1 = np.stack([a, b], axis=1) # 「縦に並べる」イメージprint(s1)# [[1 4]# [2 5]# [3 6]]print(s1.shape) # (3, 2)結合方法のまとめ
Section titled “結合方法のまとめ”| 関数 | 役割 | 次元の変化 |
|---|---|---|
np.concatenate() | 既存の軸に沿って結合 | 次元は変わらず、どこかの軸が長くなる |
np.vstack() | 上下に結合 | 行数が増える |
np.hstack() | 左右に結合 | 列数が増える |
np.stack() | 新しい軸に沿って積む | 次元が1つ増える |
split:均等に分割する
Section titled “split:均等に分割する”arr = np.arange(12) # [ 0 1 2 3 4 5 6 7 8 9 10 11]
# 3 つに均等分割parts = np.split(arr, 3)print(parts[0]) # [0 1 2 3]print(parts[1]) # [4 5 6 7]print(parts[2]) # [8 9 10 11]
# 指定した位置で分割parts2 = np.split(arr, [3, 7]) # インデックス 3 と 7 で切るprint(parts2[0]) # [0 1 2]print(parts2[1]) # [3 4 5 6]print(parts2[2]) # [7 8 9 10 11]2次元の分割
Section titled “2次元の分割”matrix = np.arange(16).reshape(4, 4)print(matrix)# [[ 0 1 2 3]# [ 4 5 6 7]# [ 8 9 10 11]# [12 13 14 15]]
# vsplit:上下に分割top, bottom = np.vsplit(matrix, 2)print(top)# [[0 1 2 3]# [4 5 6 7]]
# hsplit:左右に分割left, right = np.hsplit(matrix, 2)print(left)# [[ 0 1]# [ 4 5]# [ 8 9]# [12 13]]転置と軸の入れ替え
Section titled “転置と軸の入れ替え”2次元の転置
Section titled “2次元の転置”転置は、行を列に、列を行に変えることです。
matrix = np.array([ [1, 2, 3], [4, 5, 6]])print(matrix.shape) # (2, 3)
# 転置t = matrix.Tprint(t)# [[1 4]# [2 5]# [3 6]]print(t.shape) # (3, 2)
# transpose でもできるt2 = matrix.transpose()print(np.array_equal(t, t2)) # True次元を追加する:np.newaxis と expand_dims
Section titled “次元を追加する:np.newaxis と expand_dims”配列に次元を1つ追加したいことがあります。たとえば、行ベクトルを列ベクトルにしたいときです。
arr = np.array([1, 2, 3]) # shape: (3,)
row = arr[np.newaxis, :] # shape: (1, 3) 行ベクトルcol = arr[:, np.newaxis] # shape: (3, 1) 列ベクトルprint(row) # [[1 2 3]]print(col)# [[1]# [2]# [3]]
# 方法 2:np.expand_dimsrow2 = np.expand_dims(arr, axis=0) # axis=0 に次元を追加 → (1, 3)col2 = np.expand_dims(arr, axis=1) # axis=1 に次元を追加 → (3, 1)
# 方法 3:reshaperow3 = arr.reshape(1, -1) # (1, 3)col3 = arr.reshape(-1, 1) # (3, 1)次元を減らす:squeeze
Section titled “次元を減らす:squeeze”サイズが 1 の次元を取り除きます。
arr = np.array([[[1, 2, 3]]])print(arr.shape) # (1, 1, 3)
squeezed = arr.squeeze()print(squeezed.shape) # (3,)print(squeezed) # [1 2 3]実践:データの再構成
Section titled “実践:データの再構成”import numpy as np
# 例:12か月分の売上データ(1次元)monthly_sales = np.array([ 120, 135, 150, 180, 200, 210, 195, 188, 220, 250, 280, 310])
# 4 四半期 × 3 か月に再構成quarterly = monthly_sales.reshape(4, 3)print("四半期データ:")print(quarterly)# [[120 135 150] Q1# [180 200 210] Q2# [195 188 220] Q3# [250 280 310]] Q4
# 各四半期の売上合計q_totals = quarterly.sum(axis=1)quarters = ["Q1", "Q2", "Q3", "Q4"]for q, total in zip(quarters, q_totals): print(f" {q}: {total}")
# 前半と後半first_half, second_half = np.vsplit(quarterly, 2)print(f"\n前半の合計: {first_half.sum()}")print(f"後半の合計: {second_half.sum()}")このページを終えたら、この evidence card を残します。
- 配列状態
- 操作前の shape、dtype、axis、サンプル値
- 操作
- indexing、slicing、broadcasting、reshape、線形代数、またはランダム/stat関数
- 出力
- 結果の配列形状、値、または統計量
- 失敗確認
- 軸の混同、view/copy の落とし穴、ブロードキャスト不一致、または誤った形状
- 期待される成果
- 配列操作を確認できる出力形状と値
| 操作 | 関数 | 説明 |
|---|---|---|
| 形状を変える | reshape() | 要素数は変えずに、次元の並びを変える |
| 平らにする | flatten() / ravel() | 多次元を1次元にする |
| 結合する | concatenate() / vstack() / hstack() | 複数の配列をまとめる |
| 積む | stack() | まとめて、さらに1次元増やす |
| 分割する | split() / vsplit() / hsplit() | 1つの配列を複数に分ける |
| 転置する | .T / transpose() | 行と列を入れ替える |
| 次元を増やす | np.newaxis / expand_dims() | size=1 の次元を追加する |
| 次元を減らす | squeeze() | size=1 の次元を取り除く |
やってみよう
Section titled “やってみよう”練習 1:reshape の練習
Section titled “練習 1:reshape の練習”arr = np.arange(24)
# 1. 4×6 の行列にする# 2. 2×3×4 の3次元配列にする# 3. 6 行にする(列数は自動計算)# 4. (2,3,4) の配列を1次元に戻す練習 2:結合と分割
Section titled “練習 2:結合と分割”# 3 クラス分の成績データclass_a = np.array([[85, 90], [78, 82], [92, 88]]) # 3 人 × 2 科目class_b = np.array([[76, 80], [95, 91], [83, 87]]) # 3 人 × 2 科目class_c = np.array([[88, 92], [71, 75], [90, 85]]) # 3 人 × 2 科目
# 1. 3 クラスの成績を 9×2 の行列にまとめる# 2. 3 科目目の点数を追加したいとき、どう結合する?extra_scores = np.array([[70], [65], [80], [75], [90], [85], [78], [72], [88]])# 3. まとめた 9×3 の行列を、3 人ずつに分割して 3 グループに戻す練習 3:データの再構成
Section titled “練習 3:データの再構成”# 1年365日の気温データ(ダミーデータ)rng = np.random.default_rng(seed=42)daily_temps = rng.uniform(low=-5, high=38, size=360) # 分割しやすいように360日を使う
# 1. 12 か月 × 30 日に再構成する# 2. 各月の平均気温を計算する# 3. 最も暑い月と最も寒い月を見つける# 4. 前半と後半の平均気温の差を計算する参考実装と解説
- 同じ 24 個の値は、要素数が 24 のままであれば
(4, 6)、(2, 3, 4)、(6, -1)に変形できます。-1は NumPy に推定させるため、1 つの次元だけに使います。 - クラス別スコアでは、
np.vstackが縦方向の結合、np.hstackが列方向の追加、行数がそろう場合はnp.splitで同じ大きさのブロックに戻せます。 - 日別気温データは、各月 30 件なら
(12, 30)に reshape し、axis=1で月平均、argmaxやargminで最も暑い月や寒い月を探します。